CW+ Premium Content/E-Handbooks
-

E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -

E-Handbook
Removing barriers to tech careers
Download -

E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -

E-Handbook
Collaboration vital for making DEI progress
Download



-

E-Handbook
The pros & cons of AI in cybersecurity
Download -

E-Handbook
The future of API management: Key trends for IT leaders
Download -
E-Handbook
CrowdStrike outage explained: What happened and what can we learn?
Download -

E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download
-

E-Handbook
Why real-time analytics is key to AI success
Download -
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -

E-Handbook
Innovation Awards APAC 2025
Download -

E-Handbook
Digital Transformation Unleashed: Smart Industries, AI & the 5G Revolution
Download
-
E-Handbook
The pros & cons of AI in cybersecurity
Download -

E-Handbook
2025 Technology Priorities in APAC
Download -
E-Handbook
The future of API management: Key trends for IT leaders
Download -

E-Handbook
Top IT predictions in APAC in 2025
Download
-
E-Handbook
Why real-time analytics is key to AI success
Download -

E-Handbook
Top tech stories of 2024: India (Part 1)
Download -

E-Handbook
A Computer Weekly buyer’s guide to IT energy reduction
Download -

E-Handbook
Beginner's guide to Internet of Things
Download
-

E-Handbook
19 machine learning interview questions and answers
Download -

E-Handbook
Top 10 ASEAN IT stories of 2022
Download -

E-Handbook
Real-time analytics extends the reach of its business value more and more
Download -

E-Handbook
Predictive analytics gains evermore accuracy in guiding enterprises forward
Download
-

E-Handbook
Infographic: Five stages of supply chain management
Download -
E-Handbook
10 metaverse use cases for IT and business leaders
Download -

E-Handbook
Executive Interview: Unleashing blockchain's potential
Download -

E-Handbook
CW Innovation Awards: Singapore Airlines' blockchain app unlocks loyalty rewards
Download



-

E-Handbook
Cyber resilience under pressure: How to demonstrate readiness
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
CrowdStrike outage explained: What happened and what can we learn?
Download -
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download
-
E-Handbook
Why real-time analytics is key to AI success
Download -
E-Handbook
Top tech stories of 2024: India (Part 1)
Download -

E-Handbook
A Computer Weekly buyer’s guide to SaaS integration
Download -

E-Handbook
Infographic: How organisations are using generative AI in EMEA
Download
-
E-Handbook
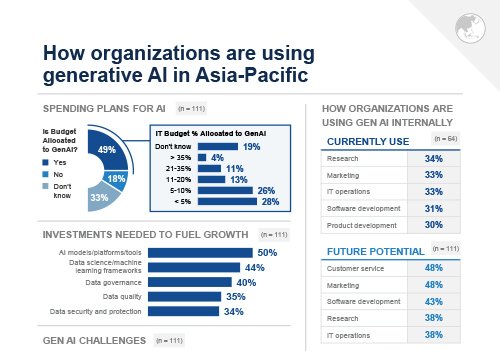
Infographic: How organizations are using generative AI in Asia-Pacific
Download -
E-Handbook
A Computer Weekly buyer’s guide to IT energy reduction
Download -
E-Handbook
Beginner's guide to Internet of Things
Download -
E-Handbook
Predictive analytics gains evermore accuracy in guiding enterprises forward
Download
-
E-Handbook
Why real-time analytics is key to AI success
Download -

E-Handbook
A Computer Weekly buyer’s guide to auditing and testing data models
Download -

E-Handbook
A Computer Weekly buyer’s guide to AI, ML and RPA
Download -

E-Handbook
Royal Holloway: Deep learning for countering energy theft
Download
-

E-Handbook
Robotic Process Automation blends into AI for thoroughly modern ERP
Download -

E-Handbook
A Computer Weekly buyer’s guide to post-Covid supply chain management
Download -

E-Handbook
A Computer Weekly buyer’s guide to SIEM and SOAR
Download -

E-Handbook
CW Innovation Awards: Flybuys cranks up cloud for service efficiency
Download
-

E-Handbook
Computer Weekly 2024 salary survey
Download -

E-Handbook
The importance of getting everyone involved in the diversity drive
Download -

E-Handbook
Ultimate guide to digital transformation for enterprise leaders
Download -
E-Handbook
A Computer Weekly buyer’s guide to SaaS integration
Download
-

E-Handbook
A Computer Weekly buyer’s guide to developer experience
Download -
E-Handbook
A Computer Weekly buyer’s guide to auditing and testing data models
Download -

E-Handbook
A Computer Weekly buyer’s guide to network cost and bandwidth optimisation
Download -

E-Handbook
A Computer Weekly buyer’s guide to secure coding
Download
-
E-Handbook
Innovation Awards APAC 2025
Download -
E-Handbook
Digital Transformation Unleashed: Smart Industries, AI & the 5G Revolution
Download -
E-Handbook
10 metaverse use cases for IT and business leaders
Download -

E-Handbook
Royal Holloway: Security evaluation of network traffic mirroring in public cloud
Download
-

E-Handbook
The growth of cloud-based networking: What to expect in 2022 and beyond
Download -

E-Handbook
A Computer Weekly buyer’s guide to training programmes and tools
Download -

E-Handbook
A Computer Weekly buyer’s guide to hybrid cloud storage
Download -

E-Handbook
IT Priorities 2022: What IT decision-makers are planning
Download
-
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download -
E-Handbook
A Computer Weekly buyer’s guide to secure coding
Download -

E-Handbook
The ultimate guide to identity & access management
Download -

E-Handbook
How do cybercriminals steal credit card information?
Download
-

E-Handbook
Top 10 ANZ IT stories of 2022
Download -

E-Handbook
Top 10 India IT stories of 2022
Download -

E-Handbook
A Computer Weekly buyer’s guide to anti-ransomware
Download -

E-Handbook
Guide to building an enterprise API strategy
Download
-
E-Handbook
A Computer Weekly buyer’s guide to training programmes and tools
Download -

E-Handbook
Hybrid cloud connectivity best practices
Download -
E-Handbook
A Computer Weekly buyer’s guide to hybrid cloud storage
Download -

E-Handbook
Managing hybrid cloud deployments: What enterprises need to know
Download
-

E-Handbook
Top 10 cloud stories of 2021
Download -

E-Handbook
What the future holds for cloud management in APAC
Download -

E-Handbook
A Computer Weekly buyer’s guide to sustainable datacentres
Download -

E-Handbook
Cloud Market Report Australia
Download
-

E-Handbook
The role of microservices in agile enterprises
Download -

E-Handbook
Datacentre design: Building leaner, greener server farms
Download -

E-Handbook
How open source is spurring digital transformation
Download -

E-Handbook
Converged infrastructure in 2021: Next-generation datacentre designs
Download
-

E-Handbook
Top 10 ASEAN IT stories of 2020
Download -

E-Handbook
Top 10 datacentre stories of 2019
Download -

E-Handbook
Infographic: 6 steps to containerised storage success
Download -

E-Handbook
Nordics are leading the datacentre revolution
Download
-
E-Handbook
2025 Technology Priorities in APAC
Download -
E-Handbook
Top IT predictions in APAC in 2025
Download -

E-Handbook
Digital Experience platforms intensify customer engagement programmes
Download -

E-Handbook
Infographic: 5 differences between call centers and contact centers
Download
-

E-Handbook
Customer service technologies emerge bloodied but unbowed from Covid-19 pandemic
Download -

E-Handbook
A Computer Weekly buyer’s guide to digital customer experience
Download -

E-Handbook
Marketing software moves closer to centre of the CIO's vision
Download -

E-Handbook
Real-time analytics possible fuel for post Covid pandemic growth
Download
-
E-Handbook
Cyber resilience under pressure: How to demonstrate readiness
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download -
E-Handbook
The ultimate guide to identity & access management
Download

-
E-Handbook
A Computer Weekly buyer’s guide to network cost and bandwidth optimisation
Download -

E-Handbook
The development of wired and wireless LANs in a hybrid work model
Download -

E-Handbook
How to achieve network infrastructure modernization
Download -

E-Handbook
A Computer Weekly buyer’s guide to communications as a service
Download
-

E-Handbook
Top 10 networking stories of 2021
Download -

E-Handbook
Infographic: Compare hybrid cloud platforms
Download -

E-Handbook
The rise of edge computing
Download -
E-Handbook
Ofcom raise over £1.3bn in new 5G spectrum auction
Download
-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
IT Priorities 2022: What IT decision-makers are planning
Download -

E-Handbook
Oracle cloud applications exhibit pragmatic adoption curve
Download -

E-Handbook
Infographic: 5 ways backup can protect against ransomware
Download
-

E-Handbook
AWS vs Azure vs Google: 5 key benefits each for cloud file storage
Download -

E-Handbook
Container technologies and trends: What enterprises need to know
Download -

E-Handbook
Kubernetes: What enterprises need to know
Download -

E-Handbook
IT Priorities 2020: Covid-19 consolidates storage push to cloud
Download
-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -

E-Handbook
Infographic: 5 considerations before buying data center backup software
Download -

E-Handbook
Data backup failure: Top 5 causes and tips for prevention Infographic
Download -

E-Handbook
Step-by-step disaster recovery planning guide
Download
-
E-Handbook
IT Priorities 2022: What IT decision-makers are planning
Download -

E-Handbook
The vulnerability of backup in a predominantly remote + cloud world
Download -
E-Handbook
A Computer Weekly buyer’s guide to sustainable datacentres
Download -
E-Handbook
Oracle cloud applications exhibit pragmatic adoption curve
Download
-
E-Handbook
Why real-time analytics is key to AI success
Download -
E-Handbook
Top IT predictions in APAC in 2025
Download -
E-Handbook
Collaboration vital for making DEI progress
Download -

E-Handbook
Fail to prepare quality data, prepare to fail
Download
-

E-Handbook
10 steps to building a data catalog
Download -

E-Handbook
Data governance for all seasons and reasons
Download -

E-Handbook
5 steps for a smooth ECM implementation
Download -

E-Handbook
The Ultimate Guide to Enterprise Content Management
Download
-
E-Handbook
Top 10 India IT stories of 2022
Download -
E-Handbook
10 steps to building a data catalog
Download -
E-Handbook
Predictive analytics gains evermore accuracy in guiding enterprises forward
Download -

E-Handbook
Business analytics needs underpinnings of sound data and data-skilled humans
Download
-

E-Handbook
Automated document management system tools transform workflows
Download -

E-Handbook
Real-time analytics expands its business value compass
Download -
E-Handbook
CW Innovation Awards: Flybuys cranks up cloud for service efficiency
Download -

E-Handbook
Executive Interview: Tapping APAC's storage potential
Download
-
E-Handbook
A Computer Weekly buyer’s guide to AI, ML and RPA
Download -
E-Handbook
Digital Experience platforms intensify customer engagement programmes
Download -
E-Handbook
Infographic: 5 differences between call centers and contact centers
Download -
E-Handbook
Executive Interview: Juergen Mueller on SAP's tech strategy
Download


-

E-Handbook
A guide to where mainframes fit in the cloud
Download -

E-Handbook
Top 10 datacentre stories of 2021
Download -

E-Handbook
A hybrid approach: How the conversation around cloud is changing
Download -
E-Handbook
A Computer Weekly buyer’s guide to sustainable datacentres
Download
-
E-Handbook
Datacentre design: Building leaner, greener server farms
Download -
E-Handbook
Infographic: Compare hybrid cloud platforms
Download -
E-Handbook
Converged infrastructure in 2021: Next-generation datacentre designs
Download -

E-Handbook
A Computer Weekly buyer’s guide to datacentre cooling
Download


-
E-Handbook
A Computer Weekly buyer’s guide to auditing and testing data models
Download -
E-Handbook
A Computer Weekly buyer’s guide to IT energy reduction
Download -

E-Handbook
A Computer Weekly buyer’s guide to data visualisation
Download -

E-Handbook
A Computer Weekly buyer’s guide to the circular economy
Download


-
E-Handbook
A Computer Weekly buyer’s guide to auditing and testing data models
Download -
E-Handbook
A Computer Weekly buyer’s guide to IT energy reduction
Download -
E-Handbook
A Computer Weekly buyer’s guide to data visualisation
Download -
E-Handbook
A guide to where mainframes fit in the cloud
Download
-
E-Handbook
2025 Technology Priorities in APAC
Download -

E-Handbook
Implementing GenAI: Use cases & challenges
Download -
E-Handbook
Data governance for all seasons and reasons
Download -
E-Handbook
How open source is spurring digital transformation
Download


-
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
Infographic: 5 considerations before buying data center backup software
Download -
E-Handbook
Data backup failure: Top 5 causes and tips for prevention Infographic
Download -
E-Handbook
Step-by-step disaster recovery planning guide
Download
-
E-Handbook
A Computer Weekly buyer’s guide to sustainable datacentres
Download -
E-Handbook
Oracle cloud applications exhibit pragmatic adoption curve
Download -

E-Handbook
Understanding Kubernetes to build a cloud-native enterprise
Download -

E-Handbook
A Computer Weekly buyer’s guide to containerisation in the enterprise
Download

-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
Removing barriers to tech careers
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
Collaboration vital for making DEI progress
Download
-
E-Handbook
Computer Weekly 2024 salary survey
Download -
E-Handbook
The importance of getting everyone involved in the diversity drive
Download -
E-Handbook
Infographic: How organisations are using generative AI in EMEA
Download -
E-Handbook
Infographic: How organizations are using generative AI in Asia-Pacific
Download
-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
Removing barriers to tech careers
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
Collaboration vital for making DEI progress
Download
-
E-Handbook
Computer Weekly 2024 salary survey
Download -
E-Handbook
The importance of getting everyone involved in the diversity drive
Download -
E-Handbook
Infographic: How organisations are using generative AI in EMEA
Download -
E-Handbook
Infographic: How organizations are using generative AI in Asia-Pacific
Download
-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
CrowdStrike outage explained: What happened and what can we learn?
Download -
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download



-
E-Handbook
The future of API management: Key trends for IT leaders
Download -

E-Handbook
10 common uses for machine learning applications in business
Download -
E-Handbook
Guide to building an enterprise API strategy
Download -
E-Handbook
Executive Interview: Unleashing blockchain's potential
Download
-

E-Handbook
CW Innovation Awards: How DBS is transforming credit processes
Download -
E-Handbook
CW Innovation Awards: DBS Bank Project of the Year Interview [Video]
Download -

E-Handbook
Getting the best out of robotic process automation
Download -

E-Handbook
A Computer Weekly buyer’s guide to next-generation retail technology
Download
-
E-Handbook
Innovation Awards APAC 2025
Download -
E-Handbook
Guide to building an enterprise API strategy
Download -
E-Handbook
The Ultimate Guide to Enterprise Content Management
Download -
E-Handbook
Infographic: 5 differences between call centers and contact centers
Download
-

E-Handbook
CW Innovation Awards: Sime Darby ups ante on service management
Download -

E-Handbook
CRM enters maturity as customer experience custodian
Download -

E-Handbook
A Computer Weekly buyer's guide to automating business processes
Download -

E-Handbook
Digital experience focus broadens to encompass employees
Download
-
E-Handbook
Cyber resilience under pressure: How to demonstrate readiness
Download -
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
Innovation Awards APAC 2025
Download
-
E-Handbook
The pros & cons of AI in cybersecurity
Download -
E-Handbook
2025 Technology Priorities in APAC
Download -
E-Handbook
The future of API management: Key trends for IT leaders
Download -
E-Handbook
Top IT predictions in APAC in 2025
Download
-
E-Handbook
Why real-time analytics is key to AI success
Download -
E-Handbook
Cyber resilience under pressure: How to demonstrate readiness
Download -

E-Handbook
Developing a storage strategy to support AI
Download -
E-Handbook
The pros & cons of AI in cybersecurity
Download
-
E-Handbook
2025 Technology Priorities in APAC
Download -
E-Handbook
The future of API management: Key trends for IT leaders
Download -
E-Handbook
Top IT predictions in APAC in 2025
Download -

E-Handbook
Top tech stories of 2024: ASEAN (Part 1)
Download
-
E-Handbook
A Computer Weekly buyer’s guide to hybrid cloud storage
Download -
E-Handbook
Oracle cloud applications exhibit pragmatic adoption curve
Download -
E-Handbook
AWS vs Azure vs Google: 5 key benefits each for cloud file storage
Download -
E-Handbook
Container technologies and trends: What enterprises need to know
Download
-

E-Handbook
IT Priorities 2021 - European Topics Infographic
Download -
E-Handbook
Kubernetes: What enterprises need to know
Download -
E-Handbook
IT Priorities 2020: Covid-19 consolidates storage push to cloud
Download -

E-Handbook
Eyes on India: New age of flash storage boosts performance & efficiency
Download
-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
2025 Technology Priorities in APAC
Download -
E-Handbook
Top IT predictions in APAC in 2025
Download

-
E-Handbook
A Computer Weekly buyer’s guide to SaaS integration
Download -

E-Handbook
A Computer Weekly buyer’s guide to green tech for business
Download -
E-Handbook
A Computer Weekly buyer’s guide to data visualisation
Download -

E-Handbook
A Computer Weekly buyer’s guide to financial analytics for planning
Download
-
E-Handbook
A Computer Weekly buyer’s guide to AI, ML and RPA
Download -

E-Handbook
A Computer Weekly buyer’s guide to customer and employee experience management
Download -
E-Handbook
A Computer Weekly buyer’s guide to training programmes and tools
Download -

E-Handbook
Ethics at the heart of emerging AI strategies
Download
-

E-Handbook
Royal Holloway: Secure multiparty computation and its application to digital asset custody
Download -
E-Handbook
CW Innovation Awards: How DBS is transforming credit processes
Download -
E-Handbook
CW Innovation Awards: DBS Bank Project of the Year Interview [Video]
Download -

E-Handbook
2021 UKI Salary Survey Analysis Video
Download
-

E-Handbook
IR35 reforms: Confusion over who pays employers' NI leaves IT contractors out of pocket
Download -

E-Handbook
Royal Holloway: Protecting investors from cyber threats
Download -

E-Handbook
Financial applications automation – promise is real but needs business nous
Download -

E-Handbook
IT Priorities 2020: Budgets rejigged to support 2021 recovery
Download
-
E-Handbook
Why real-time analytics is key to AI success
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
A Computer Weekly buyer’s guide to green tech for business
Download -
E-Handbook
10 steps to building a data catalog
Download
-
E-Handbook
Data governance for all seasons and reasons
Download -

E-Handbook
A Computer Weekly buyer’s guide to API management
Download -

E-Handbook
Royal Holloway: Information security of the 2016 Philippine automated elections
Download -

E-Handbook
India IT Priorities 2022: Top Observations & Trends
Download
-
E-Handbook
Removing barriers to tech careers
Download -
E-Handbook
Collaboration vital for making DEI progress
Download -
E-Handbook
Computer Weekly 2024 salary survey
Download -
E-Handbook
The importance of getting everyone involved in the diversity drive
Download
-
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download -
E-Handbook
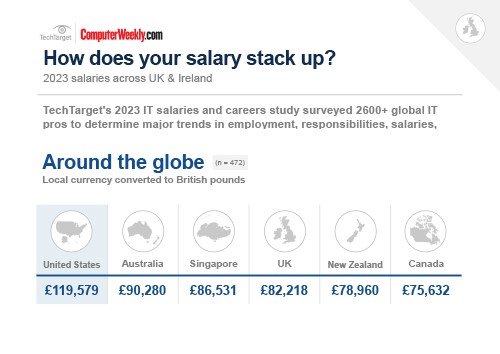
Computer Weekly/TechTarget 2023 salary survey infographic
Download -

E-Handbook
Inclusion = everyone: Expert advice for improving tech diversity
Download -
E-Handbook
19 machine learning interview questions and answers
Download
-
E-Handbook
Why real-time analytics is key to AI success
Download -
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
Collaboration vital for making DEI progress
Download
-

E-Handbook
2022 Media Consumption Study: Fact or fiction - The rep-free buying experience
Download -

E-Handbook
2022 Media Consumption Study: Push the right content to the right channel
Download -

E-Handbook
2022 UKI Media Consumption Study: Is digital fatigue overblown?
Download -

E-Handbook
2022 UKI Media Consumption Study: Transform your face-to-face event thinking
Download
-
E-Handbook
A Computer Weekly buyer’s guide to the circular economy
Download -
E-Handbook
The growth of cloud-based networking: What to expect in 2022 and beyond
Download -
E-Handbook
2021 UKI Media Consumption Infographic: Digital research preferences
Download -
E-Handbook
2021 UKI Media Consumption Infographic: Impact of the Pandemic on IT Purchasing
Download


-
E-Handbook
Removing barriers to tech careers
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
Collaboration vital for making DEI progress
Download -
E-Handbook
Computer Weekly 2024 salary survey
Download
-
E-Handbook
The importance of getting everyone involved in the diversity drive
Download -
E-Handbook
Computer Weekly/TechTarget 2023 salary survey infographic
Download -
E-Handbook
A Computer Weekly buyer’s guide to post-Covid supply chain management
Download -

E-Handbook
Stronger collaboration platforms emerge as pandemic legacy
Download
-
E-Handbook
Implementing GenAI: Use cases & challenges
Download -
E-Handbook
A Computer Weekly buyer’s guide to green tech for business
Download -

E-Handbook
A guide to what to look for in Application Performance Monitoring and Observability
Download -
E-Handbook
2022 Media Consumption Study: Fact or fiction - The rep-free buying experience
Download
-
E-Handbook
2022 Media Consumption Study: Push the right content to the right channel
Download -
E-Handbook
2022 UKI Media Consumption Study: Is digital fatigue overblown?
Download -
E-Handbook
2022 UKI Media Consumption Study: Transform your face-to-face event thinking
Download -
E-Handbook
2022 UKI Media Consumption Study: Characteristics of the Buying Team
Download

-

E-Handbook
The CISO's guide to supply chain security
Download -
E-Handbook
Cloud Market Report Australia
Download -

E-Handbook
Public cloud in India: A guide to building digital resiliency
Download -

E-Handbook
Under new cloud management: What the future holds for AWS
Download
-
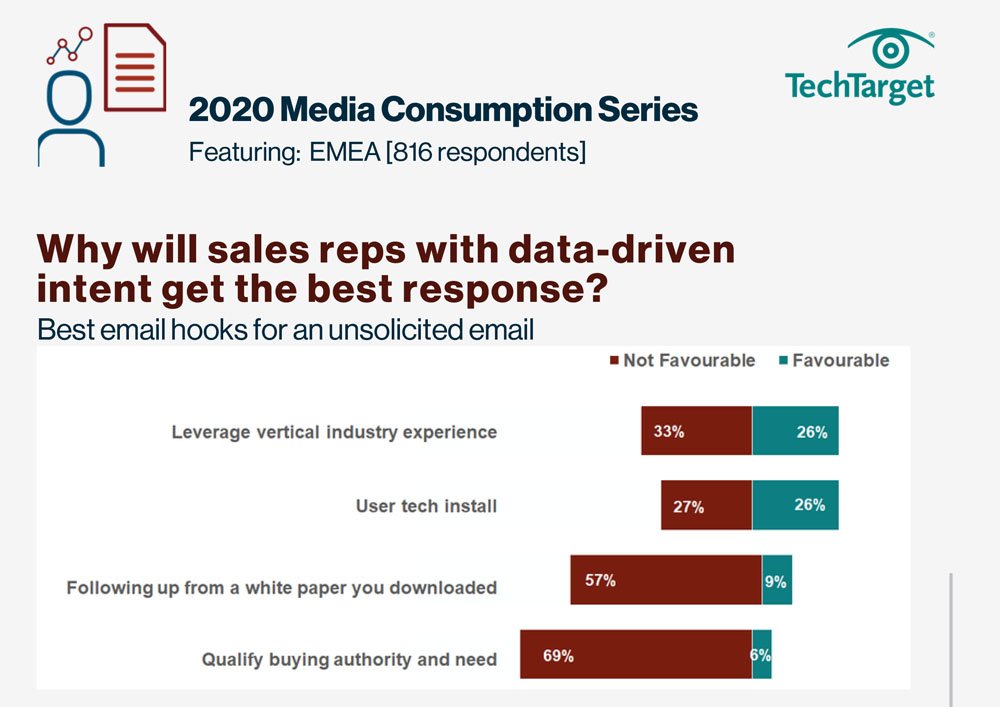
E-Handbook
2020 Media Consumption Series - Why
Download -
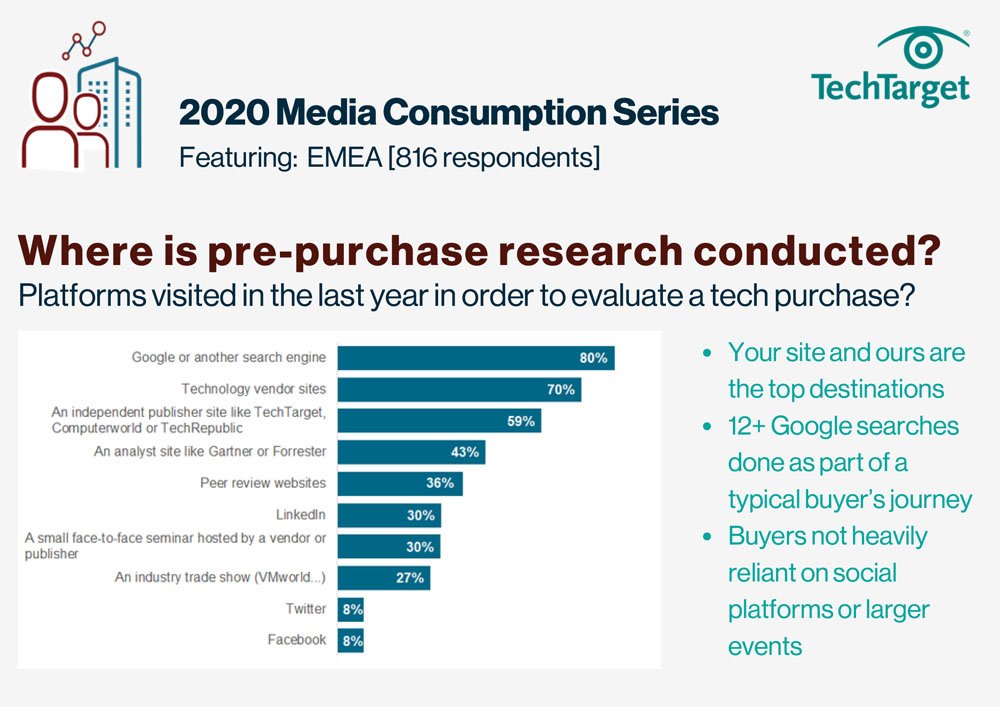
E-Handbook
2020 Media Consumption Series - Where
Download -

E-Handbook
Project Brief: Inside Juniper's radical IT transformation
Download -

E-Handbook
Inside India: The world’s IT powerhouse
Download
-
E-Handbook
2025 Technology Priorities in APAC
Download -
E-Handbook
Top IT predictions in APAC in 2025
Download -
E-Handbook
Collaboration vital for making DEI progress
Download -
E-Handbook
Top tech stories of 2024: ASEAN (Part 1)
Download
-
E-Handbook
Implementing GenAI: Use cases & challenges
Download -
E-Handbook
A Computer Weekly buyer’s guide to green tech for business
Download -
E-Handbook
A Computer Weekly buyer’s guide to financial analytics for planning
Download -

E-Handbook
The enterprise guide to video conferencing in 2023
Download
-
E-Handbook
Cyber resilience under pressure: How to demonstrate readiness
Download -
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
The pros & cons of AI in cybersecurity
Download
-
E-Handbook
Implementing GenAI: Use cases & challenges
Download -
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download -
E-Handbook
Infographic: How organisations are using generative AI in EMEA
Download -
E-Handbook
Infographic: How organizations are using generative AI in Asia-Pacific
Download
-

E-Handbook
Risk management is the beating heart of your cyber strategy
Download -
E-Handbook
Step-by-step disaster recovery planning guide
Download -
E-Handbook
Shields up! Why Russia’s war on Ukraine should matter to security pros
Download -

E-Handbook
Ransomware: The situation at the beginning of 2022 Infographic
Download



-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
2025 Technology Priorities in APAC
Download -
E-Handbook
Top IT predictions in APAC in 2025
Download
-
E-Handbook
Removing barriers to tech careers
Download -
E-Handbook
Collaboration vital for making DEI progress
Download -
E-Handbook
Computer Weekly 2024 salary survey
Download -
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download
-
E-Handbook
Computer Weekly/TechTarget 2023 salary survey infographic
Download -

E-Handbook
A Computer Weekly buyer’s guide to automation and autonomous control
Download -
E-Handbook
19 machine learning interview questions and answers
Download -

E-Handbook
APAC career guide: Becoming a cyber security pro
Download
-
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
The pros & cons of AI in cybersecurity
Download -
E-Handbook
CrowdStrike outage explained: What happened and what can we learn?
Download -
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download

-
E-Handbook
2025 Technology Priorities in APAC
Download -
E-Handbook
Top tech stories of 2024: ASEAN (Part 1)
Download -
E-Handbook
Infographic: How organizations are using generative AI in Asia-Pacific
Download -
E-Handbook
Top 10 ASEAN IT stories of 2022
Download
-
E-Handbook
Royal Holloway: Information security of the 2016 Philippine automated elections
Download -
E-Handbook
The CISO's guide to supply chain security
Download -
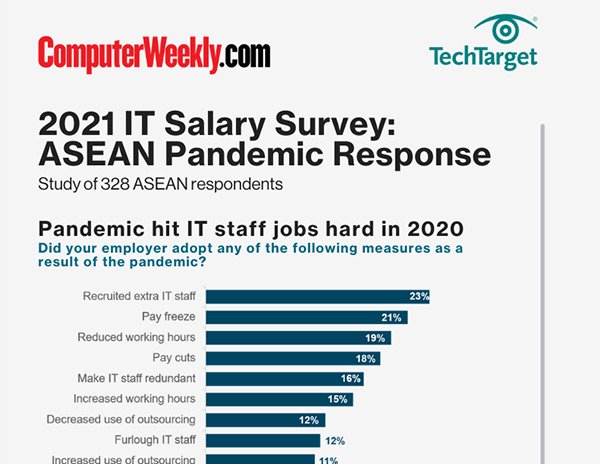
E-Handbook
2021 ASEAN Salary Survey - Pandemic Response Infographic
Download -
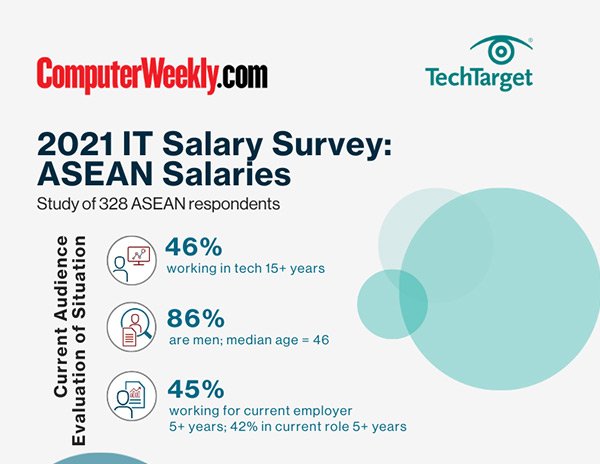
E-Handbook
2021 ASEAN Salary Survey - Salary Infographic
Download
-
E-Handbook
Innovation Awards APAC 2025
Download -
E-Handbook
Digital Transformation Unleashed: Smart Industries, AI & the 5G Revolution
Download -
E-Handbook
The pros & cons of AI in cybersecurity
Download -
E-Handbook
Beginner's guide to Internet of Things
Download
-
E-Handbook
What the future holds for cloud management in APAC
Download -

E-Handbook
IT Priorities 2022: APAC enterprises invest in digital future
Download -

E-Handbook
CW Innovation Awards: Bharti Airtel taps OpenStack to modernise telco network
Download -

E-Handbook
CW Innovation Awards: NUHS taps RPA in Covid-19 swab tests
Download
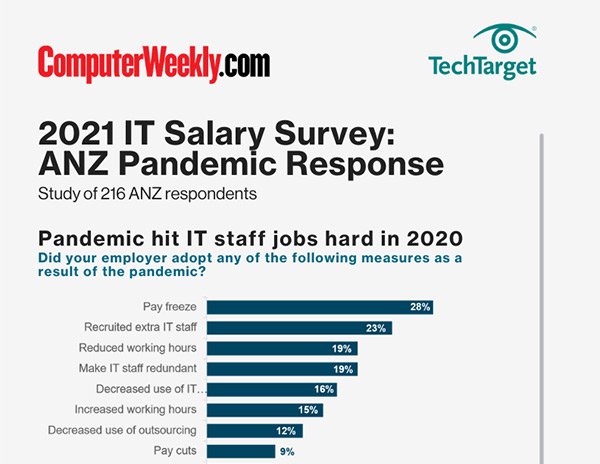
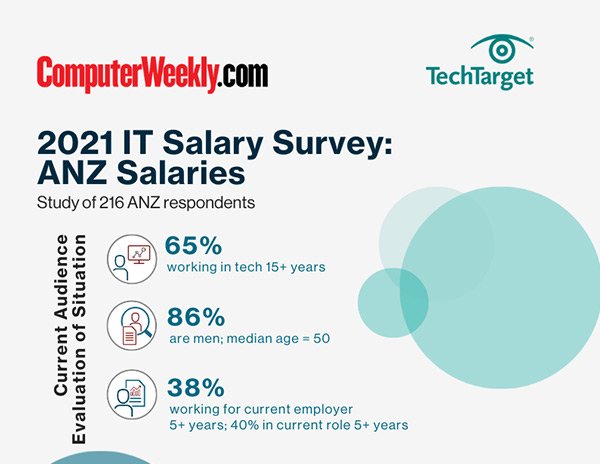

-
E-Handbook
Infographic: How organisations are using generative AI in EMEA
Download -

Infographic
Infographic: 2022 IT Salary Survey - Benelux Salaries
Download -

E-Handbook
Top 10 Benelux stories of 2021
Download -

E-Handbook
2021 UKI Salary Survey Results
Download


-
E-Handbook
Infographic: How organisations are using generative AI in EMEA
Download -

Infographic
Infographic: 2022 IT Salary Survey - Middle East Salaries
Download -

E-Handbook
2022 Middle East IT Priorities Infographic: Budgets and Buying Patterns
Download -

E-Handbook
Middle East - 2022 IT Priorities Survey Results
Download
-

E-Handbook
Top 10 Middle East IT stories of 2021
Download -

E-Handbook
Saudi IT spending to hit $11bn in 2021
Download -
E-Handbook
2021 UKI Salary Survey Results
Download -

E-Handbook
CIO Trends #11: Middle East
Download
-
E-Handbook
Infographic: How organisations are using generative AI in EMEA
Download -

Infographic
Infographic: 2022 IT Salary Survey - Nordics Salaries
Download -
E-Handbook
Top 10 Nordic IT stories of 2021
Download -
E-Handbook
2021 UKI Salary Survey Results
Download
-

E-Handbook
IT Priorities 2020: European IT budget share reflects home-working challenges brought by Covid
Download -
E-Handbook
IT Priorities 2020: Budgets rejigged to support 2021 recovery
Download -

E-Handbook
CIO Trends #11: Nordics
Download -

E-Handbook
Nordics' IT leaders facing the coronavirus crisis
Download

-
E-Handbook
Why real-time analytics is key to AI success
Download -
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
Digital Transformation Unleashed: Smart Industries, AI & the 5G Revolution
Download -
E-Handbook
Beginner's guide to Internet of Things
Download
-
E-Handbook
10 metaverse use cases for IT and business leaders
Download -

E-Handbook
Ultimate IoT implementation guide for businesses
Download -

E-Handbook
Royal Holloway: Securing connected and autonomous vehicles
Download -
E-Handbook
A Computer Weekly buyer’s guide to communications as a service
Download
-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
2025 Technology Priorities in APAC
Download -
E-Handbook
Top IT predictions in APAC in 2025
Download
-
E-Handbook
A Computer Weekly buyer’s guide to automation and autonomous control
Download -

E-Handbook
A guide to developing modern mobile applications
Download -

E-Handbook
A Computer Weekly buyer’s guide to 5G mobile networking
Download -

E-Handbook
A Computer Weekly buyer’s guide to secure and agile app development
Download
-

E-Handbook
A Computer Weekly buyer’s guide to video conferencing and collaboration
Download -
E-Handbook
A Computer Weekly buyer’s guide to next-generation retail technology
Download -

E-Handbook
A Computer Weekly buyer’s guide to application modernisation
Download -

E-Handbook
Cloud applications boost agility, productivity for APAC businesses
Download


-
E-Handbook
A Computer Weekly buyer’s guide to network cost and bandwidth optimisation
Download -
E-Handbook
A Computer Weekly buyer’s guide to communications as a service
Download -

E-Handbook
A Computer Weekly E-Guide to Network Management & Monitoring
Download -
E-Handbook
The rise of edge computing
Download
-
E-Handbook
Ofcom raise over £1.3bn in new 5G spectrum auction
Download -

E-Handbook
How virtual desktops simplify end user computing during lockdown
Download -

E-Handbook
Application Delivery Network Buyer's Guide
Download -

E-Handbook
A Computer Weekly buyer’s guide to networking for the modern workplace
Download
-
E-Handbook
A Computer Weekly buyer’s guide to network cost and bandwidth optimisation
Download -
E-Handbook
Beginner's guide to Internet of Things
Download -

E-Handbook
A Computer Weekly buyer’s guide to satellite broadband
Download -
E-Handbook
A Computer Weekly buyer’s guide to communications as a service
Download
-
E-Handbook
Royal Holloway: Security evaluation of network traffic mirroring in public cloud
Download -
E-Handbook
A Computer Weekly E-Guide to Network Management & Monitoring
Download -

E-Handbook
A Computer Weekly e-guide on Network Visibility, Performance and Monitoring
Download -

E-Handbook
CW Innovation Awards: Jio Platforms taps machine learning to manage telco network
Download
-
E-Handbook
Digital Transformation Unleashed: Smart Industries, AI & the 5G Revolution
Download -
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download -
E-Handbook
The ultimate guide to identity & access management
Download -
E-Handbook
How do cybercriminals steal credit card information?
Download

-
E-Handbook
Beginner's guide to Internet of Things
Download -

E-Handbook
The future is SASE: Transform your enterprise network for good
Download -
E-Handbook
A Computer Weekly buyer’s guide to satellite broadband
Download -
E-Handbook
Royal Holloway: Security evaluation of network traffic mirroring in public cloud
Download
-
E-Handbook
Royal Holloway: Secure multiparty computation and its application to digital asset custody
Download -
E-Handbook
Top 10 networking stories of 2021
Download -
E-Handbook
The CISO's guide to supply chain security
Download -
E-Handbook
A Computer Weekly E-Guide to Network Management & Monitoring
Download
-
E-Handbook
The future is SASE: Transform your enterprise network for good
Download -

E-Handbook
VoIP has never lost its voice: How to get the most out of your business communications
Download -
E-Handbook
The development of wired and wireless LANs in a hybrid work model
Download -
E-Handbook
How to achieve network infrastructure modernization
Download
-
E-Handbook
The future of API management: Key trends for IT leaders
Download -
E-Handbook
Top 10 ANZ IT stories of 2022
Download -
E-Handbook
Top 10 ASEAN IT stories of 2022
Download -
E-Handbook
Guide to building an enterprise API strategy
Download
-
E-Handbook
10 metaverse use cases for IT and business leaders
Download -

E-Handbook
A guide to continuous software delivery
Download -
E-Handbook
CW Innovation Awards: Bharti Airtel taps OpenStack to modernise telco network
Download -
E-Handbook
CW Innovation Awards: How DBS is transforming credit processes
Download
-
E-Handbook
Why real-time analytics is key to AI success
Download -
E-Handbook
Cyber resilience under pressure: How to demonstrate readiness
Download -
E-Handbook
Developing a storage strategy to support AI
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download
-
E-Handbook
CrowdStrike outage explained: What happened and what can we learn?
Download -
E-Handbook
Implementing GenAI: Use cases & challenges
Download -
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download -

E-Handbook
Multifactor authentication: What are the pros and cons?
Download
-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
Removing barriers to tech careers
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
Collaboration vital for making DEI progress
Download
-
E-Handbook
Computer Weekly 2024 salary survey
Download -
E-Handbook
The importance of getting everyone involved in the diversity drive
Download -
E-Handbook
Infographic: How organisations are using generative AI in EMEA
Download -
E-Handbook
Infographic: How organizations are using generative AI in Asia-Pacific
Download
-
E-Handbook
Cyber resilience under pressure: How to demonstrate readiness
Download -
E-Handbook
Developing a storage strategy to support AI
Download -
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download
-
E-Handbook
Developing a storage strategy to support AI
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
The pros & cons of AI in cybersecurity
Download -
E-Handbook
Implementing GenAI: Use cases & challenges
Download
-
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download -
E-Handbook
A Computer Weekly buyer’s guide to secure coding
Download -
E-Handbook
Multifactor authentication: What are the pros and cons?
Download -
E-Handbook
The ultimate guide to identity & access management
Download
-
E-Handbook
The pros & cons of AI in cybersecurity
Download -
E-Handbook
The future of API management: Key trends for IT leaders
Download -
E-Handbook
Top tech stories of 2024: ASEAN (Part 1)
Download -
E-Handbook
A Computer Weekly buyer’s guide to automation and autonomous control
Download
-
E-Handbook
Top 10 ANZ IT stories of 2022
Download -
E-Handbook
Top 10 India IT stories of 2022
Download -
E-Handbook
Guide to building an enterprise API strategy
Download -
E-Handbook
A guide to continuous software delivery
Download
-
E-Handbook
A Computer Weekly buyer’s guide to network cost and bandwidth optimisation
Download -
E-Handbook
10 metaverse use cases for IT and business leaders
Download -

E-Handbook
The rise of SD-WANs: Time to cross the chasm
Download -

E-Handbook
Infographic: 4 key SD-WAN trends to watch in 2022
Download
-

E-Handbook
A Computer Weekly buyer’s guide to emerging technology
Download -

E-Handbook
A Computer Weekly e-guide to WAN & applications services
Download -
E-Handbook
A Computer Weekly E-Guide to Network Management & Monitoring
Download -

E-Handbook
Essential Guide: How APAC firms can ride out the pandemic
Download
-
E-Handbook
Infographic: 5 considerations before buying data center backup software
Download -
E-Handbook
A Computer Weekly buyer’s guide to hybrid cloud storage
Download -
E-Handbook
A Computer Weekly buyer’s guide to sustainable datacentres
Download -
E-Handbook
Oracle cloud applications exhibit pragmatic adoption curve
Download
-

E-Handbook
A Computer Weekly buyer’s guide to computational storage and persistent memory
Download -
E-Handbook
AWS vs Azure vs Google: 5 key benefits each for cloud file storage
Download -

E-Handbook
A Computer Weekly buyer’s guide to intelligent workload management
Download -
E-Handbook
IT Priorities 2020: Covid-19 consolidates storage push to cloud
Download
-
E-Handbook
On the bug side cartoon collection – 2025: Inflating, Inflating, the AI bubble
Download -
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
Hybrid cloud connectivity best practices
Download -
E-Handbook
A Computer Weekly buyer’s guide to hybrid cloud storage
Download
-
E-Handbook
A Computer Weekly buyer’s guide to sustainable datacentres
Download -
E-Handbook
Oracle cloud applications exhibit pragmatic adoption curve
Download -
E-Handbook
Understanding Kubernetes to build a cloud-native enterprise
Download -
E-Handbook
A Computer Weekly buyer’s guide to computational storage and persistent memory
Download
-
E-Handbook
Developing a storage strategy to support AI
Download -
E-Handbook
A Computer Weekly buyer’s guide to hybrid cloud storage
Download -
E-Handbook
A Computer Weekly buyer’s guide to sustainable datacentres
Download -
E-Handbook
Oracle cloud applications exhibit pragmatic adoption curve
Download
-
E-Handbook
Understanding Kubernetes to build a cloud-native enterprise
Download -
E-Handbook
A Computer Weekly buyer’s guide to computational storage and persistent memory
Download -
E-Handbook
Executive Interview: Tapping APAC's storage potential
Download -
E-Handbook
A Computer Weekly buyer’s guide to containerisation in the enterprise
Download
-
E-Handbook
Innovation Awards APAC 2025
Download -
E-Handbook
Digital Transformation Unleashed: Smart Industries, AI & the 5G Revolution
Download -
E-Handbook
A Computer Weekly buyer’s guide to network cost and bandwidth optimisation
Download -
E-Handbook
Beginner's guide to Internet of Things
Download
-
E-Handbook
A Computer Weekly buyer’s guide to communications as a service
Download -
E-Handbook
Infographic: 5 differences between call centers and contact centers
Download -
E-Handbook
CW Innovation Awards: Bharti Airtel taps OpenStack to modernise telco network
Download -
E-Handbook
CW Innovation Awards: Jio Platforms taps machine learning to manage telco network
Download
-
E-Handbook
The enterprise guide to video conferencing in 2023
Download -
E-Handbook
VoIP has never lost its voice: How to get the most out of your business communications
Download -
E-Handbook
A Computer Weekly buyer’s guide to communications as a service
Download -

E-Handbook
Infographic: Zoom vs Teams vs Cisco
Download
-
E-Handbook
Essential Guide: How APAC firms can ride out the pandemic
Download -
E-Handbook
The rise of edge computing
Download -
E-Handbook
Ofcom raise over £1.3bn in new 5G spectrum auction
Download -

E-Handbook
A Computer Weekly Buyers Guide to IoT
Download
-
E-Handbook
A Computer Weekly buyer’s guide to hybrid cloud storage
Download -
E-Handbook
Oracle cloud applications exhibit pragmatic adoption curve
Download -
E-Handbook
A Computer Weekly buyer’s guide to computational storage and persistent memory
Download -

E-Handbook
A Computer Weekly buyer’s guide to colocation
Download
-
E-Handbook
AWS vs Azure vs Google: 5 key benefits each for cloud file storage
Download -
E-Handbook
Kubernetes: What enterprises need to know
Download -
E-Handbook
IT Priorities 2020: Covid-19 consolidates storage push to cloud
Download -
E-Handbook
Eyes on India: New age of flash storage boosts performance & efficiency
Download
-
E-Handbook
Digital Transformation Unleashed: Smart Industries, AI & the 5G Revolution
Download -
E-Handbook
The development of wired and wireless LANs in a hybrid work model
Download -
E-Handbook
Infographic: 4 key SD-WAN trends to watch in 2022
Download -
E-Handbook
Top 10 networking stories of 2021
Download

-
E-Handbook
An evaluation of the UK’s cyber security and privacy legislative framework
Download -
E-Handbook
CISO Success Stories: How security leaders are tackling evolving cyber threats
Download -
E-Handbook
How do cybercriminals steal credit card information?
Download -
E-Handbook
Top 10 ANZ IT stories of 2022
Download
-
E-Handbook
Guide to building an enterprise API strategy
Download -

E-Handbook
Headline: Royal Holloway: Attack mapping for the internet of things
Download -

E-Handbook
Royal Holloway: Cloud-native honeypot deployment
Download -
E-Handbook
Royal Holloway: Information security of the 2016 Philippine automated elections
Download
-
E-Handbook
Digital Transformation Unleashed: Smart Industries, AI & the 5G Revolution
Download -
E-Handbook
A Computer Weekly buyer’s guide to network cost and bandwidth optimisation
Download -
E-Handbook
Beginner's guide to Internet of Things
Download -
E-Handbook
The development of wired and wireless LANs in a hybrid work model
Download
-

E-Handbook
A comprehensive guide to HPC in the data center
Download -

E-Handbook
Chief data officer challenges mount amid calls for more value
Download -

E-Handbook
Mitigating risk-based vulnerability management challenges
Download -
E-Handbook
Security observability tools step up threat detection, response
Download