
ake1150 - stock.adobe.com
Kubernetes-Backup: Herausforderungen und verfügbare Lösungen
Daten aus Kubernetes-Umgebungen müssen wie andere auch gesichert werden. Dies bedarf aber spezieller Backup-Lösungen, da hier verschiedene Anforderungen bedient werden müssen.
Container und Container-Orchestrierung, vor allem über Kubernetes, verändern die Art und Weise, wie Unternehmen Anwendungen entwickeln und ausführen. Container-Architekturen ermöglichen es Unternehmen, Anwendungen schnell zu entwickeln, bereitzustellen und wieder außer Betrieb zu nehmen. Außerdem sind containerisierte Anwendungen leichter zwischen der Cloud und lokalen Systemen übertragbar. Für einige Unternehmen ist dies der Hauptvorteil. Mit der zunehmenden Verbreitung von Containeranwendungen werden jedoch auch immer mehr kritische Daten verarbeitet, die gesichert werden müssen.
Eines der Argumente zugunsten von Containern war, dass keine Backups erforderlich sind, da die Architektur zustandslos ist und die Anwendungen oft auf eine sehr kurze Lebensdauer ausgelegt sind (die meisten haben eine Betriebsdauer von weniger als einem Tag). Alle zustandsbehafteten Komponenten werden aus dem zentralen Key-Value-Speicher (etcd) erzeugt.
Dies eignet sich hervorragend für die schnelle Anwendungsentwicklung und webbasierte Abläufe. Wenn Unternehmen jedoch Container in den Kern ihres Betriebs einführen und sie potenziell als Ersatz für herkömmliche Anwendungen einsetzen, benötigen sie ein höheres Maß an Schutz. Das bedeutet, dass die etcd-Datenbank und alle in persistenten Volumes gespeicherten Daten geschützt werden müssen.
Im Allgemeinen sichern Unternehmen Kubernetes nicht mit nativen Tools, wenn sie es überhaupt sichern. Viele Produktteams sichern die etcd-Konfigurationsdatenbank für ihre Cluster, dann sichern sie den Primärspeicher, in dem die Container-Images gespeichert sind, und alle Referenzen auf persistente Volumes in den YAML-Dateien.
Das ist generell in Ordnung, wenn die Komplexität gering ist und die Kubernetes-Anwendungen keinen oder nur einen minimalen Status haben. Man braucht Anwendungsbewusstsein, um den Zustand einer Anwendung zu sichern, und um zu erfassen, wo in einem bestimmten Schritt einer Anwendung die Transformation von Daten im Falle eines Desasters abgebrochen wurde.
Dies führt zu zwei Hauptansätzen für das Kubernetes-Backup - dedizierte Produkte und breiter angelegte Backup- und Recovery-Tools, die Container-Umgebungen unterstützen.
Was beim Kubernetes-Backup wichtig ist
Bei einem Kubernetes-Backup sichert die Backup-Lösungen die Komponenten, die in einer Kubernetes-Orchestrierungsplattform operieren. Die Plattform ist die Abstraktionsschicht für containerisierte Anwendungen und Services. Zu den Komponenten einer Kubernetes-Umgebung gehören Pods, Nodes, die Control Plane und Volumes. Ebenso enthalten zahlreiche containerisierte Anwendungen Microservices, die ebenso ins Backup integriert werden müssen.
Eine Backup-Lösung gewährleistet die Data Protection für die Container im Kubernetes-Cluster. Da Container nicht das zugrunde liegende Betriebssystem enthalten, benötigen sie eine andere Datensicherung als physische oder virtuelle Server. Das liegt auch daran, dass containerisierte Apps in mehreren Pods und auf mehreren Maschinen mit vielen Objekten mit Konfigurations- und Anwendungsdaten ausgeführt werden und eben nicht nur auf einem einzigen System laufen. Die Kubernetes-Backup-Lösung muss die Daten und die Anwendungskonfiguration auf einer granularen Ebene erfassen, um eine schnelle Wiederherstellung zu gewährleisten.
Die Sicherung und Wiederherstellung für Kubernetes konzentriert sich auf die Sicherung der gesamten Anwendung aus dem lokalen Kubernetes-Cluster an einem anderen Speicherort, entweder extern oder auf einem sekundären Speicher. Bei dem externen Speicher kann es sich um Objektspeicher in Public oder Private Clouds oder um lokalen Speicher in eigenen Rechenzentren in verschiedenen Regionen handeln. Backup-Lösungen können auch mehrere Backup-Ziele haben. Backups werden häufig durchgeführt, um sich vor Systemausfällen zu schützen oder um eine Checkliste zur Einhaltung von Vorschriften oder gesetzlichen Bestimmungen für Ihre Anwendung zu erfüllen.
Unabhängig vom Sicherungsziel sollten Sie sorgfältige Schritte befolgen, um eine ordnungsgemäße Sicherung und Datensicherheit zu gewährleisten. Die wichtigsten Phasen des Kubernetes-Backups umfassen:
- Erkennung. Automatische Erkennung von Anwendungen mithilfe von Label-Selektoren oder Namespaces.
- Identifizieren von Ressourcen. Identifizieren Sie die Anwendung, Volumes, Konfigurationsdateien und die zu schützenden Kubernetes-Cluster.
- Backup. Vervollständigen Sie das Backup der identifizierten Ressourcen am angegebenen Zielort.
Eine gute Kubernetes-Backup-Lösung soll dafür sorgen, dass Ausfallzeiten selten sind und dass Anwendungen und ihre Daten nach einem Ausfall oder Datenverlust schnell wiederhergestellt werden können. Darüber hinaus müssen Datenschutzstrategien den Datenschutz und die Einhaltung gesetzlicher Vorschriften gewährleisten.
Ohne ein robustes Kubernetes-Backup sind containerisierte Anwendungen nicht gesichert. Der Schutz von geschäftskritischen Workloads und den dazugehörigen Microservices, Containern und Daten ist für das Überleben des Unternehmens unerlässlich.
Traditionelle Backup-Lösungen schaffen es oft nicht, mit der dynamischen Natur einer Kubernetes-Umgebung mitzuhalten. RTOs und RPOs müssen deutlich enger definiert sein. Das kann heißen, dass die Anforderung an RPO bei Null oder höchstens bei 15 Minuten liegen. Die Software muss die Kubernetes-Anwendungen verstehen, was nicht alle Backup-Produkte leisten können. Dafür muss mit dem Backup der Namensraum und bestimmte Anwendungen gesichert werden.
Die etcd-Datenbank ist eine wichtige Komponente, die Informationen über das jeweilige Cluster enthält. Sie lässt sich manuell oder automatisiert sichern. Bei der manuellen Sicherung wird mittels etcdctl snapshot save db eine einzelne Datei namens snapshot.db erstellt.
Wir listen im Folgenden verfügbare Backup-Lösungen für Kubernetes-Umgebungen auf. Dies ist ein keineswegs vollständiger Überblick über den Markt.
AFI.ai
AFI bietet Backup-Funktionen für alle K8-Anwendungen, -Elemente und -Metadaten an. Sie soll zudem automatisierte Wiederherstellungen gesamter Kubernetes-Cluster und App-Komponenten ermöglichen. Darüber hinaus integriert sich die Lösung auch mit anderen Orchestrations-Plattformen für Container. Das AFI-Backup lässt sich als App bereitstellen, um isolierte Kubernetes-Umgebungen zu sichern, ohne dabei mit dem Internet verbunden sein zu müssen. Das Produkt ist auch als Cloud-gehosteter Backup-Service verfügbar, um das Backup-Management mehrerer Cluster zu konsolidieren. Die Sicherung kann am lokalen Standort, in einer S3-Cloud oder im AFI-verwalteten Cloud Storage erfolgen.
Afi nutzt KI, um geschützte Anwendungskomponenten abzubilden und liefert dann anwendungsspezifische, konsistente und vollständige Backups. Es stellt zudem einsatzbereite Vorlagen für die Anwendungskonsistenz sowie Skripte zur Vor- und Nachkonfiguration für die gängigsten Wordkloads zur Verfügung. Eine Anti-Ransomware-Engine überwacht Änderungen und erkennt Datenverschlüsselungsmuster, die für Cyberangriffe spezifisch sind. Wird eine entsprechende Malware entdeckt, werden Warnmeldungen an den Administrator gesendet. Die Lösung initiiert dann automatisch präventive Backups, um mögliche Schäden zu begrenzen. Die automatische Kennzeichnung von Wiederherstellungspunkten hilft, die letzten sauberen Backup-Versionen, die nicht von Ransomware betroffen sind, hervorzuheben und die Wiederherstellung zu beschleunigen.
Das AFI-Backup stellt Command Line Interfaces und APIs für die Integration mit DevOps-Systemen bereit. Es lassen sich auch Tools für das Infrastrukturmanagement wie Terraform, Circle CI oder Jenkins integrieren.
Bacula Systems
Bacula Systems bietet eine Kubernetes Sicherungs- und Wiederherstellungslösung an, die auf der Webseite des Unternehmens in einem detaillierten Whitepaper erklärt wird. Um dieses herunterladen zu können, müssen sich interessierte IT-Verantwortliche allerdings registrieren. Das Kubernetes-Modul der Bacula-Enterprise-Lösung sichert unter anderem Bereitstellungen, Pods, Dienste und persistente Volumes von Kubernetes. Zu den Sicherungsfunktionen für Kubernetes gehören beispielsweise:
- Backup der Konfiguration von Cluster-Ressourcen
- Restore einzelner Konfigurationsressourcen
- Backup und Recovery persistenter Daten
- Wiederherstellung der Konfiguration von Kubernetes-Ressourcen in einem lokalen Verzeichnis
- Kubernetes-Backup und -Recovery für persistente Volumes
- Wiederherstellung von Kubernetes-Daten für persistente Volumes in einem lokalen Verzeichnis
- Backup und Recovery gesamter Kubernetes-Cluster
- Schnelle Neuverteilung der Cluster-Ressourcen
- Sicherung von geänderten Konfigurationen
- Sicherung von Konfigurationen zur Verwendung mit anderen Operationen
Die Lösung wird über ein CLI oder ein GUI verwaltet. Es gibt zwei Optionen für die Wiederherstellung: Entweder im Kubernetes-Cluster oder in einem lokalen Verzeichnis. Das Bacula Enterprise Kubernetes-Backup-Modul unterstützt zudem eine Auflistungsfunktion. In diesem Modus werden einige nützliche Informationen über verfügbare Kubernetes-Ressourcen angezeigt, wie zum Beispiel die Liste der Kubernetes-Namespaces und die Liste der persistenten Kubernetes-Volumes. Die Funktion verwendet den speziellen .ls-Befehl mit einem plugin=<plugin>-Befehlsparameter.
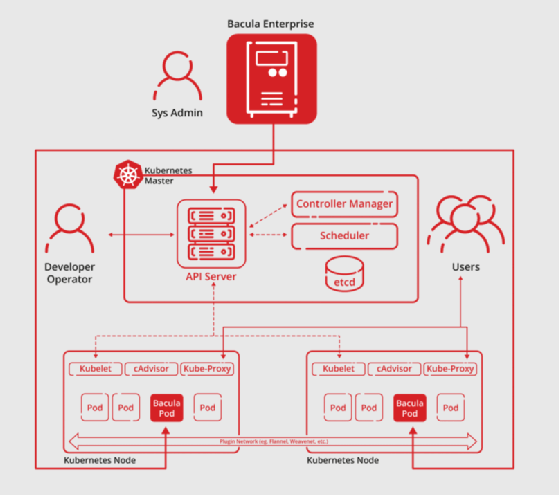
Der Anbieter bietet eine herunterladbare Testversion (für zwei Stunden), ein Webinar, einen Leitfaden für Disaster Recovery sowie eine Checkliste für Ransomware-Prävention und die Option einer unverbindlichen Angebotsanfrage.
Cloudcasa
Cloudcasa von Catalogic ist relativ ungewöhnlich auf dem Markt, da es als Backup-as-a-Service arbeitet. Es bietet Wiederherstellung auf Clusterebene und kostenlose Snapshots, die 30 Tage lang aufbewahrt werden, sowie eine Reihe von kostenpflichtigen Optionen, einschließlich Kubernetes Persistent Volume (PV) Backups. Cloudcasa unterstützt Amazon EBS-Snapshots und CSI-Snapshots.
Backups, Recoverys und Migrationen können dabei über verschiedene Clouds hinweg erfolgen. Das hat den Vorteil, dass keine neue Infrastruktur installiert und gewartet werden muss. Darüber hinaus verspricht der Anbieter Cyberresilienzbeispielsweise durch sichere Zugriffskontrollen. Die Funktionen wie Snapshots und Backups werden nicht abgerechnet, sondern nur die Speicherkapazität für die gesicherten Daten, wobei 100 GByte an Backup-Daten kostenlos sind.
Der Free Service Plan bietet eine unbegrenzte Anzahl von PV-Snapshots mit Orchestrierung, keine Begrenzung von Worker Nodes oder Clustern, mit Kubernetes- und Cloud-Sicherheitsscans und Kubernetes-Ressourcen-Backups, ohne dass dafür Kosten anfallen. Auf der Webseite des Anbieters ist auch eine kostenfreie Testversion verfügbar.
Cohesity
Auch Cohesity positioniert sein Helios-Backup-Tool als Cloud-nativen Service für Container. Der Anbieter arbeitet mit den drei Hyperscale-Plattformen zusammen und sichert die persistenten Zustände von Anwendungen, persistente Volumes und operative Metadaten. Multi-Cloud-Unterstützung bedeutet, dass Backups und Wiederherstellungen über eine Reihe von Cloud-Anbietern erfolgen können, um zusätzliche Ausfallsicherheit zu gewährleisten.
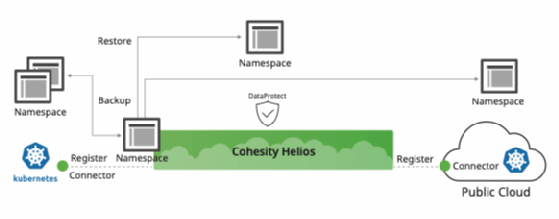
Die Klon-Tools von Cohesity bieten außerdem Null-Kosten-Klone, so dass DevOps-Teams Backup-Daten für die Anwendungsentwicklung nutzen können. Die Lösung legt anwendungskonsistente Snapshots für vereinfachte stateful und stateless App-Orchestrierung. Inkrementale Backups sollen zudem schnelle Wiederherstellungen gewährleisten.
Auf der Herstellerwebseite sind zahlreiche Hintergrundinformationen zu finden, darunter ein Video darüber, wie Kubernetes-Backups und -Namespaces gesichert werden können, ein Webinar über containerisierte Anwendungen sowie einige Analystenbeiträge. Ebenso lässt sich eine 30-tägige Testversion ausprobieren.
Druva
Druva bietet eine Lösung für das Kubernetes-Backup für AWS und verspricht eine Sicherung der Applikationsdaten ohne Komplexität entweder in Amazon EC2 oder EKS. Das Produkt ist applikationszentrisch und identifiziert alle Anwendungen, das darunterliegende Storage sowie die Datenbankservices in Kubernetes-Umgebungen. Auch Druva nutzt für die Datensicherung Snapshots, um schnelle und einfache Wiederherstellungen zu gewährleisten. Diese können in einer neuen AWS-Region oder in einem neuen AWS-Account wiederhergestellt werden, um Workload-Migration, Klonenoder Problembehebungen über das User Interface umzusetzen. Ein Recovery ist zudem in einem bereits existierenden oder einem anderen Namespace sowie im gleichen oder einem alternativen Cluster möglich. Datensicherungen können über verschiedene Regionen und über unterschiedliche Accounts erfolgen.
Der Administrator greift auf die AWS-Cluster mittels CloudFormation zu und installiert den Druva Backup Operator über helm-Kommandos, um Cluster zu registrieren. Die Lösung unterstützt mehrere Administratorenrollen, unter anderem DevOps, Cloud-Admins oder App-Eigner (App Owner). Mit dem Setzen von Tags wird eine einheitliche richtlinienbasierte Data Protection initiiert.
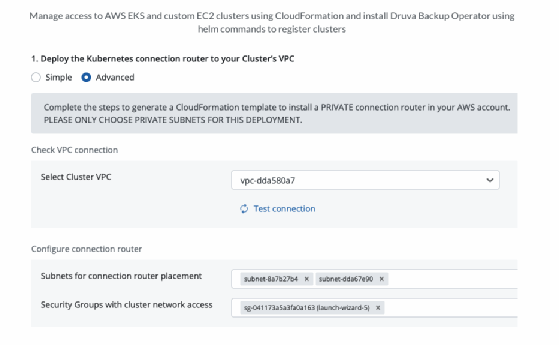
Integriertes Monitoring und historische Übersichten geben einen Einblick in die Backup-Aktivitäten, das Disaster Recovery, das Restore, die Datenvorhaltung und das Scheduling. Die Wiederherstellung erfolgt als Self Service und kann vom Anwender ohne Support vom Anbieter ausgeführt werden.
Um Compliance-konform zu sein, kann der Admin die dedizierten Logs für Cluster und Anwendungsgruppen sowie Ereignisprotokolle für alle Backups und Recoverys nutzen. Eine Anwendungsgruppe ist eine Kubernetes-Applikation, die vom Admin definiert wird und damit für das Backup gekennzeichnet wird. Darüber hinaus gibt es eine Funktion für das Data Lifecycle Management. Als Storage wird Amazon EBS genutzt, auf den mittels des Kubernetes-CSI-Treibers zugegriffen wird. Das Datenblatt zur Lösung ist auf der Webseite zu finden, ebenso ein Demo-Video sowie eine 30-tägige Testversion.
Kasten K10
Kasten (Teil des Unternehmens Veeam) positioniert seine K10-Software als zweckbestimmte Kubernetes-Datenmanagementlösung. Die Anwendung läuft in ihrem eigenen Namespace auf einem Kubernetes-Cluster und unterstützt alle wichtigen Cloud-Plattformen sowie On-Premise-Architekturen. Das Tool sucht nach Komponenten, die gesichert werden müssen, einschließlich persistenter Speicher-Volumes und Datenbanken. Benutzer können ihre eigenen Data-Protection-, Backup- und Disaster-Recovery (DR)-Richtlinien festlegen.
Die Automatisierung der Backups und Recoverys von stateful Kubernetes-Anwendungen erfolgt über Richtlinien. Mit diesen werden bestimmte Aktionen festgelegt wie beispielsweise Snapshots und die Frequenz der Aktionen. Auch Label-basierte Auswahlkritieren für die zu verwaltenden Ressourcen werden hier definiert. Als darunter liegenden Speicher kann der Anwender Datei-, Block- und Objektspeicher in der lokalen Infrastruktur oder Cloud Storage verwenden.
Indem die Anwendungen mit Richtlinien verknüpft werden, soll die Skalierung des operativen Workflows für Backup- und Anwendungsmobilitätsanforderungen ohne großen Aufwand erreicht werden können. Die Richtlinien sorgen mit Dynamic Policies dafür, dass die Compliance überwacht und somit eingehalten werden kann.
Die Lizenzstruktur orientiert sich an der Kubernetes-Nutzung. Die Community Edition bietet eine kostenfreie Nutzung für bis zu fünf Knoten. Eine Testversion der Enterprise Edition für bis zu 50 Knoten ist für 30 Tage zu testen. Die reguläre Software ist im Abonnement für ein, drei oder fünf Jahre zu erwerben, unterstützt beliebig viele Knoten und bietet Support rund um die Uhr an.
KubeDR
Catalogic Software bietet ebenso die kostenfreie Lösung KubeDR an. Diese befindet sich derzeit in der Alpha-Phase, was bedeutet, dass noch immer Änderungen in die Funktionen einfließen können. Wie bereits erwähnt, sicher Kubernetes alle Objekte in etcd, weshalb das Backup von etcd-Daten essentiell ist. Das KubeDR-Projekt implementiert ein Tool, das etcd-Daten und Zertifikate in einem beliebigen S3-Bucket sichert. Es folgt dem Operator-Muster, das in der Kubernetes-Welt populär ist. Für den Datentransfer zu den S3-Buckets nutzt die Lösung ein Tool namens restic. Die Backups selber sind verschlüsselt und dedupliziert. Backup-Aufträge können angehalten und wieder angestoßen werden. Darüber hinaus lässt sich die Zahl der Backups bestimmen, die vorgehalten werden sollen.
Die Installation erfolgt über eine YAML-Datei. Bevor der Admin die Backups aktivieren kann, muss er sicherstellen, dass Master Nodes und S3-Endpunkte (Backup-Ziel) eingerichtet sind. Die Datensicherung selbst wird mit Snapshots umgesetzt, wobei nicht nur etcd, sondern auch Zertifikate gesichert werden.
KubeDR stellt mehrere Metriken zur Verfügung, die mit Prometheus abgefragt und mit Grafana visualisiert werden können. Die meisten Metriken befassen sich mit der internen Implementierung, aber weitere Informationen sind ebenso abrufbar, unter anderem die Backup-Größe, erfolgreiche Backups, erfolglose Backups oder die Dauer der Datensicherung.
Der Hersteller arbeitet weiterhin an Optimierungen seiner Software und will weitere Funktionen in den kommenden Versionen integrieren. Dazu gehört der Support der Helm-Installation und die Möglichkeit das Backup-Tool zu wechseln und nicht nur an restic gebunden zu sein. Zudem ist geplant, zusätzlich zum S3-Backup-Ziel auch ein Dateisystem-Target zu unterstützen. Einige zusätzliche Details sind auch unter Github zu finden.
Metallic
Metallic gehört zum Commvault-Portfolio und bietet mit Metallic VM & Kubernetes eine Backup-Lösung für die entsprechenden Umgebungen. Das Produkt ist Cloud-basiert und direkt für Container konzipiert. Unabhängig davon, ob am eigenen Standort oder in der Cloud, Metallic unterstützt alle CNCF-zertifizierten Kubernetes-Distributionen, unter anderem AKS, Oracle Container Engine for Kubernetes, EKS, oder RedHat OpenShift.
Als Backup-Target stehen mehrere Optionen zur Wahl, sowohl Hardware als auch Software. Zu den Cloud-Speichermöglichkeiten gehören:
- Metallic Cloud Storage (Azure oder OCI)
- Microsoft Azure Storage
- Amazon S3
- HPE Cloud Volumes Backup
- Oracle Cloud Infrastruktur
- AWS
Die wählbaren Hardware-Systeme umfassen die folgenden:
- Commvault Distributed Storage
- Commvault
- Hyperscale X
- NetApp E-Series
- Dell EMC: Isilon, Data Domain
- Pure Storage: FlashArray, FlashBlade
- HPE: Primera, Nimble, 3Par, StoreOnce Catalyst
- Hitachi: HNAS, VSP, HCP
Die Backups können sowohl in-flight als auch at-rest verschlüsselt werden. Für optimierte Sicherheit kommen rollenbasierte, SSO- und SAML-Authentifizierung zum Einsatz. Um einen Schutz vor Ransomware-Angriffen zu gewährleisten, verfügt die Lösung über Anomalie-Erkennung und Air-Gap-Funktion. Darüber hinaus kann der Anwender vorkonfigurierte und empfohlene Pläne nutzen, die direkte Praxistipps geben.
Preise werden nach der Anzahl der virtuellen Maschinen berechnet. Ein Paket für 10 VMs kostet 84,78 Euro pro Paket/Monat, wenn der Nutzer bis zu 49 Pakete erwirbt. Bei 50 bis 199 Paketen kostet das 10er-Pack 72,35 Euro pro Monat. Kauft ein Kunde zwischen 200 und 999 Paketen, fallen 63,77 Euro pro Monat für 10-VM-Bundle an. Anwender, die mehr Pakete benötigen, müssen eine Preiskalkulation anfordern. Weitere Preismodelle sind auf der Webseite unter diesem Link abrufbar. Des Weiteren kann auch hier eine Testversion für 30 Tage ausprobiert werden.
NetApp Astra Data Store
Der Astra Data Store von NetApp ist ein Dateiservice für Container und virtuelle Maschinen (VMs), der auf einem Standard-NFS-Client basiert. Astra ist darauf ausgerichtet, die Speicherung in Containern und VMs zu vereinfachen und effizienter zu gestalten, so dass Unternehmen in beiden Architekturen denselben Speicherpool und dieselben Backup-Tools verwenden können.
NetApp hat seine Astra Control Software aktualisiert, um zusätzliche Kubernetes-Plattformen zu unterstützen, darunter Rancher und Community Kubernetes. Sie nutzt die Backend-Technologien von NetApp für Datensicherung, DR und Migration.
Die Plattform besteht aus drei Komponenten: Astra Control, Astra Trident und Cloud Volumes Platform und ONTAP. Astra Control bietet zustandsbehafteten (stateful)Kubernetes-Workloads ein Angebot an Storage- und applikationsspezifischen Datensicherungs- und Mobilitätsservices. Astra Trident stellt Orchestrierung und Datenkonnektivität für Kubernetes-Applikationen zur Verfügung. Es ist ein Kubernetes Container Storage Interface (CSI)-Treiber und wird als kostenloses Open-Source-Angebot von NetApp bereitgestellt. Cloud Volumes Platform und ONTAP offerieren persistenten Speicher für datenintensive Kubernetes-Workloads mit CVS für Google Cloud Platform, Google Persistent Disk, ANF, Azure Disk Storage und ONTAP. Weitere technische Details sind auf der Webseite des Herstellers aufgeführt.
Die Lösung ist Kubernetes-nativ und wird als Cloud-Service angeboten. Der Anbieter verspricht, dass sich Storage und Applikationen gemeinsam ausführen lassen und über Funktionen wie API-first, Selbstheilung und automatisierte granulare QoS verfügt. Anwender können neben der Cloud auch ihre eigene Hardware nutzen, horizontal skalieren sowie Daten und Apps über Cluster-, Hybrid- und Multi-Cloud-Umgebungen bewegen.
OpenEBS
OpenEBS ist eine Open-Source-Lösung, die Speicher und Datensicherungen für Kubernetes-Daten bereitstellt. Sie hilft also Entwicklern und Site Reliablity Engineers bei der einfachen Bereitstellung von Kubernetes Stateful Workloads, die einen schnellen und hochzuverlässigen Container Attached Storage erfordern. OpenEBS wandelt jeden verfügbaren Speicher auf den Kubernetes-Worker-Nodes in lokale oder verteilte Kubernetes Persistent Volumes um. Es ist eine Kubernetes-native CAS-Lösung, die es Stateful-Anwendungen erlaubt, einfach auf dynamische lokale PVs oder replizierte PVs zuzugreifen. Dadurch sollen Anwender Speicherkosten einsparen, das Management vereinfache und bessere Kontrolle erhalten.
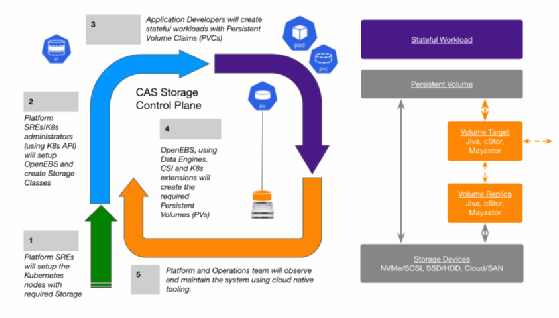
Für lokale Volumes setzt die Lösung folgendes um:
- Erstellt Persistent Volumes unter Verwendung von Raw Block Devices oder Partitionen, von Unterverzeichnissen auf Hostpfaden oder unter Verwendung von LVM, ZFS oder Sparse Files.
- Die lokalen Volumes werden direkt in den Stateful Pod gemountet, ohne zusätzlichen Overhead im Datenpfad, was die Latenz verringert.
- Stellt zusätzliche Tools für Local Volumes unter anderem für Monitoring, Backup/Restore, Disaster Recovery, Snapshots bei ZFS- oder LVM-Backups oder kapazitätsbasiertes Scheduling bereit.
Für die verteilten Volumes sind diese Funktionen verfügbar:
- Erstellt einen Micro-Service für jedes Distributed Persistent Volume mit einer seiner Engines: Mayastor, cStor oder Jiva.
- Der Stateful Pod schreibt die Daten in die OpenEBS-Engines, die die Daten synchron auf mehrere Knoten im Cluster replizieren. Die OpenEBS-Engine selbst wird als Pod implementiert und von Kubernetes orchestriert. Wenn der Knoten, auf dem der Stateful-Pod läuft, ausfällt, wird der Pod auf einen anderen Knoten im Cluster verlagert, und die Lösung ermöglicht den Zugriff auf die Daten mithilfe der verfügbaren Datenkopien auf anderen Knoten.
- Die Stateful Pods verbinden sich mit dem OpenEBS Distributed Persistent Volume über iSCSI (cStor und Jiva) oder NVMe-oF (Mayastor).
- cStor und Jiva verwenden angepasste Versionen der ZFS- beziehungsweise Longhorn-Technologie zum Schreiben der Daten auf den Speicher.
- OpenEBS Mayastor ist eine Engine, die für Langlebigkeit und Leistung entwickelt. Sie verwaltet die Rechenleistung (hugepages, Kerne) und den Speicher (NVMe-Laufwerke), um schnellen verteilten Blockspeicher bereitzustellen.
Anwender können zwei verschiedene Bereitstellungsstrategien nutzen. Sie können entweder einen hyperkonvergenten Modus verwenden, in dem zustandsabhängige (stateful) Anwendungen und Speicher-Volumes gemeinsam genutzt werden, oder zustandsabhängige Anwendungen und Speicher auf verschiedenen Node-Pools ausführen.
Zu den unterstützen Betriebssystemen für die Worker Nodes gehören:
- Ubunte
- RHEL
- CentOS
- OpenShift
- Rancher
- ICP
- EKS
- GKE
- AKS
- Digital Ocean
- Konvoy
Das Kubernetes-CSI (Bereitstellungsschicht) fängt die Anfragen für die Persistent Volumes ab und leitet sie an die OpenEBS Control-Plane-Komponenten weiter, um diese zu bedienen. Die in der StorageClass bereitgestellten Informationen in Kombination mit Anfragen von PVCs bestimmen die richtige OpenEBS-Kontrollkomponente, die die Anfrage erhält.
Die Control Plane verarbeitet dann die Anfrage und erstellt die Persistent Volumes unter Verwendung der angegebenen lokalen oder replizierten Engines. Die Dienste der Daten-Engine, wie Target und Replica, werden ebenfalls als Kubernetes-Anwendungen implementiert. Die neuen Container, die für die Bereitstellung der Anwendungen gestartet werden, sind im OpenEBS-Namensraum verfügbar.
Sobald die Workloads in Betrieb sind, kann die Plattform oder das IT-Team das System mit Hilfe von Cloud-nativen Tools wie Prometheus oder Grafana überwachen. Anwendungsteams können die Kapazität und Leistung beobachten und die PVCs entsprechend anpassen. Die Plattform- oder Cluster-Teams können die Auslastung und Leistung des Speichers pro Knoten überprüfen und über die Erweiterung und Verteilung der Daten-Engines entscheiden. Das Infrastrukturteam ist für die Planung von Erweiterungen oder Optimierungen auf der Grundlage der Ressourcenauslastung zuständig.
Eine Anleitung für einen Schnellstart ist bei OpenEBS auf der Webseite zu finden. Da dies eine kostenlose Open-Source-Lösung ist, hängt vieles der Weiterentwicklungen von dem Engagement der Community ab, der sich jedes Unternehmen oder jeder Entwickler anschließen kann. Weitere Dokumentationen sind unter github.com einsehbar.
Portworx
Portworx (Teil von Pure Storage) war einer der ersten Anbieter, der persistenten Speicher für Container entwickelt hat, und ist daher gut aufgestellt, um Backups für Kubernetes-Umgebungen bereitzustellen. Dies geschieht über die Software PX-Backup, die nach eigenen Angaben containergranular und App-bewusst ist. Das Tool unterstützt Block-, Datei- und Objekt- sowie Cloud-Speicher. Es verfügt über Tools zur Speichererkennung und -bereitstellung sowie über Funktionen für Backup, DR, Sicherheit und Migration. Allerdings lässt sich Kubernetes Storage auch mit den Versionen Portworx Essentials und Portworx Enterprise bereitstellen, wobei PX-Backup aber die umfassendere Lösung bietet. Zum Funktionsumfang gehören unter anderem:
- Anwendungskonsistente Backups (inklusive aller Konfigurationsdaten)
- Backup von Kubernetes-Objekte und -Daten sowie von Pods, Tags und Namensräumen
- Backup von Cloud-Volumes, selbst wenn Portworx Enterprise nicht genutzt wird
- Automatisierung geplanter Backups
- Support rund um die Uhr an sieben Tagen die Woche
- Voller Zugriff auf Dokumentation, Foren, Schritt-für-Schritt-Tutorials
- Sicherung und Wiederherstellung jeder Kubernetes-Anwendung zwischen jedem Kubernetes-Cluster, das in einem beliebigen Cloud- oder On-Premise-Rechenzentrum läuft.
- Verschieben von Anwendungen zwischen Kubernetes-Umgebungen als Teil einer geplanten Migration oder Upgrades. Dadurch ist ein Backup in einer und das Restore in einer anderen Umgebung möglich.
- Speicheragnostisches Backup
- Self-Service-Schnittstelle für Data Protection
Preise müssen beim Hersteller angefragt werden. Es stehen zahlreiche Dokumentationen über die Lösung zur Verfügung, darunter ein Datenblatt, ein White Paper zur Data Protection für Kubernetes, eine Portworx-Demo, eine Kurzübersicht zurBackup- und Restore-Lösung sowie eine Übersicht über die gesamte Plattform.
Rancher Longhorn
Rancher Longhorn (von Suse) ist ein offizielles Sandbox-Projekt der Cloud Native Compute Foundation (CNCF), das eine Cloud-native verteilte Speicherplattform für Kubernetes bereitstellt, die überall ausgeführt werden kann. In Kombination mit Rancher gewährleistet Longhorn die Bereitstellung von hochverfügbarem persistentem Blockspeicher in einer Kubernetes-Umgebung. Longhorn war ursprünglich ein Rancher-Labs-Projekt und wurde 2017 als Zeichen des Engagements von Rancher für die Open-Source-Gemeinschaft an die CNCF gespendet. Longhorn ist ebenso eine Open-Source-Software, für die keine Lizenz erworben werden muss.
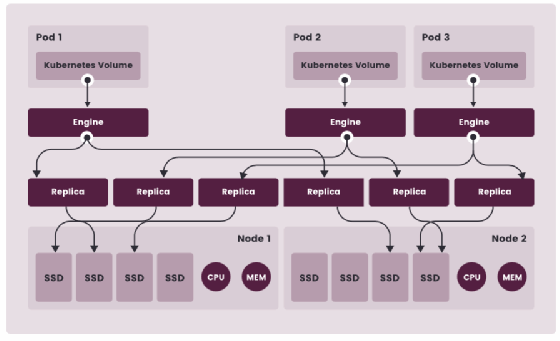
Die Lösung bietet einen eigenen Backup- und Restore-Operator. Der Operator muss im lokalen Kubernetes-Cluster installiert werden und sichert die Rancher-App. Die Rancher-Benutzeroberfläche ermöglicht jedoch etcd- und Cluster-Backups, einschließlich Snapshots. Diese können lokal oder in einem S3-kompatiblen Cloud-Ziel gespeichert werden. Zudem unterstützt die Software NFS. Für die Wiederherstellungen lassen sich Recovery Point Objectives (RPO) und Recovery Time Objectives (RTO) definieren. Konfiguration und Verwaltung erfolgen über eine grafische Benutzerschnittstelle (GUI).
Zu den Funktionen gehören unter anderem:
- Longhorn-Volumes als persistenten Speicher für verteilte zustandsbehafteten (stateful) Anwendungen in Kubernetes-Cluster nutzen.
- Blockspeicher in Longhorn-Volumes kann so partitioniert werden, so dass die Kubernetes-Volumes mit oder ohne Cloud-Anbieter genutzt werden können.
- Replikation von Blockspeicher über mehrere Knoten und Rechenzentren hinweg für höhere Verfügbarkeit.
- Backup-Daten in externem Storage mit NFS oder AWS S3 speichern.
- Erstellen von Cluster-übergreifenden Disaster-Recovery-Volumes, so dass Daten aus einem primären Kubernetes-Cluster schnell aus einem Backup in einem zweiten Kubernetes-Cluster wiederhergestellt werden können.
- Planung stetiger Snapshots eines Volumes und Planung wiederkehrender Backups auf NFS- oder S3-kompatiblem Sekundärspeicher.
- Wiederherstellung von Volumes aus dem Backup
- Upgrade von Longhorn ohne Unterbrechung von persistenten Volumes
Auch für Longhorn gibt es natürlich eine Community, an der sich unterschiedliche Parteien beteiligen können. Auf der Seite von Longhorn.io finden Anwender zahlreiche detaillierte Beschreibungen, unter anderem wie sich Backup-Ziele und Backups einrichten und Restores umsetzen lassen.
Red Hat OpenShift Container Storage
Red Hat (Teil von IBM) führte 2020 eine umfangreiche Kubernetes-Unterstützung in seine Data Services-Linie ein und ersetzte damit frühere IBM-Angebote. Das Tool-Set ist außerdem mit IBMs Spectrum Protect Plus Services sowie mit TrilioVault und Kasten K10 verknüpft. Darüber stehen Plug-ins für AWS, Azure und GCP für die Data Protection zur Verfügung.
Red Hat OpenShift Container Storage fügt die Data-Protection-Tools des Anbieters zu Container-Umgebungen hinzu, ohne zusätzliche Technologie oder Infrastruktur. Zu den Funktionen gehören Snapshots über das Container Storage Interface (CSI) und Klone bestehender Daten-Volumes sowie die Unterstützung von OpenShift-APIs zur Wiederherstellung von Daten und Anwendungen in Container-Pods und zur Wiederherstellung von Verbindungen zwischen Namespaces und persistenten Daten.
Um Kubernetes-Ressourcen und interne Images auf Namensraumebene zu sichern und wiederherzustellen, nutzt das OpenShift API for Data Protection (OADP) die Velero-Version 1.7. Dabei werden die Persistent Volumes mittels Snapshots gesichert und auch wiederhergestellt. Die Backups lassen sich in dedizierten Intervallen konfigurieren.
Admins können Hooks verwenden, um Befehle in einem Container auf einem Pod auszuführen, zum Beispiel fsfreezezum Einfrieren eines Dateisystems. Sie können einen Hook so konfigurieren, dass er vor oder nach einer Sicherung oder Wiederherstellung ausgeführt wird. Wiederherstellungs-Hooks können in einem Init-Container oder im Anwendungscontainer ausgeführt werden.
Red Hat gibt auf seiner Webseite Tipps, wie sich etcd am besten sichern lässt und welche Befehle dafür notwendig sind. Details zu den OADP-Features und Plug-ins sind ebenso zu finden wie ein Überblick über die Backup- und Restore-Funktionen der OpenShift Container Platform 4.12 und darunter liegenden Versionen.
Rubrik for Kubernetes
Mit Rubrik for Kubernetes lassen sich Anwendungsdaten persistenter Datenträger am lokalen Standort oder in der Cloud speichern und von dort auch wiederherstellen. Dabei handelt es sich um ein natives objektbasiertes Kubernetes-Backup und Restore. Durch die Replikation von Namespaces auf einen anderen Cluster lassen sich interne Tests für die Entwicklung umsetzen.
Die Lösung offeriert bietet Cloud-basierte, unveränderliche Backups für Kubernetes-Umgebungen. Die SaaS-Plattform sichert die persistenten Volumes und Objekte auf dem ursprünglichen Cluster oder in der neuen Bereitstellung. Das Management und die Konfiguration erfolgen über eine globale Verwaltungskonsole, die zudem Einblick in die verteilten Bereitstellungen, die Workload-Leistung und die Einhaltung von SLAs gewährt.
Zu den Funktionen gehören unter anderem:
- Unveränderliche (Immutable) Backups mit Air-Gap sichern Anwendungsdaten und deren Abhängigkeiten. Multifaktor-Authentifizierung mit granularer rollenbasierter Zugriffskontrolle verhindert unbefugte Änderungen, Verschlüsselung oder Löschung.
- Wiederverwendbare SLAs können Clustern und Namespaces zugewiesen werden, um Ihre Effizienz zu verbessern.
- Die automatische Erkennung von Kubernetes-Umgebungen ermöglicht eine vollständige Data Protection.
- Flexibilität bei der Festlegung der Häufigkeit und Aufbewahrung von Snapshots ermöglicht die Anpassung an unterschiedliche Anwendungsanforderungen.
- Schutz für Kubernetes-Workloads in Private und Public Clouds bietet Unterstützung für Multi-Cloud-Umgebungen
- Replizieren Sie Backup-Daten für Disaster Recovery und verwenden Sie diese für Anwendungsausfälle bei einem Störfall.
- Archivieren Sie den Zustand von Kubernetes-Objekten und PV-Snapshots in der Cloud und bewahren Sie sie für die Einhaltung von Gesetzen und Vorschriften auf.
- Erweiterung der Rubrik-Data-Resilience als APIs, um Befehle auf Kubernetes-Cluster für Backup- und Recovery-Operationen auszuführen.
- Unterstützte Kubernetes-Distributionen: RedHat OpenShift, VMware Tanzu, AWS AKS, Azure EKS.
Das Datenblatt (in Englisch) ist unter diesem Link zu finden. Was die Security Cloud des Herstellers zum Backup von Kubernetes-Daten beitragen kann, wird hier erklärt. Darüber hinaus stehen weitere Informationen in Form von Blogs wie diesem zur Verfügung. Warum die Sicherung von Kubernetes-Daten ein wichtiges Element der Disaster-Recovery-Strategie ist, erklärt der Hersteller auf seiner Webseite.
TrilioVault for Kubernetes
Trilio positioniert sein Tool TrilioVault als Cloud-native Datensicherung für Kubernetes. Trilio behauptet, anwendungsorientiert zu sein, und bietet eine breite Palette an Kubernetes-Plattform- und Cloud-Unterstützung. Das Tool nutzt zentrale Kubernetes-APIs und das CSI-Framework, während die Verwaltungskonsole die Erkennung von Anwendungen sowie die Verwaltung von Sicherungs-, Wiederherstellungs- und DR-Richtlinien unterstützt. Das Tool unterstützt auch Snapshots. Die dabei verwendeten Backup-Images sind QCOW2-Images.
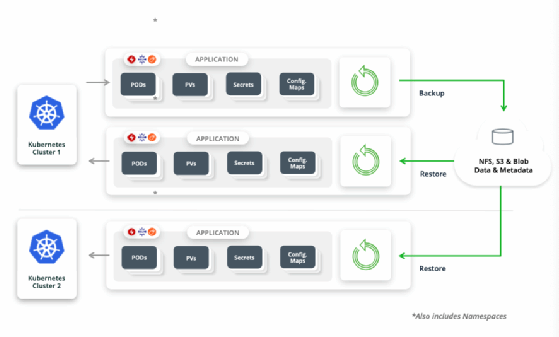
Die Funktionsliste von TrilioVault enthät unter anderem dies:
- Operator- und Helm-basierte Bereitstellung
- Unterstützte Anwendungen: Helm-Charts, Operatoren, Custom Labels, Namespaces
- Anwendungsbezogene Backup-Policies
- Integration von Prometheus und Grafana
- Rollenbasierte Zugriffskontrolle (RBAC)
- Offenes Backup-Format (QCOW2), das keine Hydration beim Verschieben der Backup-Daten erfordert. Daten lassen sich aus Sicherheitsperspektive durchscannen.
- Deduplizierung und inkrementelle Backups
- Mehrere Backup-Ziele möglich (NFS und S3)
- Incremental Forever
- Hooks
- Vorhaltungsplan für Backup-Daten
- Multi-Cloud-Management
- Verschlüsselung
- Backup Immutability
- Authentifizierung mittels OIDC/LDAP
- Klonen und Verteilen über Cluster und Namensräume hinweg
- Restore Cleanup: Benachrichtigung und Löschung fehlgeschlagener Restores
TrilioVault ist für eine Reihe von Implementierungen zertifiziert, darunter auf HPE, Red Hat OpenShift, VMWare Tanzu und Rancher.
Weitere Details listet das Datenblatt auf. Darüber hinaus gibt es Dokumentationen zur Durchführung von Backups und Restores, zum generellen Lösungsüberblick sowie zum Recovery von Kubernetes und OpenStack.
Velero
Verelo ist ein Open-Source-Tool für Backup, Restore, Recovery und Migration für Kubernetes. Es kann ganze Cluster oder Teile davon sowie Persistent Volumes sichern, indem es Namespaces und Label-Selektoren verwendet. Das Tool kann jetzt auch Kubernetes-API-Gruppen nach Prioritätsstufe wiederherstellen. Velero war zuvor Heptio Ark.
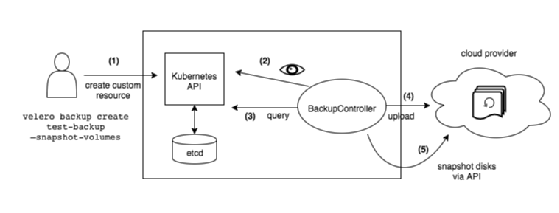
Die Lösung besteht aus einem Server, der auf dem Cluster operiert, und einem Command Line Client, der lokal läuft. Um sich mit beliebigen Speichersystemen zu verbinden, nutzt Velero entsprechende Plug-ins. Dafür können Anwender notwendige Plug-ins einfach hinzufügen, nachdem Velero installiert wurde. Als Bacup-Formate kommen JSON File und Output File Format Versioning. API-Typen gibt es für Backup, Restore, Schedule, BackupStorageLocation und VolumeSnapshotLocation.
Anwender können unter anderem diese Funktionen nutzen:
- Datensicherung bei Bedarf (On-Demand Backup)
- Planung von Backups (Scheduled Backups)
- Restore Workflow
- Sicherung von API-Versionen
- Verfallsdaten für Backups festlegen
- Objektspeichersynchronisation
Obwohl Velero Open Source ist, wird es von VMWare unterstützt, und der Hersteller hat eine Reihe von Velero-Ressourcen in seinem Tanzu-Entwicklerzentrum. Es ist ebenso eine Integration mit DigitalOcean möglich. Die aktuelle Version ist Velero 1.8. Details zur Funktionsweise sind in dieser Dokumentation des Anbieters nachzulesen. Installationsinformationen bietet diese Dokumentation. Auch GitHub bietet weiterführende Details auf seiner Webseite.
Veritas
Die NetBackup-Tools von Veritas unterstützen eine Reihe von Sicherungs-, Wiederherstellungs- und Business-Continuity-Optionen für Kubernetes. Neben Standard-Backups unterstützt Veritas den Schutz vor Ransomware über unveränderliche Backups auf AWS S3 und die Kubernetes-Datenverwaltung mit integrierter Disaster Recovery. Veritas gibt an, dass seine Tools es den Nutzern ermöglichen, zwischen Kubernetes-Distributionen zu wechseln, um einen Backup-einmal, Wiederherstellung von und nach überall-Ansatz zu verfolgen.
Die Software nutzt etcd-Snapshots, um Backup-Kopien von etcd-Datenbanken anzulegen. Die Sicherungen sind anwendungskonsistent. Für ein erfolgreiches Recovery müssen auch die etcd-Datenbanken wiederhergestellt werden, die alle Clusterinformationen enthalten.
Darüber hinaus sollen die Lösungen Veritas Alta Application Resiliency und Veritas Alta Shared Storage Resilienz und Speichermanagement für Kubernetes gewährleisten. Sie bieten softwaredefinierten, persistenten Speicher sowie Resilienzfunktionen für zustandsabhängige containerisierte Anwendungen in Kubernetes-Umgebungen bilden.
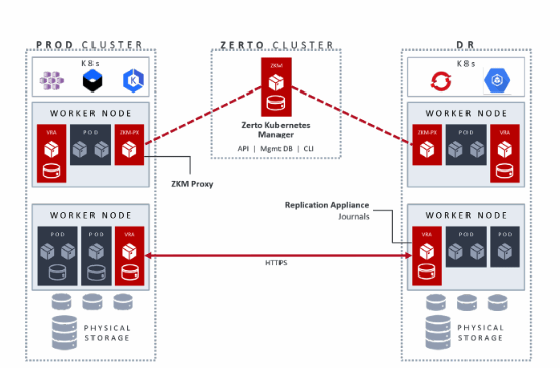
Die Resiliency-Software umfasst einen Disaster-Recovery-Manager, der eine Migration von Kubernetes-Cluster erlaubt, die dann für Wiederherstellungen genutzt werden können. Optimierte Replikationen sorgen für das Bewahren der richtigen Schreibreihenfolge (write-order fidelity) und repliziert den Anwendungsstatus und die Metadaten. Die Replikation kann synchron oder asynchron erfolgen.
Mit der Funktion Fire Drill können Admins unterbrechungsfrei testen und validieren, ob sich die Anwendungen am DR-Standort im Falle eines Ausfalls des Primärstandorts wiederherstellen und online gestellt werden können.
Die Shared-Storage-Lösung schützt vor Datenkorruptionen, die durch ein Split-Brain-Szenario entstehen. Dieses Szenario kann in jeder Cluster-Umgebung auftreten, wenn bei einem Knoten- oder Hardwareausfall die Cluster-Kommunikation und Mitgliedschaft am Cluster unterbrochen wird. Veritas Alta Shared Storage bietet I/O-Fencing-Funktionen mittels eines Treiber-Containers, der für die Verwaltung des Fencing Prozess verantwortlich ist. Das verhindert, dass Daten von Cluster-Nodes geschrieben werden, die aufgrund von Hardware- oder Netzwerkkommunikationsproblemen ausgefallen sind. Wenn ein Knotenausfall von Kubernetes erkannt wird, kann der Fencing-Treiber sicherstellen, dass die Persistent Volumes, die von Anwendungs-Pods auf dem ausgefallenen Knoten verwendet werden, nicht mehr zugänglich sind und dieser Knoten aus dem Cluster ausgeschlossen werden. Bei einem Kommunikationsverlust zwischen Cluster-Knoten (auch Worker Nodes genannt) leitet der Fencing-Treiber diese Informationen an den Kubernetes-Master weiter, der den Knoten dann als ausgefallen markieren und Pods auf einen anderen Knoten verschieben kann.
Der Software-definierte Speicher (SDS) wird über das Container Storage Interface bereitgestellt. Damit lassen sich Speicher-Volumes mithilfe von Cloud-nativen Blockspeicherdiensten einrichten. Die persistenten Volumes können dynamisch oder statisch bereitgestellt werden. Darüber hinaus kann der Admin weitere Funktionen nutzen:
- Verschiedene Datenzugriffe: ReadWriteOnce (RWO), ReadOnceMany (ROM), ReadWriteMany (RWX)
- Verschlüsselung
- Snapshots
- Volume-Klone
Allgemeine und detaillierte Informationen zu NetBackup und den Alta-Angeboten sind auf der Webseite des Herstellerszu entdecken.
Zerto
Zerto for Kubernetes integriert Backup, Disaster Recovery und Mobilität in den Lebenszyklus der Anwendungsentwicklung, unabhängig ob am eigenen Standort oder in der Cloud, und ermöglicht so Data Protection as Code. Anstatt einen Snapshot des zugrunde liegenden Speichers oder der VMs, auf denen die Container laufen, zu erstellen, schützt die Lösung die gesamte Anwendung als native Kubernetes-Entität, einschließlich der persistenten Volumes und aller zugehörigen Ressourcendefinitionen, Konfigurationen und Dienste. Restores und Recoverys werden von einem konsistenten Zeitpunkt aus über alle Ressourcen hinweg orchestriert, unabhängig davon, ob es sich um Deployments oder StatefulSets handelt oder ob unterschiedliche Speicherklassen und CSI-Anbieter verwendet werden.
Zerto-Komponenten laufen als Pods on Worker Nodes, ohne dass dafür etwas auf der Kubernetes Control Plane installiert werden muss. Daten können innerhalb eines Clusters oder über Cluster hinweg repliziert werden. Die PVs nutzt die Lösung für ein Journaling, sodass granulare Wiederherstellungen von Kubernetes-Workloads realisierbar sind.
Zerto für Kubernetes ist derzeit für Azure Kubernetes Service, AWS Elastic Kubernetes Service, Google Kubernetes Engine, IBM Cloud Kubernetes Service, Red Hat OpenShift und VMware Tanzu verfügbar. Anders als die meisten anderen Anbieter nutzt Zerto seine CDP-Technologie (Continious Data Protection) anstatt Snapshots.
Zu den Kernkomponenten der Zerto-Lösung gehören:
- Zerto Kubernetes Manager (ZKM)
- Zerto Kubernetes Manager Proxy (ZKM-PX)
- Virtual Replication Application (VRA)
- Networking
- Keycloak (Identity and Access Management)
- Virtual Protection Group (VPG)
- Journaling
- Long-Term Retention (LTR) Repositories
Die detaillierte Dokumentation zur Architektur ist in diesem Datenblatt beschrieben. Darüber hinaus gibt es hier eine Kurzbeschreibung der Lösung.
Kubernetes-natives vs. allgemeines Backup: Vorsicht vor Verdoppelung
Die Wahl der besten Sicherungs- und Wiederherstellungsoptionen für Kubernetes ist jedoch nicht immer einfach, und Unternehmen werden möglicherweise feststellen, dass sie mehr als ein Tool zum Schutz ihrer Installationen benötigen.
„Viele der eigenständigen nativen Kubernetes-Backup-Tools werden von DevOps-Teams direkt erworben“, sagt Ellis von Forrester. „Es ist nicht ungewöhnlich, dass ein Kauf von TrillioVault oder Kasten von einem Produktteam initiiert wird. Umfassendere Backup-Tools werden immer noch vom CIO und seinem Team gekauft, und das Verständnis für den Bedarf an Kubernetes-nativem Backup in diesem Teil der Organisation hinkt ein wenig hinterher.“
CIOs müssen die umfangreichere Funktionalität und die detaillierteren Kontrollen nativer Kubernetes-Tools mit der besseren unternehmensweiten Übersicht über Anwendungen und Daten abwägen, die von allgemeinen, aber containerfähigen Backup-Tools geboten wird.
„Bei den umfassenden Backup-Tools wird das native Kubernetes-Backup meines Erachtens als Tabellenkalkulation betrachtet“, erklärt Ellis. „Fast alle Anbieter auf Unternehmensebene behaupten, Kubernetes sichern zu können, aber nicht alle tun es nativ.“
Erfahren Sie mehr über Containervirtualisierung
-
![]()
Google Anthos: Storage für Kubernetes-Umgebungen
Von: Thomas Joos
-
![]()
Longhorn: Blockspeicher im Cluster ohne externes SAN
Von: Thomas Joos
-
![]()
Google Cloud Storage: Den CSI-Treiber für GKE installieren
Von: Ulrike Rieß-Marchive
-
![]()
Mit diesen Tools können Sie Kubernetes-Backups umsetzen
Von: Ulrike Rieß-Marchive



