Amazon Simple Storage Service (Amazon S3)
Was ist Amazon Simple Storage Service (Amazon S3)?
Amazon Simple Storage Service (Amazon S3) ist ein skalierbarer, schneller, webbasierter Cloud Storage Service. Der Service ist für die Online-Sicherung und Archivierung von Daten und Anwendungen auf Amazon Web Services (AWS) konzipiert. Um Entwicklern das Web-Scale-Computing zu erleichtern, Amazon wurde S3 mit einem minimalen Funktionsumfang entwickelt.
Was sind die Merkmale von Amazon S3?
S3 bietet eine Datenhaltbarkeit von 99,999999999 Prozent (Anbieterangaben) für im Service gespeicherte Objekte und unterstützt mehrere Sicherheits- und Compliance-Zertifizierungen. Ein Administrator kann S3 auch mit anderen AWS-Sicherheits- und Überwachungsdiensten verknüpfen, darunter CloudTrail, CloudWatch und Macie. Außerdem gibt es ein umfangreiches Partnernetzwerk von Anbietern, die ihre Dienste direkt mit S3 verknüpfen.
Daten können über das öffentliche Internet über den Zugang zu den S3-Programmierschnittstellen (APIs) auf S3-Plattformen übertragen werden. Darüber hinaus gibt es Amazon S3 Transfer Acceleration für eine schnellere Übertragung über große Entfernungen sowie AWS Direct Connect für eine private, konsistente Verbindung zwischen S3 und dem eigenen Rechenzentrum eines Unternehmens. Ein Administrator kann auch AWS Snowball, ein physisches Übertragungsgerät, verwenden, um große Datenmengen von einem Unternehmensrechenzentrum direkt zu AWS zu übertragen, das sie dann in S3 hochlädt. AWS Snowball Edge kann für die Migration von Bandspeichern zu S3 verwendet werden.
Darüber hinaus können Benutzer andere AWS-Dienste in S3 integrieren. So kann ein Analyst beispielsweise Daten direkt auf S3 abfragen, entweder mit Amazon Athena für Ad-hoc-Abfragen oder mit Amazon Redshift Spectrum für komplexere Analysen.
S3-Buckets können mit verschiedenen Tools und Plug-ins direkt in ein Dateisystem eingebunden werden. Amazon Mountpoint ist ein Beispiel für diese Tools, die von Amazon entwickelt wurden. Diese Tools übersetzen Dateisystemanfragen in S3-API-Anfragen. Dadurch kann S3 mit nicht-Cloud-nativen Tools verwendet werden. Da S3 mit ganzen Objekten gleichzeitig arbeitet, kann die Leistung oder Preisgestaltung je nach den Zugriffseigenschaften der Anwendung beeinträchtigt werden.
Welche Anwendungsfälle gibt es für Amazon S3?
Amazon S3 kann von Organisationen unterschiedlicher Größe genutzt werden, von kleinen Firmen bis hin zu Großunternehmen. Dank seiner Skalierbarkeit, Verfügbarkeit, Sicherheit und Leistungsfähigkeit eignet sich S3 für eine Vielzahl von Anwendungsfällen zur Datenspeicherung. Häufige Anwendungsfälle für S3 sind
- Daten-Storage.
- Datenarchivierung.
- Speicher für Dokumenten.
- Anwendungshosting für die Bereitstellung, Installation und Verwaltung von Webanwendungen.
- Software-Bereitstellung.
- Backup.
- Disaster Recovery (DR).
- Log File Storage.
- Big-Data-Analyse-Tools für gespeicherte Daten.
- Data Lakes und Data Warehouses.
- Mobile Anwendungen.
- Internet der Dinge (IoT)-Geräte.
- Medienhosting für Bilder, Videos und Musikdateien.
- Softwarebereitstellung.
- Website-Hosting - besonders gut geeignet für die Zusammenarbeit mit Amazon CloudFront für die Bereitstellung von Inhalten.
Wie funktioniert Amazon S3?
Amazon S3 ist ein Objektspeicherdienst, der sich von anderen Cloud-Computing-Speichertypen wie Block- undDateispeicher unterscheidet. Jedes Objekt wird als Datei mit den zugehörigen Metadaten gespeichert. Außerdem erhält das Objekt eine ID-Nummer. Die Daten sind nicht in Ordnern, sondern in Buckets organisiert. Anwendungen verwenden diese ID-Nummer, um auf Objekte zuzugreifen. Dies unterscheidet sich von Datei- und Block-Cloud-Speichern, bei denen ein Entwickler über eine REST-API (Representational State Transfer) auf ein Objekt zugreifen kann.
Der Cloud-Dienst S3 Object Storage bietet einem Abonnenten Zugang zu denselben Systemen, die Amazon für den Betrieb seiner Websites verwendet. Mit S3 können Kunden praktisch jede Datei oder jedes Objekt mit einer Größe von bis zu 5 Terabyte hochladen, speichern und herunterladen, wobei der größte einzelne Upload auf 5 Gigabyte (GB) begrenzt ist.

Was sind die Speicherklassen von Amazon S3?
Amazon S3 wird in sieben Speicherklassen angeboten:
- S3 Standard eignet sich für Daten, auf die häufig zugegriffen wird und die mit geringer Latenz und hohem Durchsatz bereitgestellt werden müssen. S3 Standard zielt auf Anwendungen, dynamische Websites, die Verteilung von Inhalten und Big Data Workloads ab.
- S3 Intelligent-Tiering eignet sich am besten für Daten, deren Zugriffsanforderungen sich ändern oder unbekannt sind. S3 Intelligent-Tiering hat vier verschiedene Zugriffsebenen: Frequent Access, Infrequent Access (IA), Archive und Deep Archive. Die Daten werden je nach Zugriffsmuster des Kunden automatisch auf die günstigste Speicherebene verschoben.
- S3 Standard-IA bietet einen niedrigeren Speicherpreis für Daten, die weniger häufig benötigt werden, aber schnell zugänglich sein müssen. Diese Ebene kann für Backups, DR und langfristige Datenspeicherung verwendet werden.
- S3 One Zone-IA ist für Daten gedacht, die selten genutzt werden, auf die aber bei Bedarf schnell zugegriffen werden muss. S3 One Zone-IA eignet sich für Daten, auf die nur selten zugegriffen wird und die keine hohen Anforderungen an Ausfallsicherheit oder Verfügbarkeit stellen, sowie für Daten, die vor Ort neu erstellt und gesichert werden können.
- S3 Glacier ist eine kostengünstige Speicheroption in S3, ist jedoch ausschließlich für die Archivierung gedacht, da der Zugriff auf die Daten länger dauert. Glacier bietet variable Abrufraten, die von Minuten bis Stunden reichen.
- S3 Glacier Deep Archive ist die preisgünstigste Option für S3-Speicher. S3 Glacier Deep Archive ist für die Aufbewahrung von Daten gedacht, auf die nur ein- oder zweimal im Jahr zugegriffen werden muss.
- S3 Outposts fügt S3-Objektspeicherfunktionen und APIs zu einer AWS Outposts-Umgebung vor Ort hinzu. S3 Outposts eignet sich am besten, wenn Daten aufgrund von Leistungsanforderungen in der Nähe von lokalen Anwendungen gespeichert werden müssen oder um bestimmte Anforderungen an die Datenresidenz zu erfüllen.
Ein Benutzer kann auch Lebenszyklus-Management-Richtlinien implementieren, um Daten zu kuratieren und sie im Laufe der Zeit auf die am besten geeignete Ebene zu verschieben.
So arbeiten Sie mit S3-Buckets
Amazon legt keine Begrenzung für die Anzahl der Elemente fest, die ein Abonnent speichern kann; es gibt jedoch eine Begrenzung für die Anzahl der Amazon S3-Buckets. Für jedes AWS-Konto können standardmäßig bis zu 100 Buckets erstellt werden; die Limits können auf 1.000 erhöht werden, indem eine Erhöhung des Service-Limits beantragt wird.
Ein Amazon S3-Bucket existiert innerhalb einer bestimmten Region der Cloud. Ein AWS-Kunde kann eine Amazon S3-API verwenden, um Objekte in einen bestimmten Bucket hochzuladen. Kunden können S3-Buckets konfigurieren und verwalten.

So schützen Sie Ihre S3-Daten
Benutzerdaten werden auf redundanten Servern in multiplen Rechenzentren gespeichert. S3 nutzt eine einfache webbasierte Schnittstelle – die Amazon S3-Konsole – und Verschlüsselung für die Benutzerauthentifizierung.
S3-Buckets werden standardmäßig vor öffentlichem Zugriff geschützt, aber ein Administrator kann sie auch öffentlich zugänglich machen. Ein Benutzer kann die Daten auch vor der Speicherung verschlüsseln. Für einzelne Benutzer können Rechte festgelegt werden. Diese benötigen dann genehmigte AWS-Anmeldedaten, um eine Datei in S3 herunterzuladen oder darauf zuzugreifen. Unzureichend gesicherte S3-Daten waren eine der Hauptquellen für Datenlecks.
S3 verfügt über eine starke Datenkonsistenz. PUT-Anforderungen für Objekte werden auf Objektebene verarbeitet. Wenn zwei PUT-Anfragen für ein Objekt gestellt werden, gewinnt diejenige mit dem späteren Zeitstempel. S3 unterstützt von Haus aus keine Objektsperre für gleichzeitige Schreibvorgänge. Die S3-Objektsperre kann jedoch in einem Modus oder in zwei Modi konfiguriert werden, um Objekte unveränderlich zu machen.
Wenn ein Benutzer Daten in S3 speichert, verfolgt Amazon die Nutzung zu Abrechnungszwecken, greift aber ansonsten nicht auf die Daten zu, es sei denn, es besteht eine gesetzliche Verpflichtung dazu.
Amazon S3 ist mit dem Payment Card Industry Data Security Standard und dem Health Insurance Portability and Accountability Act konform. Wenn es richtig konfiguriert ist, kann es zur Verarbeitung von Kreditkarten- und Gesundheitsdaten verwendet werden. Es ist auch mit verschiedenen anderen Compliance-Programmen kompatibel.

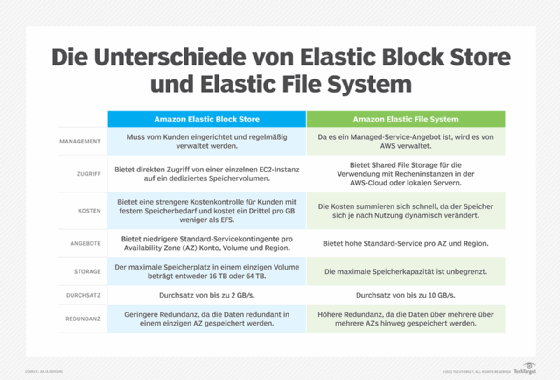
Amazon S3 vs. EBS vs. EFS
AWS bietet mehrere Speicherdienste an. EBS und EFS sind traditionelle Dateispeicher, während S3 ein Objektspeicher ist.
Amazon Elastic Block Storage (EBS) ist ein Dateisystem-Blockspeicher, der für die Verwendung durch eine virtuelle Maschine (VM) der Amazon Elastic Compute Cloud (EC2) vorgesehen ist. EBS kann man sich wie die Festplatte eines Computers vorstellen. Normalerweise ist jede EBS-Instanz nur mit einer EC2-Instanz verbunden. EBS bietet die höchste Lese-/Schreibleistung.
Amazon Elastic File System (EFS) ist ein gemeinsam genutzter Dateispeicher, der an mehrere EC2-Instanzen angeschlossen werden kann. Man kann es sich wie ein gemeinsames Laufwerk vorstellen, auf das viele Computer Zugriff haben. Die Speichergröße eines EFS-Volumes wächst und schrumpft dynamisch nach Bedarf.
Amazon S3 ist ein Objektspeicher. Er ist normalerweise nicht mit einer VM verbunden, sondern wird von einer Anwendung genutzt. So kann eine Anwendung beispielsweise ihre Protokolle an einen S3-Bucket senden, und eine andere Analyseanwendung kann die Protokolle dann lesen. S3 kann auch abgefragt werden, ähnlich wie eine Datenbank, was es zu einem hervorragenden Werkzeug für Data Warehouses und Data Lakes macht.
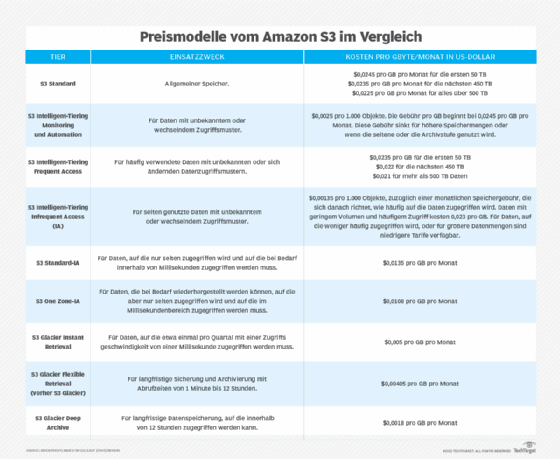
Amazon S3-Preise
Die Preisgestaltung von Amazon S3 kann kompliziert zu prognostizieren sein. Es gibt eine Gebühr für den Speicher, für den Objektzugriff und für Dateneingangs- und -ausgangsgebühren.
Die Preise für S3-Speicher werden nach Gigabyte pro Monat berechnet. Der Preis ändert sich je nach verwendetem Storage Tier oder je nachdem, wie oft auf die Daten zugegriffen wird. Die leicht zugänglichen Speicherebenen kosten möglicherweise nur wenige Cent pro GB im Monat. Bei den Backup Tiers dauert es länger, bis die Daten abgerufen werden, aber sie können Bruchteile eines Cents pro Monat und GB kosten.
Datenanfragen und -abrufe werden ebenfalls über den API-Aufruf abgerechnet. Sie werden als Bruchteile eines Cents pro 1.000 Anfragen berechnet. Aufrufe zur Ermittlung des Datenbestands (GET, SELECT) sind billiger als Aufrufe zur Änderung der Daten (PUT, COPY, POST, LIST). Alle Aufrufe an S3 sind kostenpflichtig, auch wenn ein Administrator eine Dateiliste einsehen möchte.
Für S3-Aufrufe können zusätzliche Gebühren für den Dateneingang und -ausgang anfallen. Diese werden pro übertragenem GB berechnet. Die genauen Kosten können von der übertragenen Menge und den beteiligten Standorten abhängen.
Amazon bietet einen einfachen Preiskalkulator an, mit dem Unternehmen ihre Rechnung abschätzen können. Aufgrund der komplizierten Natur der Elemente und der Nutzungsabrechnung kann es schwierig sein, die Kosten für eine neue Anwendung vorherzusagen. Es ist wichtig, dass die Anwendung für S3 optimiert wird, um redundante Aufrufe zu vermeiden und die Kosten niedrig zu halten.
Konkurrierende Dienste zu Amazon S3
Zu den Konkurrenzdiensten von Amazon S3 gehören auch andere Objektspeicher-Software-Tool-Dienste. Große Cloud-Service-Anbieter wie Google, Microsoft, IBM und Alibaba bieten vergleichbare Objektspeicherdienste an. Zu den wichtigsten Konkurrenzdiensten von Amazon S3 gehören die folgenden:
- Google Cloud Storage.
- Azure Blob-Speicher.
- IBM Cloud Object Storage.
- DigitalOcean Spaces.
- Alibaba Cloud Object Storage Service.
- Cloudian.
- Zadara Storage.
- Oracle Cloud Infrastructure Object Storage.






