Data Lake
Was ist ein Data Lake?
Ein Data Lake ist ein Speicherort, an dem große Mengen an Rohdaten in ihrem ursprünglichen Format gespeichert werden, bis sie für Analyseanwendungen benötigt werden. Während ein herkömmliches Data Warehouse Daten in hierarchischen Dimensionen und Tabellen speichert, verwendet ein Data Lake eine flache Architektur, um Daten vor allem in Dateien oder Objektspeichern zu speichern. Das bietet Anwendern mehr Flexibilität bei der Datenverwaltung, -speicherung und -nutzung.
Data Lakes werden häufig mit Hadoop-Systemen in Verbindung gebracht. Bei Implementierungen auf Basis des verteilten Verarbeitungssystems werden Daten in das Hadoop Distributed File System (HDFS) geladen und auf den verschiedenen Computerknoten in einem Hadoop-Cluster gespeichert. Zunehmend werden Data Lakes jedoch auf Cloud-Objektspeicherdiensten anstelle von Hadoop aufgebaut. Einige NoSQL-Datenbanken werden ebenfalls als Data-Lake-Plattformen verwendet.
Wie funktioniert ein Data Lake?
Ein Data Lake speichert große Mengen strukturierter und unstrukturierter Daten im Rohformat. Dies gibt Unternehmen die Flexibilität, Daten ohne sofortige Verarbeitung zu speichern, wodurch es einfacher wird, Daten aus verschiedenen Quellen zu untersuchen und zu sammeln.
Data Lakes verwenden häufig Metadatenmanagement, Indizierung sowie Machine Learning (ML) und Visualisierungs-Tools, um die Genauigkeit und Leistung für Benutzer bei der Datenabfrage zu verbessern. Ein gut strukturierter Data Lake umfasst häufig auch Governance-Kontrollen, Sicherheitsmaßnahmen und optimierte Speichertechniken, um Zugänglichkeit und Kosteneffizienz in Einklang zu bringen.
Data Lakes können auch skalierbare Cloud-basierte, lokale oder hybride Speicherressourcen nutzen, mit denen Unternehmen schnell wachsende Datenmengen verarbeiten und gleichzeitig die Sicherheit und Zugänglichkeit der Daten gewährleisten können.
Warum verwenden Unternehmen Data Lakes?
Data Lakes speichern in der Regel große Datenmengen, die eine Kombination aus strukturierten, unstrukturierten und semistrukturierten Daten umfassen können. Solche Umgebungen eignen sich nicht gut für relationale Datenbanken, auf denen die meisten Data Warehouses basieren.
Relationale Systeme erfordern ein starres Schema für Daten, wodurch sie in der Regel auf die Speicherung strukturierter Transaktionsdaten beschränkt sind. Data Lakes unterstützen verschiedene Schemata und erfordern keine vorherige Definition. Dadurch können sie verschiedene Datentypen in unterschiedlichen Formaten verarbeiten.
Daher sind Data Lakes in vielen Unternehmen eine wichtige Komponente der Datenarchitektur. Unternehmen nutzen sie in erster Linie als Plattform für Big-Data-Analysen und andere Data-Science-Anwendungen, die große Datenmengen erfordern und fortschrittliche Analysetechniken wie Data Mining, prädiktive Modellierung und maschinelles Lernen einsetzen.
Ein Data Lake bietet Datenwissenschaftlern und Analysten einen zentralen Ort, an dem sie relevante Daten finden, aufbereiten und analysieren können. Ohne einen Data Lake ist dieser Prozess wesentlich komplizierter. Außerdem ist es für Unternehmen schwieriger, ihre Datenbestände voll auszuschöpfen, um fundiertere Geschäftsentscheidungen und Strategien zu treffen.
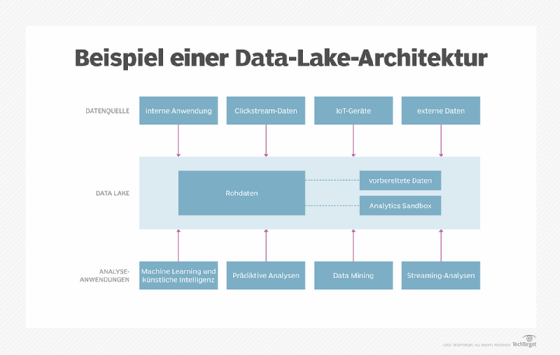
Data-Lake-Architektur
In Data Lakes kommen viele Technologien zum Einsatz, die von Unternehmen auf unterschiedliche Weise kombiniert werden können. Das bedeutet, dass die Architektur eines Data Lake oft von Unternehmen zu Unternehmen variiert. Ein Unternehmen kann beispielsweise Hadoop mit Spark und HBase, einer NoSQL-Datenbank, die auf HDFS läuft, einsetzen. Ein anderes kann Spark für Daten verwenden, die in Amazon Simple Storage Service (S3) gespeichert sind. Ein drittes kann sich für andere Technologien entscheiden.
Außerdem speichern nicht alle Data Lakes ausschließlich Rohdaten. Einige Datensätze werden möglicherweise bei der Erfassung gefiltert und für die Analyse verarbeitet. In diesem Fall muss die Data-Lake-Architektur dies ermöglichen und über ausreichende Speicherkapazität für die aufbereiteten Daten verfügen. Viele Data Lakes umfassen auch Analyse-Sandboxes und dedizierte Speicherbereiche, die einzelne Datenwissenschaftler für die Arbeit mit Daten nutzen können.
Drei wichtige Architekturprinzipien unterscheiden Data Lakes jedoch von herkömmlichen Daten-Repositorys:
- Es müssen keine Daten abgelehnt werden. Alle aus Quellsystemen gesammelten Daten können bei Bedarf in einen Data Lake geladen und dort gespeichert werden.
- Daten können in einem unveränderten oder nahezu unveränderten Zustand gespeichert werden, so wie sie aus dem Quellsystem empfangen wurden.
- Diese Daten werden später je nach den spezifischen Analyseanforderungen transformiert und in ein Schema eingefügt – ein Ansatz, der als Schema-on-Read bezeichnet wird.
Unabhängig davon, welche Technologie bei der Bereitstellung eines Data Lake zum Einsatz kommt, sollten einige weitere Elemente berücksichtigt werden, um sicherzustellen, dass der Data Lake funktionsfähig ist und die darin enthaltenen Daten nicht verloren gehen. Dazu gehören:
- Eine gemeinsame Ordnerstruktur mit Namenskonventionen.
- Ein durchsuchbarer Datenkatalog, der Benutzern hilft, Daten zu finden und zu verstehen.
- Eine Datenklassifizierungstaxonomie zur Identifizierung sensibler Daten mit Informationen wie Datentyp, Inhalt, Verwendungsszenarien und Gruppen möglicher Benutzer.
- Data Profiling Tools, die Einblicke für die Klassifizierung von Daten und die Identifizierung von Datenqualitätsproblemen liefern.
- Ein standardisierter Datenzugriffsprozess, um zu kontrollieren und zu verfolgen, wer auf Daten zugreift.
- Datensicherheitsmaßnahmen wie Datenmaskierung, Datenverschlüsselung und automatisierte Nutzungsüberwachung.
Das Bewusstsein der Benutzer eines Data Lake für die Daten ist ebenfalls wichtig, insbesondere wenn es sich um Geschäftsanwender handelt, die als Citizen Data Scientists fungieren. Die Benutzer sollten nicht nur in der Navigation im Data Lake geschult werden, sondern auch die richtigen Techniken für die Datenverwaltung und Datenqualität sowie die Data-Governance- und Nutzungsrichtlinien des Unternehmens verstehen.
Data Lake versus Data Warehouse
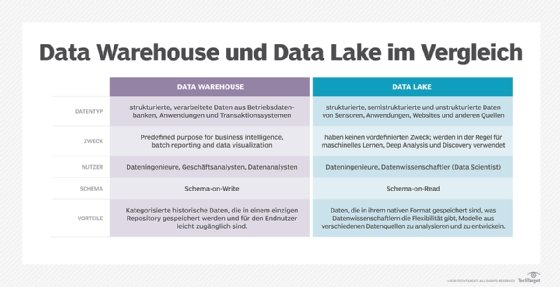
Die größten Unterschiede zwischen Data Lakes und Data Warehouses bestehen in der Unterstützung von Datentypen und ihrem Schema-Ansatz. In einem Data Warehouse, das in erster Linie strukturierte Daten speichert, ist das Schema für Datensätze vorgegeben, und es gibt einen Plan für die Verarbeitung, Transformation und Nutzung der Daten, wenn sie in das Warehouse geladen werden. Das ist in einem Data Lake nicht unbedingt der Fall. Es kann verschiedene Arten von Daten aufnehmen und benötigt weder ein definiertes Schema für diese Daten noch einen spezifischen Plan für deren Verwendung.
Um die Unterschiede zwischen den beiden Plattformen zu veranschaulichen, stellen Sie sich ein echtes Lagerhaus im Vergleich zu einem See vor. Ein See ist flüssig, veränderlich, formlos und wird von Flüssen, Bächen und anderen ungefilterten Wasserquellen gespeist. Im Gegensatz dazu ist ein Lagerhaus eine Struktur mit Regalen, Gängen und festgelegten Plätzen zur Aufbewahrung von Gegenständen, die gezielt für bestimmte Verwendungszwecke beschafft wurden.
Dieser konzeptionelle Unterschied zeigt sich in mehreren Aspekten, darunter die folgenden:
- Technologieplattformen. Eine Data-Warehouse-Architektur umfasst in der Regel eine relationale Datenbank, die auf einem herkömmlichen Server ausgeführt wird, während ein Data Lake typischerweise in einem Hadoop-Cluster oder einer anderen Big-Data-Umgebung bereitgestellt wird.
- Datenquellen. Die in einem Warehouse gespeicherten Daten werden in erster Linie aus internen Transaktionsverarbeitungsanwendungen extrahiert, um grundlegende Business Intelligence (BI) und Berichtsabfragen zu unterstützen, die häufig in zugehörigen Data Marts ausgeführt werden, die für bestimmte Abteilungen und Geschäftsbereiche erstellt wurden. Data Lakes speichern in der Regel eine Kombination aus Daten aus Geschäftsanwendungen und anderen internen und externen Quellen, wie Websites, Internet-of-Things-Geräten (IoT), sozialen Medien und mobilen Apps.
- Benutzer. Data Warehouses sind nützlich für die Analyse kuratierter Daten aus operativen Systemen durch Abfragen, die von einem BI-Team oder Business-Analysten und anderen Self-Service-BI-Benutzern geschrieben wurden. Da die Daten in einem Data Lake oft nicht kuratiert sind und aus verschiedenen Quellen stammen können, sind sie in der Regel nicht für den durchschnittlichen BI-Benutzer geeignet. Stattdessen eignen sich Data Lakes besser für Datenwissenschaftler, die über die Fähigkeiten verfügen, die Daten zu sortieren und ihnen Bedeutung zu entnehmen.
- Datenqualität. Die Daten in einem Data Warehouse gelten in der Regel als Single Source of Truth, da sie konsolidiert, vorverarbeitet und bereinigt wurden, um Fehler zu finden und zu beheben. Die Daten in einem Data Lake sind weniger zuverlässig, da sie oft aus verschiedenen Quellen unverändert übernommen und in ihrem Rohzustand belassen werden, ohne zuvor auf Genauigkeit und Konsistenz überprüft zu werden.
- Agilität und Skalierbarkeit. Data Lakes sind äußerst agile Plattformen: Da sie handelsübliche Hardware verwenden, können die meisten von ihnen neu konfiguriert und erweitert werden, um sich an veränderte Datenanforderungen und Geschäftsbedürfnisse anzupassen. Data Warehouses sind aufgrund ihres starren Schemas und der vorbereiteten Datensätze weniger flexibel.
- Sicherheit. Data Warehouses verfügen über ausgereiftere Sicherheitsvorkehrungen, da sie schon länger existieren und in der Regel auf Mainstream-Technologien basieren, die ebenfalls seit Jahrzehnten im Einsatz sind. Die Sicherheitsmethoden für Data Lakes werden jedoch ständig verbessert, und mittlerweile sind verschiedene Sicherheits-Frameworks und -Tools für Big-Data-Umgebungen verfügbar.
Aufgrund ihrer Unterschiede verwenden viele Unternehmen sowohl ein Data Warehouse als auch einen Data Lake, häufig in einer hybriden Bereitstellung, die beide Plattformen integriert. Häufig sind Data Lakes eine Ergänzung zur Datenarchitektur und zur Datenmanagementstrategie eines Unternehmens und ersetzen nicht das Data Warehouse.
Was ist ein Data Lakehouse?
Ein Data Lakehouse ist eine Mischung aus einem Data Lake und einem herkömmlichen Data Warehouse. Data Lakehouses behalten die Skalierbarkeit und Flexibilität eines Data Lakes bei und bieten gleichzeitig strukturierte Datenmanagementfunktionen für eine verbesserte Leistung. Das bedeutet, dass Unternehmen unstrukturierte Rohdaten speichern und bei Bedarf Schemata und Transaktionsfunktionen anwenden können.
Ein Data Lakehouse kombiniert die Vorteile eines Data Lakes und eines Data Warehouses, um die Datenzuverlässigkeit zu verbessern und die Analyse zu vereinfachen. Es ermöglicht Benutzern den effizienten Zugriff auf riesige Datensätze, ohne die Geschwindigkeit und Genauigkeit zu beeinträchtigen, die normalerweise mit traditionellen Data Warehouses verbunden sind. Diese Architektur wird zunehmend für die Verarbeitung großer BI- und ML-Workloads bevorzugt.
Cloud versus On-Premises Data Lake
Anfangs wurden die meisten Data Lakes in lokalen Rechenzentren bereitgestellt. Mittlerweile sind sie jedoch in vielen Unternehmen Teil der Cloud-Datenarchitekturen.
Der Wandel begann mit der Einführung von Cloud-Big-Data-Plattformen und Managed Services, die Hadoop, Spark und verschiedene andere Technologien integrierten. Insbesondere die Marktführer im Bereich Cloud-Plattformen, AWS, Microsoft und Google, bieten Big-Data-Technologiepakete an: Amazon Elastic MapReduce (EMR), Azure HDInsight und Google Dataproc.
Die Verfügbarkeit von Cloud-Objektspeicherdiensten wie S3, Azure Blob Storage und Google Cloud Storage bot Unternehmen kostengünstigere Alternativen zu HDFS für die Datenspeicherung, wodurch die Bereitstellung von Data Lakes in der Cloud finanziell attraktiver wurde. Cloud-Anbieter fügten außerdem Data-Lake-Entwicklungs-, Datenintegrations- und andere Datenmanagementdienste hinzu, um die Bereitstellung zu automatisieren. Selbst Cloudera, ein Pionier im Bereich Hadoop, der 2019 noch etwa 90 Prozent seines Umsatzes mit On-Premises-Nutzern erzielte, bietet mittlerweile eine Cloud-native Plattform an, die sowohl Objektspeicher als auch HDFS unterstützt.
Was sind die Vorteile eines Data Lakes?
Data Lakes bilden die Grundlage für Data Science und fortschrittliche Analyseanwendungen. Auf diese Weise unterstützen sie Unternehmen, ihre Geschäftsabläufe effektiver zu verwalten und Geschäftstrends und -chancen zu erkennen. So kann ein Unternehmen beispielsweise Vorhersagemodelle zum Kaufverhalten seiner Kunden nutzen, um seine Online-Werbung und Marketingkampagnen zu verbessern. Analysen in einem Data Lake können auch beim Risikomanagement, bei der Betrugserkennung, der Wartung von Geräten und anderen Geschäftsfunktionen helfen.
Wie Data Warehouses tragen auch Data Lakes dazu bei, Datensilos aufzubrechen, indem sie Datensätze aus verschiedenen Systemen in einem einzigen Repository zusammenführen. Dadurch erhalten Data-Science-Teams einen vollständigen Überblick über die verfügbaren Daten und können relevante Daten einfacher finden und für Analysezwecke aufbereiten. Außerdem können IT- und Datenmanagementkosten gesenkt werden, da doppelte Datenplattformen im Unternehmen entfallen.
Ein Data Lake bietet noch weitere Vorteile, darunter die folgenden:
- Sie ermöglichen es Datenwissenschaftlern und anderen Benutzern, Datenmodelle, Analyseanwendungen und Abfragen spontan zu erstellen.
- Data Lakes sind relativ kostengünstig zu implementieren, da Hadoop, Spark und viele andere Technologien, die zu ihrer Erstellung verwendet werden, Open Source sind und auf kostengünstiger Hardware installiert werden können.
- Arbeitsintensive Schema-Entwürfe sowie Datenbereinigung, -transformation und -aufbereitung können aufgeschoben werden, bis ein klarer Geschäftsbedarf für die Daten besteht.
- In Data-Lake-Umgebungen können verschiedene Analysemethoden eingesetzt werden, darunter prädiktive Modellierung, maschinelles Lernen, statistische Analysen, Text Mining, Echtzeitanalysen und SQL-Abfragen.
Welche Herausforderungen bringen Data Lakes mit sich?
Trotz der geschäftlichen Vorteile, die Data Lakes bieten, kann ihre Bereitstellung und Verwaltung ein schwieriger Prozess sein. Hier sind einige der Herausforderungen, die Data Lakes für Unternehmen mit sich bringen:
- Datensümpfe. Eine der größten Herausforderungen besteht darin, zu verhindern, dass ein Data Lake zu einem Datensumpf wird. Wenn er nicht richtig eingerichtet und verwaltet wird, kann der Data Lake zu einer unübersichtlichen Datenhalde werden. Benutzer finden möglicherweise nicht das, was sie suchen, und Datenmanager verlieren möglicherweise den Überblick über die im Data Lake gespeicherten Daten, selbst wenn immer mehr Daten hinzukommen.
- Technologieüberlastung. Die Vielzahl der in Data Lakes verwendeten Technologien erschwert ebenfalls die Bereitstellung. Zunächst müssen Unternehmen die richtige Kombination von Technologien finden, um ihre speziellen Anforderungen an die Datenverwaltung und -analyse zu erfüllen. Anschließend müssen sie diese installieren, wobei der zunehmende Einsatz der Cloud diesen Schritt vereinfacht hat.
- Unerwartete Kosten. Die Vorabkosten für die Technologie sind zwar nicht unbedingt hoch, dies kann sich jedoch ändern, wenn Unternehmen ihre Data-Lake-Umgebungen nicht sorgfältig verwalten. Beispielsweise könnten Unternehmen überraschende Rechnungen für Cloud-basierte Data Lakes erhalten, wenn diese stärker als erwartet genutzt werden. Die Skalierung von Data Lakes zur Bewältigung der Arbeitslast erhöht ebenfalls die Kosten.
- Data Governance. Ein Zweck eines Data Lake besteht darin, Rohdaten für verschiedene Analysezwecke unverändert zu speichern. Ohne eine effektive Governance von Data Lakes können Unternehmen jedoch Probleme mit der Datenqualität, -konsistenz und -zuverlässigkeit auftreten. Diese Probleme können Analyseanwendungen behindern und zu fehlerhaften Ergebnissen führen, was wiederum schlechte Geschäftsentscheidungen zur Folge haben kann.
Anwendungsfälle für Data Lakes
Data Lakes werden in einer Vielzahl unterschiedlicher Branchen eingesetzt. Zu den häufigsten gehören die folgenden:
- Gesundheitswesen
- Finanzwesen und Bankwesen
- Einzelhandel und E-Commerce
- Fertigung und Lieferkette
- Medien und Unterhaltung
- Telekommunikation
- ML und KI
Anbieter von Data Lakes
Die Apache Software Foundation entwickelt Hadoop, Spark und andere Open-Source-Technologien, die in Data Lakes verwendet werden. Die Linux Foundation und andere Open-Source-Gruppen überwachen ebenfalls einige Data-Lake-Technologien.
Die Open-Source-Software kann kostenlos heruntergeladen und verwendet werden. Softwareanbieter bieten jedoch kommerzielle Versionen vieler Technologien an und bieten ihren Kunden technischen Support.
Einige Anbieter entwickeln und verkaufen auch proprietäre Data-Lake-Software.
Es gibt zahlreiche Anbieter von Data-Lake-Technologien, von denen einige komplette Plattformen anbieten und andere Tools zur Unterstützung der Bereitstellung und Verwaltung von Data Lakes. Zu den bekanntesten Anbietern gehören die folgenden:
- AWS. Zusätzlich zu Amazon EMR und S3 bietet AWS unterstützende Tools wie AWS Lake Formation zum Aufbau von Data Lakes und AWS Glue für die Datenintegration und -aufbereitung.
- Cloudera. Die Cloudera Data Platform kann in der Public Cloud oder in Hybrid-Cloud-Umgebungen mit lokalen Systemen bereitgestellt werden und wird von einem Data-Lake-Service unterstützt.
- Databricks. Das Unternehmen wurde von den Entwicklern von Spark gegründet und bietet eine Cloud-Data-Lakehouse-Plattform, die Elemente von Data Lakes und Data Warehouses kombiniert.
- Dremio. Das Unternehmen verkauft eine SQL-Lakehouse-Plattform, die das Design von BI-Dashboards und interaktive Abfragen in Data Lakes unterstützt und auch als vollständig gemanagter Cloud-Service verfügbar ist.
- Google. Es erweitert Dataproc und Google Cloud Storage um Google Cloud Data Fusion für die Datenintegration und eine Reihe von Services für die Verlagerung lokaler Data Lakes in die Cloud.
- HPE. Die HPE GreenLake-Plattform unterstützt Hadoop-Umgebungen in der Cloud und On-Premises mit Datei- und Objektspeicher sowie einem Spark-basierten Data Lakehouse-Dienst.
- Microsoft. Neben Azure HD Insight und Azure Blob Storage bietet das Unternehmen Azure Data Lake Storage Gen2, ein Repository, das Blob Storage um einen hierarchischen Namespace erweitert.
- Oracle. Zu den Cloud-Data-Lake-Technologien gehören ein Big-Data-Dienst für Hadoop- und Spark-Cluster, ein Objektspeicherdienst und eine Reihe von Datenmanagement-Tools.
- Qubole. Die Cloud-native Qubole-Data-Lake-Plattform bietet Funktionen für Datenmanagement, Engineering und Governance und unterstützt verschiedene Analyseanwendungen.
- Snowflake. Die Snowflake-Plattform ist zwar vor allem als Anbieter von Cloud-Data-Warehouses bekannt, unterstützt aber auch Data Lakes und kann mit Daten in Cloud-Objektspeichern arbeiten.







