
NicoElNino - stock.adobe.com
Die fünf wichtigsten Elemente eines modernen Data Warehouse
Klassische Data Warehouses können mit den schnell wachsenden Datenmengen nur schwer Schritt halten. Die hier vorgestellten fünf Funktionen erlauben es, BI umfassend zu nutzen.

Da Unternehmen eine einheitliche Sicht auf ihre Kunden und andere wichtige Unternehmensdaten anstreben, richten viele ein Data Warehouse als Ort ein, von dem alle ihre Daten beziehen. Das Data Warehouse bildet damit eine einzige Quelle der digitalen Wahrheit.
Eine Studie von TDWI, die 2021 veröffentlicht wurde, ergab, dass 53 Prozent der Unternehmen ein On-Premises Data Warehouse haben und 36 Prozent eines in der Cloud. Laut Gartner befinden sich 2022 75 Prozent aller Datenbanken in der Cloud, und 2023 wird der Umsatz mit Cloud-Datenbanken 50 Prozent des Gesamtmarktes ausmachen.
Die Verschiebung in Richtung Cloud wird also die nächsten Jahre bestimmen. Zu den gängigen Cloud-Datenbankmanagementsystemen (DBMS) und -Data-Warehouses gehören Amazon Redshift, Cloudera Data Warehouse, Databricks, Google BigQuery, Microsoft Azure Synapse, Snowflake Data Cloud und Teradata Vantage. Die beliebtesten On-Premises-Plattformen sind IBM DB2, Oracle Autonomous Database, Teradata Vantage, SAP HANA und Vertica – die jedoch auch in der Cloud eingesetzt werden können.
Data-Warehouse-Anbieter verfolgen eine breite Palette von Ansätzen für Analysen, maschinelles Lernen und künstliche Intelligenz (KI). Einige haben die fortschrittlichsten Tools direkt in ihre Systeme integriert und bieten sogar selbstkonfigurierende Funktionen für maschinelles Lernen (AutoML). Andere unterstützen die Vernetzung mit Data-Science-Plattformen und -Tools von Drittanbietern. Und wieder andere verlangen von den Unternehmen, dass sie ihre eigene Data Science betreiben.
„Einige Data Warehouses bieten nicht nur Informationsmanagement und Analysefunktionen. Sie verfügen auch über Orchestrierungsfunktionen“, sagt Amaresh Tripathy, Global Leader of Analytics bei Genpact, einem Beratungsunternehmen für digitale Transformation.
Dabei geht es nicht nur um das Sammeln von Daten und die Erstellung von Vorhersagen auf der Grundlage dieser Daten. Vielmehr ist damit auch das Senden von Ausführungsbefehlen an andere Systeme möglich, damit diese auf der Grundlage dieser Vorhersage Maßnahmen ergreifen. „Die nächste Generation von Data Warehouses wird all diese Funktionen integriert haben“, sagt Tripathy.
Fünf Merkmale eines erfolgreichen Data-Warehouse-Projekts
1. Optionen für die Bereitstellung in der Cloud und On-Premises
„Heute versuchen die meisten – aber nicht alle – Unternehmen, alte, On-Premises installierte Systeme in die Cloud zu verlagern“, erklärt Doug Henschen, Analyst bei Constellation Research.
Das bedeutet, dass Unternehmen, die eine Data-Warehouse-Plattform auswählen, prüfen sollten, ob das Data Warehouse in der von ihnen bevorzugten Cloud-Umgebung bereitgestellt werden kann oder als Service verfügbar ist. Unternehmen sollten auch prüfen, ob es eine On-Premises-Option gibt und ob diese mit der Cloud-Version kompatibel ist.
2. Data-Science-Fähigkeiten
Henschen zufolge unterstützt jedes Data Warehouse Standard-SQL-Abfragen. Die Unterstützung für Data Science ist jedoch sehr unterschiedlich. Einige Data Warehouses verfügen über integrierte fortschrittliche Analyse- und Data-Science-Funktionen, während andere Data Science dem Kunden überlassen.
Auch wenn diese Funktionen verfügbar sind, kann die Benutzerfreundlichkeit sehr unterschiedlich sein. „Richten sich diese Funktionen ausschließlich an Datenwissenschaftler, oder handelt es sich um AutoML-artige Funktionen, die von SQL-versierten Analysten und Power-Usern genutzt werden können?“ fragt Henschen mit Blick auf die Anwendungen.
Darüber hinaus sollten Unternehmen die Unterstützung des Produkts für Data-Science-Plattformen und Ökosysteme von Drittanbietern prüfen.
3. Leistungsfähigkeit
Die wichtigste Kennzahl für die Leistung eines Data Warehouse ist die Art und Weise, wie Abfragen verarbeitet werden.
„Die Leistung hängt von der Anzahl, Häufigkeit und Komplexität der Abfragen sowie von der Anzahl der gleichzeitigen Benutzer ab“, sagt Henschen.
Die Unternehmen müssen sich bei der Bewertung eines Data Warehouse über ihre Leistungsanforderungen und -erwartungen klar sein. Laut Henschen sollten sich die Unternehmen fragen, ob die Arbeitslast in erster Linie aus vorhersehbaren Abfragen besteht, die Berichte und Dashboards in großem Umfang steuern, oder ob auch unvorhersehbare Ad-hoc-Abfragen ins Spiel kommen.
4. Deployment-Management
Data Warehouses sind in der Regel umfangreiche Projekte. Selbst As-a-Service-Bereitstellungen sind mit viel Arbeit verbunden. Beispielsweise müssen Unternehmen Datenquellen verbinden oder Daten aus anderen Data Warehouses migrieren und dann die Analyse- und andere Funktionen einrichten. Bei einigen Anbietern ist dies einfacher möglich als bei anderen.
„Trotz der übertriebenen Marketingaussagen ist Unternehmenssoftware selten, wenn überhaupt, einfach zu konfigurieren und zu implementieren“, erläutert der Analyst.
Einige Anbieter bieten Support für Kunden, die ihre Software On-Premises bereitstellen, oder Tools und Dienste für das Deployment in der Cloud. Manche Anbieter verfügen auch über containerbasierte Deployment-Optionen, damit Unternehmen in hybriden und Multi-Cloud-Umgebungen konsistent bereitstellen können.
Wenn sich die Anforderungen eines Unternehmens ändern, lassen sich bestimmte Plattformen leichter skalieren als andere. Laut Henschen bieten einige Anbieter beispielsweise serverlose Data Warehouses an, die sich automatisch an die Anforderungen anpassen und dann bei wachsenden Datenspeichern skalieren.
5. Workload-Management
Viele Data-Warehouse-Anbieter versprechen heute eine intelligente Automatisierung, die das Management von Anwendungen erleichtert, aber KI- und Automatisierungstechnologien stecken noch in den Kinderschuhen.
„Es gibt kein hellseherisches Produkt, das Ihre Workloads, Workload-Prioritäten und Service Level Agreements ohne menschliche Anleitung versteht“, sagt Henschen.
Einige Data-Warehouse-Plattformen erleichtern jedoch das Festlegen von Prioritätsstufen und das Zuweisen von Ressourcen. „Dabei übernimmt das Produkt im Hintergrund alle Arten von Abfrageeinstellungen, Daten-Tiering und Caching-Entscheidungen“, ergänzt er.
Die Frage ist, ob das Data Warehouse im Falle eines Problems einfach mehr Rechenkapazität hinzufügt. Das kann die Kosten unnötig in die Höhe treiben, verglichen mit der Optimierung anderer leistungsbezogener Optionen. Henschen sagt, er habe schon erlebt, dass Unternehmen am Ende über mehr Kapazität verfügten, als sie geplant hatten.
„Bedenken Sie, dass einige Automatisierungsfunktionen Rechenpower für die Überwachung und Optimierung der Leistung verbrauchen“, fügt er hinzu. Die Automatisierung, die die Effizienz des Data Warehouses steigern soll, kann selbst die Effizienz verringern.
Die Kehrseite der Medaille ist, dass ein weniger automatisiertes Warehouse zwar granularere, manuelle Kontrollen bietet, aber dann auch viel Arbeit und Fachwissen erfordert, um es zu optimieren. „Betreiber von nicht automatisierten Systemen beklagen sich über die Personalkosten und die Schwierigkeit, qualifiziertes Personal zu finden und einzustellen“, sagt Henschen.
Außerdem gewähren die älteren Plattformen den Kunden oft Rabatte, wenn sie Kapazitäten im Voraus kaufen. Das bedeutet, dass Unternehmen, die ein oder drei Jahre im Voraus kaufen, am Ende möglicherweise zu viel Kapazität haben und viel mehr Geld ausgeben, als sie eigentlich müssten.
„Erfahrung ist der beste Lehrmeister“, sagt der Analyst. „Sprechen Sie mit bestehenden Kunden über ihre Erfahrungen bei der Leistungs- und Kapazitätsplanung.“
Die Zukunft des Data Warehouse
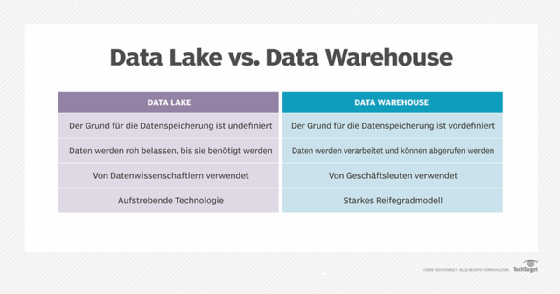
Die wichtigste Alternative zu Data Warehouses sind Data Lakes. Während Data Warehouses über strukturierte, gut organisierte Daten verfügen, sind Data Lakes freier bei der Datenorganisation und den Formaten. Die Daten können in einer Vielzahl von Formaten vorliegen, die dann von KI- und Machine-Learning-Tools gelesen werden.
Da die Daten in Data Lakes jedoch nicht gut organisiert sind, ist es laut Gartner-Analyst Adam Ronthal schwieriger, aus ihnen einen Nutzen zu ziehen; das erfordert datenwissenschaftliches Fachwissen. Eines der ersten Dinge, die Unternehmen in der Regel mit einem Data Lake tun, ist eine Optimierungsschicht hinzuzufügen, um die Daten sinnvoll zu verwenden.
„Wir können die Daten so aufbereiten, dass die praktisch arbeitenden Business-Analysten einen Nutzen daraus ziehen können“, so Ronthal. „Nur sehr wenige Leute können aus Rohdatensätzen einen Mehrwert ziehen.“
Das Ergebnis ähnelt mehr und mehr einem Data Warehouse. In der Zwischenzeit haben Data Warehouses die Unterstützung für unstrukturierte Daten erweitert.
Daher konvergieren Data Warehouses und Data Lakes immer mehr zu einem sogenannten Data Lakehouse, so Ronthal. Es kombiniert den Data-Science-Fokus des Data Lake mit der Analyseleistung des Data Warehouse.
„Alle traditionellen Data-Warehouse-Ansätze greifen auf Cloud-Datenspeicher zu, um Data-Lake-Optionen zu implementieren“, sagt Ronthal. „Und all jene, die als Data Lakes begonnen haben, legen Optimierungsschichten an, damit sie zu Data Warehouses werden können.“





