Maschinelles Lernen (Machine Learning)
Was ist maschinelles Lernen (Machine Learning)?
Maschinelles Lernen (Machine Learning, ML) ist ein Teilgebiet der KI, das sich auf den Aufbau von Computersystemen konzentriert, die aus Daten lernen. Die Bandbreite der maschinellen Lerntechniken ermöglicht es Softwareanwendungen, ihre Leistung im Laufe der Zeit zu verbessern.
ML-Algorithmen werden darauf trainiert, Beziehungen und Muster in Daten zu finden. Mithilfe von historischen Daten als Input können diese Algorithmen Vorhersagen treffen, Informationen klassifizieren, Datenpunkte gruppieren, die Dimensionalität reduzieren und sogar neue Inhalte generieren. Beispiele für Letzteres, bekannt als generative KI, sind ChatGPT von OpenAI, Claude von Anthropic und GitHub Copilot.
Maschinelles Lernen ist in vielen Branchen anwendbar. Beispielsweise nutzen E-Commerce-, Social-Media- und Nachrichtenunternehmen Empfehlungsmaschinen, um Inhalte basierend auf dem bisherigen Verhalten eines Kunden vorzuschlagen. In selbstfahrenden Autos spielen Machine-Learning-Algorithmen und Computer Vision eine entscheidende Rolle für eine sichere Navigation im Straßenverkehr. Im Gesundheitswesen kann machinelles Lernen bei der Diagnose helfen und Behandlungspläne vorschlagen. Weitere häufige Anwendungsfälle für machinelles Lernen sind Betrugserkennung, Spam-Filterung, Erkennung von Malware-Bedrohungen, vorausschauende Wartung und Automatisierung von Geschäftsprozessen.
Machinelles Lernen ist zwar ein leistungsstarkes Tool zur Problemlösung, zur Verbesserung von Geschäftsabläufen und zur Automatisierung von Aufgaben, aber es ist auch komplex und ressourcenintensiv und erfordert tiefgreifendes Fachwissen sowie umfangreiche Daten und Infrastrukturen. Die Auswahl des richtigen Algorithmus für eine Aufgabe erfordert ein tiefes Verständnis von Mathematik und Statistik. Für das Training von ML-Algorithmen werden oft große Mengen hochwertiger Daten benötigt, um genaue Ergebnisse zu erzielen. Die Ergebnisse selbst, insbesondere die von komplexen Algorithmen wie tiefen neuronalen Netzen, können schwer zu verstehen sein. Und die Ausführung und Feinabstimmung von Machine-Learning-Modellen kann kostspielig sein. Dennoch setzen die meisten Organisationen auf maschinelles Lernen, entweder direkt oder durch in Produkte integriert.
Dieser Leitfaden zum maschinellen Lernen dient als Einführung in dieses wichtige Gebiet und erklärt, was maschinelles Lernen ist, wie es implementiert wird und welche geschäftlichen Anwendungen es gibt. Sie finden Informationen zu den verschiedenen Arten von Machine-Learning-Algorithmen, zu Herausforderungen und bewährten Verfahren im Zusammenhang mit der Entwicklung und Bereitstellung von Machine-Learning-Modellen sowie zu den Zukunftsaussichten für maschinelles Lernen. Im gesamten Leitfaden finden Sie Hyperlinks zu verwandten Artikeln, die diese Themen ausführlicher behandeln.

Warum ist maschinelles Lernen wichtig?
Machinelles Lernen spielt seit seinen Anfängen in der Mitte des 20. Jahrhunderts, als KI-Pioniere wie Walter Pitts, Warren McCulloch, Alan Turing und John von Neumann die rechnerische Grundlage des Fachgebiets legten, eine immer wichtigere Rolle in der menschlichen Gesellschaft. Durch das Training von Maschinen, damit diese aus Daten lernen und sich im Laufe der Zeit verbessern, können Organisationen Routineaufgaben automatisieren, wodurch Menschen theoretisch mehr Zeit für kreativere und strategischere Aufgaben haben.
Maschinelles Lernen hat umfangreiche und vielfältige praktische Anwendungen. Im Finanzwesen helfen ML-Algorithmen Banken bei der Aufdeckung betrügerischer Transaktionen, indem sie riesige Datenmengen in Echtzeit mit einer Geschwindigkeit und Genauigkeit analysieren, die Menschen nicht erreichen können. Im Gesundheitswesen unterstützt maschinelles Lernen Ärzte bei der Diagnose von Krankheiten auf der Grundlage medizinischer Bilder und liefert Behandlungspläne mit Vorhersagemodellen für Patientenergebnisse. Und im Einzelhandel nutzen viele Unternehmen maschinelles Lernen, um Einkaufserlebnisse zu personalisieren, den Bedarf an Lagerbeständen vorherzusagen und Lieferketten zu optimieren.
Maschinelles Lernen übernimmt auch manuelle Aufgaben, die außerhalb der menschlichen Fähigkeit liegen, sie in großem Maßstab auszuführen – zum Beispiel die Verarbeitung der riesigen Datenmengen, die täglich von digitalen Geräten erzeugt werden. Diese Fähigkeit, Muster und Erkenntnisse aus riesigen Datensätzen zu extrahieren, ist zu einem Wettbewerbsvorteil in Bereichen wie dem Bankwesen und der wissenschaftlichen Forschung geworden. Viele der heute führenden Unternehmen, darunter Meta, Google und Uber, integrieren maschinelles Lernen in ihre Abläufe, um die Entscheidungsfindung zu unterstützen und die Effizienz zu verbessern.
Maschinelles Lernen ist notwendig, um die ständig wachsende Datenmenge, die von modernen Gesellschaften generiert wird, zu verstehen. Die Fülle an Daten, die Menschen erzeugen, kann auch zur weiteren Schulung und Feinabstimmung von ML-Modellen genutzt werden, wodurch Fortschritte im Bereich maschinelles Lernen beschleunigt werden. Diese kontinuierliche Lernschleife bildet die Grundlage für die fortschrittlichsten KI-Systeme von heute, mit tiefgreifenden Auswirkungen.
Philosophisch gesehen stellt die Aussicht, dass Maschinen riesige Datenmengen verarbeiten, das Verständnis des Menschen von seiner Intelligenz und seiner Rolle bei der Interpretation und Umsetzung komplexer Informationen in Frage. In der Praxis wirft dies wichtige ethische Überlegungen zu den Entscheidungen auf, die von fortgeschrittenen ML-Modellen getroffen werden. Transparenz und Erklärbarkeit beim Training von Machine-Learning-Modellen und deren Entscheidungsfindung sowie die Auswirkungen dieser Modelle auf die Beschäftigung und die gesellschaftlichen Strukturen sind Bereiche, die einer ständigen Überwachung und Diskussion bedürfen.
Welche Arten von maschinellem Lernen gibt es?
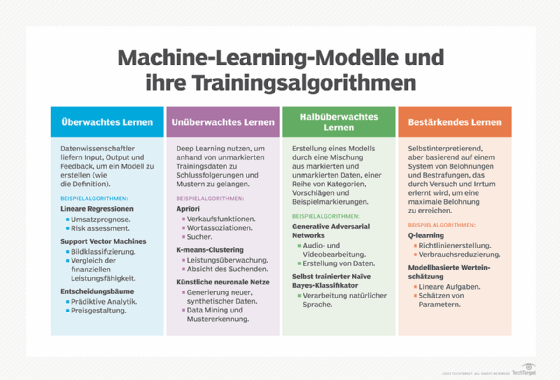
Klassisches maschinelles Lernen wird oft danach kategorisiert, wie ein Algorithmus lernt, um in seinen Vorhersagen genauer zu werden. Die vier Grundtypen sind:
- überwachtes Lernen
- unüberwachtes Lernen
- teilüberwachtes Lernen
- bestärkendes Lernen
Die Wahl des Algorithmus hängt von der Art der Daten ab. Viele Algorithmen und Techniken sind nicht auf eine einzige Art von Machine Learning beschränkt; sie können je nach Problemstellung und Datensatz an mehrere Arten angepasst werden. So werden beispielsweise Deep-Learning-Algorithmen wie Convolutional und Recurrent Neural Networks je nach spezifischer Problemstellung und Datenverfügbarkeit in überwachten, unüberwachten und bestärkenden Lernaufgaben eingesetzt.
Wie funktioniert überwachtes maschinelles Lernen?
Beim überwachten Lernen werden Algorithmen mit gelabelten Trainingsdaten versorgt und es wird definiert, welche Variablen der Algorithmus auf Korrelationen untersuchen soll. Sowohl die Eingabe als auch die Ausgabe des Algorithmus werden festgelegt. Anfangs wurden die meisten Machine-Learning-Algorithmen mit überwachtem Lernen verwendet, doch unüberwachte Ansätze werden immer beliebter.
Algorithmen für überwachtes Lernen werden für zahlreiche Aufgaben verwendet, darunter:
- Binäre Klassifizierung. Dabei werden Daten in zwei Kategorien unterteilt.
- Mehrklassenklassifizierung. Dabei wird zwischen mehr als zwei Kategorien gewählt.
- Ensemblemodellierung. Hierbei werden die Vorhersagen mehrerer ML-Modelle kombiniert, um eine genauere Vorhersage zu erhalten.
- Regressionsmodellierung. Hierbei werden kontinuierliche Werte auf der Grundlage von Beziehungen innerhalb von Daten vorhergesagt.
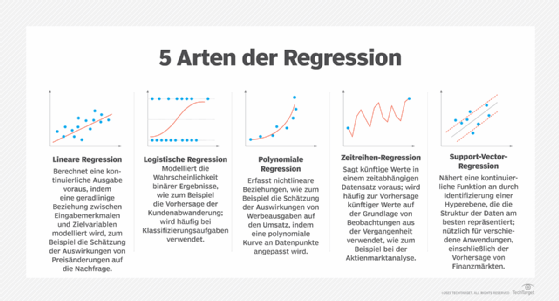
Wie funktioniert unüberwachtes maschinelles Lernen?
Unüberwachtes Lernen erfordert keine gelabelten Daten. Stattdessen analysieren diese Algorithmen nicht gekennzeichnete Daten, um Muster zu identifizieren und Datenpunkte mithilfe von Techniken wie Gradientenabstieg in Teilmengen zu gruppieren. Die meisten Arten des Deep Learnings, einschließlich neuronaler Netze, sind unüberwachte Algorithmen.
Unüberwachtes Lernen ist für verschiedene Aufgaben effektiv, darunter:
- Aufteilung des Datensatzes in Gruppen auf der Grundlage von Ähnlichkeit unter Verwendung von Clustering-Algorithmen.
- Identifizierung ungewöhnlicher Datenpunkte in einem Datensatz unter Verwendung von Algorithmen zur Erkennung von Anomalien.
- Ermittlung von Elementen in einem Datensatz, die häufig zusammen auftreten, unter Verwendung von Assoziationsregeln.
- Verringerung der Anzahl von Variablen in einem Datensatz unter Verwendung von Techniken zur Reduzierung der Dimensionalität.
Wie funktioniert halbüberwachtes Lernen?
Beim halbüberwachten Lernen wird ein Algorithmus mit nur einer geringen Menge an gekennzeichneten Trainingsdaten versorgt. Anhand dieser Daten lernt der Algorithmus die Dimensionen des Datensatzes, die er dann auf neue, nicht gekennzeichnete Daten anwenden kann. Beachten Sie jedoch, dass zu wenige Trainingsdaten zu einer Überanpassung führen können, bei der sich das Modell lediglich die Trainingsdaten merkt, anstatt die zugrunde liegenden Muster wirklich zu erlernen.
Obwohl Algorithmen in der Regel besser funktionieren, wenn sie mit gelabelten Datensätzen trainiert werden, kann die Kennzeichnung zeitaufwendig und teuer sein. Beim halbüberwachten Lernen werden Elemente des überwachten und des unüberwachten Lernens kombiniert, um ein Gleichgewicht zwischen der überlegenen Leistung des ersteren und der Effizienz des letzteren zu schaffen.
Das halbüberwachte Lernen kann unter anderem in den folgenden Bereichen eingesetzt werden:
- Maschinelle Übersetzung. Algorithmen können lernen, Sprache auf der Grundlage von weniger als einem vollständigen Wörterbuch von Wörtern zu übersetzen.
- Betrugserkennung. Algorithmen können lernen, Betrugsfälle anhand weniger positiver Beispiele zu erkennen.
- Kennzeichnung von Daten. Algorithmen, die anhand kleiner Datensätze trainiert werden, können lernen, Datenlabel automatisch auf größere Datensätze anzuwenden.
Wie funktioniert bestärkendes Lernen?
Beim bestärkenden Lernen wird ein Algorithmus mit einem bestimmten Ziel und einer Reihe von Regeln programmiert, die bei der Erreichung dieses Ziels befolgt werden müssen. Der Algorithmus strebt positive Belohnungen für die Ausführung von Aktionen an, die ihn seinem Ziel näher bringen, und vermeidet Bestrafungen für die Ausführung von Aktionen, die ihn vom Ziel entfernen.
Bestärkendes Lernen wird häufig für Aufgaben wie die folgenden eingesetzt:
- Unterstützung von Robotern beim Erlernen von Aufgaben in der physischen Welt.
- Bots das Spielen von Videospielen beibringen.
- Unterstützung von Unternehmen bei der Planung der Ressourcenzuweisung.
Wie man das richtige Modell für maschinelles Lernen auswählt und erstellt
Die Entwicklung des richtigen Machine-Learning-Modells zur Lösung eines Problems erfordert Sorgfalt, Experimentierfreude und Kreativität. Obwohl der Prozess komplex sein kann, lässt er sich in einem siebenstufigen Plan für die Erstellung eines maschinellen Lernmodells zusammenfassen.
1. Das Geschäftsproblem verstehen und Erfolgskriterien definieren. Das Wissen der Gruppe über das Geschäftsproblem und die Projektziele in eine geeignete ML-Problemdefinition umwandeln. Überlegen Sie, warum das Projekt maschinelles Lernen erfordert, welcher Algorithmus für das Problem am besten geeignet ist, welche Anforderungen an Transparenz und Reduzierung von Verzerrungen bestehen und welche Inputs und Outputs erwartet werden.
2. Datenbedarf verstehen und ermitteln. Bestimmen Sie, welche Daten für die Erstellung des Modells erforderlich sind, und beurteilen Sie, ob das Modell für die Aufnahme bereit ist. Überlegen Sie, wie viele Daten benötigt werden, wie sie in Test- und Trainingssätze aufgeteilt werden und ob ein vorab trainiertes Machine-Learning-Modell verwendet werden kann.
3. Sammeln und Aufbereiten der Daten für das Modelltraining. Bereinigen und Labeln der Daten, einschließlich Ersetzen falscher oder fehlender Daten, Reduzieren von Rauschen und Entfernen von Mehrdeutigkeiten. In dieser Phase können je nach Datensatz auch Daten verbessert und erweitert sowie personenbezogene Daten anonymisiert werden. Zum Schluss werden die Daten in Trainings-, Test- und Validierungssätze aufgeteilt.
4. Merkmale des Modells bestimmten und es trainieren. Beginnen Sie mit der Auswahl der geeigneten Algorithmen und Techniken, einschließlich der Einstellung von Hyperparametern. Trainieren und validieren Sie anschließend das Modell und optimieren Sie es bei Bedarf durch Anpassung von Hyperparametern und Gewichten. Je nach Geschäftsproblem können die Algorithmen Funktionen zum Verständnis natürlicher Sprache enthalten, wie zum Beispiel rekurrente neuronale Netze oder Transformer für Aufgaben der natürlichen Sprachverarbeitung oder Boosting-Algorithmen zur Optimierung von Entscheidungsbaummodellen.
5. Bewerten Sie die Leistung des Modells und legen Sie Benchmarks fest. Führen Sie Bewertungen mit einer Konfusionsmatrix durch, bestimmen Sie geschäftliche KPIs und ML-Metriken, messen Sie die Modellqualität und bestimmen Sie, ob das Modell die Geschäftsziele erfüllt.
6. Setzen Sie das Modell ein und überwachen Sie seine Leistung in der Produktion. Dieser Teil des Prozesses, der als Operationalisierung des Modells bezeichnet wird, wird in der Regel von Datenwissenschaftlern und Ingenieuren für maschinelles Lernen gemeinsam durchgeführt. Die Modellleistung wird kontinuierlich gemessen, Benchmarks für zukünftige Modelliterationen werden entwickelt und es wird iteriert, um die Gesamtleistung zu verbessern. Bereitstellungsumgebungen können in der Cloud, am Edge oder On-Premises sein.
7. Kontinuierliche Verfeinerung und Anpassung des Modells in der Produktion. Selbst nachdem das Machine-Learning-Modell in der Produktion ist und kontinuierlich überwacht wird, geht die Arbeit weiter. Änderungen der Geschäftsanforderungen, der technologischen Möglichkeiten und der realen Daten können neue Anforderungen und Bedürfnisse mit sich bringen.
Anwendungen für maschinelles Lernen in Unternehmen
Maschinelles Lernen ist zu einem integralen Bestandteil von Unternehmenssoftware geworden. Im Folgenden finden Sie einige Beispiele dafür, wie verschiedene Geschäftsanwendungen maschinelles Lernen nutzen:
- Business Intelligence (BI). BI- und Predictive-Analytics-Software verwendet Machine-Learning-Algorithmen, einschließlich linearer Regression und logistischer Regression, um signifikante Datenpunkte, Muster und Anomalien in großen Datensätzen zu identifizieren. Diese Erkenntnisse unterstützen Unternehmen, datengestützte Entscheidungen zu treffen, Trends vorherzusagen und die Leistung zu optimieren. Fortschritte in der generativen KI haben auch die Erstellung detaillierter Berichte und Dashboards ermöglicht, die komplexe Daten in leicht verständlichen Formaten zusammenfassen.
- Customer Relationship Management (CRM). Zu den wichtigsten Machine-Learning-Anwendungen im CRM gehören die Analyse von Kundendaten zur Kundensegmentierung, die Vorhersage von Verhaltensweisen wie Abwanderung, die Abgabe personalisierter Empfehlungen, die Anpassung der Preisgestaltung, die Optimierung von E-Mail-Kampagnen, die Bereitstellung von Chatbot-Support und die Aufdeckung von Betrug. Generative KI kann auch maßgeschneiderte Marketinginhalte erstellen, Antworten im Kundenservice automatisieren und Erkenntnisse auf der Grundlage von Kundenfeedback generieren.
- Sicherheit und Compliance. Support-Vektor-Maschinen können Abweichungen im Verhalten von einer normalen Grundlinie unterscheiden, was für die Identifizierung potenzieller Cyberbedrohungen von entscheidender Bedeutung ist, indem sie die beste Linie oder Grenze für die Aufteilung von Daten in verschiedene Gruppen finden. Generative Adversarial Networks (GAN) können feindlich gesinnte Beispiele für Malware erstellen und Sicherheitsteams dabei unterstützen, ML-Modelle zu trainieren, die besser zwischen gutartiger und bösartiger Software unterscheiden können.
- Personalinformationssysteme (PIS). ML-Modelle optimieren die Einstellung von Mitarbeitern, indem sie Bewerbungen filtern und die besten Kandidaten für eine Position ermitteln. Sie können auch die Mitarbeiterfluktuation vorhersagen, berufliche Entwicklungswege vorschlagen und die Planung von Vorstellungsgesprächen automatisieren. Generative KI kann bei der Erstellung von Stellenbeschreibungen und der Erstellung personalisierter Schulungsmaterialien unterstützen.
- Lieferkettenmanagement. Maschinelles Lernen kann Lagerbestände optimieren, die Logistik rationalisieren, die Lieferantenauswahl verbessern und proaktiv auf Störungen in der Lieferkette reagieren. Vorhersagen können die Nachfrage genauer prognostizieren und KI-gesteuerte Simulationen können verschiedene Szenarien modellieren, um die Widerstandsfähigkeit zu verbessern.
- Natural Language Processing (NLP). NLP-Anwendungen umfassen unter anderem Stimmungsanalysen, Sprachübersetzungen und Textzusammenfassungen. Fortschritte in der generativen KI, wie GPT-4 von OpenAI und Gemini von Google, haben diese Fähigkeiten erheblich verbessert. Generative NLP-Modelle können menschenähnliche Texte erstellen, virtuelle Assistenten verbessern und anspruchsvollere sprachbasierte Anwendungen ermöglichen, einschließlich der Erstellung von Inhalten und der Zusammenfassung von Dokumenten.
Beispiele für maschinelles Lernen nach Branche
Die branchenübergreifende Einführung von Machine-Learning-Techniken in Unternehmen verändert Geschäftsprozesse. Hier sind einige Beispiele:
- Finanzdienstleistungen. Capital One nutzt maschinelles Lernen, um die Betrugserkennung zu verbessern, personalisierte Kundenerlebnisse zu bieten und die Geschäftsplanung zu optimieren. Das Unternehmen setzt die MLOps-Methode ein, um die Machine-Learning-Anwendungen in großem Maßstab bereitzustellen.
- Pharmazeutische Industrie. Arzneimittelhersteller nutzen maschinelles Lernen für die Arzneimittelforschung, klinische Studien und die Arzneimittelherstellung. Eli Lilly hat beispielsweise KI- und ML-Modelle entwickelt, um die besten Standorte für klinische Studien zu finden und die Vielfalt der Teilnehmer zu erhöhen. Laut Angaben des Unternehmens haben die Modelle die Zeitpläne für klinische Studien deutlich verkürzt.
- Versicherungswesen. Das bekannte Snapshot-Programm von Progressive Corp. verwendet ML-Algorithmen zur Analyse von Fahrdaten und bietet sicheren Fahrern niedrigere Tarife. Weitere nützliche Anwendungen des maschinellen Lernens im Versicherungswesen sind das Underwriting und die Schadensbearbeitung.
- Einzelhandel. Walmart hat My Assistant, ein generatives KI-Tool, eingeführt, um seinen rund 50.000 Mitarbeitern auf dem Campus bei der Erstellung von Inhalten zu helfen, große Dokumente zusammenzufassen und als allgemeiner Kreativpartner zu fungieren. Das Unternehmen nutzt das Tool auch, um Feedback von Mitarbeitern zu Anwendungsfällen einzuholen.
Was sind die Vor- und Nachteile von maschinellem Lernen?
Bei effektivem Einsatz verschafft maschinelles Lernen Unternehmen einen Wettbewerbsvorteil, indem es Trends identifiziert und Ergebnisse mit höherer Genauigkeit vorhersagt als herkömmliche Statistiken oder menschliche Intelligenz. Maschinelles Lernen kann Unternehmen auf verschiedene Weise zugutekommen:
- Analyse historischer Daten zur Kundenbindung.
- Einführung von Empfehlungssystemen zur Umsatzsteigerung.
- Verbesserung von Planung und Prognose.
- Bewertung von Mustern zur Aufdeckung von Betrug.
- Steigerung der Effizienz und Senkung der Kosten.
Aber maschinelles Lernen bringt auch eine Reihe von geschäftlichen Herausforderungen mit sich. In erster Linie kann es teuer sein. Maschinelles Lernen erfordert eine kostspielige Software-, Hardware- und Datenmanagementinfrastruktur, und Projekte werden in der Regel von Datenwissenschaftlern und -ingenieuren durchgeführt, die hohe Gehälter verlangen.
Ein weiteres wichtiges Problem ist die Voreingenommenheit von ML-Modellen. Algorithmen, die auf Datensätzen trainiert werden, die bestimmte Bevölkerungsgruppen ausschließen oder Fehler enthalten, können zu ungenauen Modellen führen. Diese Modelle können versagen und im schlimmsten Fall diskriminierende Ergebnisse hervorbringen. Wenn Kernprozesse eines Unternehmens auf voreingenommenen Modellen basieren, kann dies zu regulatorischen und rufschädigenden Folgen für das Unternehmen führen.
Wie Menschen Machine-Learning-Modelle verstehen
Die internen Abläufe eines bestimmten ML-Modells zu erklären, kann eine Herausforderung darstellen, insbesondere wenn das Modell komplex ist. Mit der Weiterentwicklung des maschinellen Lernens wird die Bedeutung erklärbarer, transparenter Modelle nur noch zunehmen, insbesondere in Branchen mit hohen Compliance-Anforderungen, wie dem Bank- und Versicherungswesen.
Die Entwicklung von maschinellen Lernmodellen, deren Ergebnisse für Menschen verständlich und erklärbar sind, ist aufgrund der raschen Fortschritte bei der Einführung hochentwickelter ML-Techniken, wie der generativen KI, zu einer Priorität geworden. Forscher in KI-Labors wie Anthropic haben Fortschritte beim Verständnis der Funktionsweise generativer KI-Modelle erzielt, indem sie sich auf Techniken der Interpretierbarkeit und Erklärbarkeit stützten.
Interpretierbare versus erklärbare KI
Bei der Interpretierbarkeit geht es darum, die inneren Abläufe eines Machine-Learning-Modells im Detail zu verstehen, während es bei der Erklärbarkeit darum geht, die Entscheidungsfindung des Modells auf verständliche Weise zu beschreiben. Interpretierbare ML-Techniken werden in der Regel von Datenwissenschaftlern und anderen ML-Praktikern eingesetzt, wobei die Erklärbarkeit eher dazu dient, Laien das Verständnis von Modellen des maschinellen Lernens zu erleichtern. Ein sogenanntes Black-Box-Modell kann beispielsweise auch dann erklärbar sein, wenn es nicht interpretierbar ist. Forscher könnten verschiedene Eingaben testen und die nachfolgenden Änderungen in den Ausgaben beobachten, wobei sie Methoden wie Shapley Additive Explanations (SHAP) verwenden, um zu sehen, welche Faktoren die Ausgabe am meisten beeinflussen. Auf diese Weise können Forscher ein klares Bild davon erhalten, wie das Modell Entscheidungen trifft (Erklärbarkeit), auch wenn sie die Mechanik des komplexen neuronalen Netzwerks im Inneren nicht vollständig verstehen (Interpretierbarkeit).
Interpretierbare Machine-Learning-Techniken zielen darauf ab, den Entscheidungsprozess eines Modells klarer und transparenter zu gestalten. Beispiele hierfür sind Entscheidungsbäume, die eine visuelle Darstellung von Entscheidungspfaden bieten, lineare Regression, die Vorhersagen auf der Grundlage gewichteter Summen von Eingabemerkmalen erklärt, und Bayessche Netze, die Abhängigkeiten zwischen Variablen auf strukturierte und interpretierbare Weise darstellen.
Erklärbare KI-Techniken werden nachträglich eingesetzt, um die Ergebnisse komplexerer Machine-Learning-Modelle für menschliche Beobachter verständlicher zu machen. Beispiele hierfür sind lokal interpretierbare modellunabhängige Erklärungen (LIME), die das Verhalten des Modells lokal mit einfacheren Modellen approximieren, um einzelne Vorhersagen zu erklären, und SHAP-Werte, die jedem Merkmal Wichtigkeitsbewertungen zuweisen, um zu verdeutlichen, wie sie zur Entscheidung des Modells beitragen.
Transparenzanforderungen können die Wahl des Modells bestimmen
In einigen Branchen müssen Datenwissenschaftler einfache maschinelle Lernmodelle verwenden, da es für das Unternehmen wichtig ist, zu erklären, wie jede Entscheidung getroffen wurde. Dieser Bedarf an Transparenz führt oft zu einem Kompromiss zwischen Einfachheit und Genauigkeit. Obwohl komplexe Modelle sehr genaue Vorhersagen liefern können, kann es schwierig sein, ihre Ergebnisse einem Laien – oder sogar einem Experten – zu erklären.
Einfachere, besser interpretierbare Modelle werden oft in stark regulierten Branchen bevorzugt, in denen Entscheidungen begründet und geprüft werden müssen. Fortschritte bei der Interpretierbarkeit und Erklärbarkeit machen es jedoch zunehmend möglich, komplexe Modelle einzusetzen und gleichzeitig die für Compliance und Vertrauen erforderliche Transparenz zu wahren.
Teams, Rollen und Arbeitsabläufe für maschinelles Lernen
Der Aufbau eines Machine-Learning-Teams beginnt mit der Definition der Ziele und des Umfangs des Projekts. Zu den wesentlichen Fragen gehören: Welche geschäftlichen Probleme muss das Team lösen? Welche Ziele hat das Team? Welche Kennzahlen werden zur Leistungsbewertung herangezogen?
Die Beantwortung dieser Fragen ist ein wesentlicher Bestandteil der Planung eines maschinellen Lernprojekts. Sie hilft der Organisation, den Schwerpunkt des Projekts (zum Beispiel Forschung, Produktentwicklung, Datenanalyse) und die erforderlichen Arten von Fachwissen (zum Beispiel Computer Vision, NLP, Vorhersagemodellierung) zu verstehen.
Als Nächstes müssen Organisationen auf der Grundlage dieser Überlegungen und der Budgetbeschränkungen entscheiden, welche Stellen für das Machine-Learning-Team erforderlich sind. Das Projektbudget sollte nicht nur die üblichen Personalkosten wie Gehälter, Sozialleistungen und Einarbeitung umfassen, sondern auch Tools, Infrastruktur und Schulungen. Die konkrete Zusammensetzung eines ML-Teams kann zwar variieren, doch die meisten Teams in Unternehmen setzen sich aus einer Mischung aus technischen und kaufmännischen Fachleuten zusammen, die jeweils einen bestimmten Fachbereich in das Projekt einbringen.
Rollen im ML-Team
Ein ML-Team umfasst in der Regel auch einige Nicht-ML-Rollen, wie zum Beispiel Fachleute, die bei der Interpretation von Daten unterstützen und die Relevanz für das Projektfeld sicherstellen, Projektmanager, die den Lebenszyklus des maschinellen Lernprojekts überwachen, Produktmanager, die die Entwicklung von Anwendungen und Software planen, und Entwickler, die diese Anwendungen erstellen.
Darüber hinaus sind mehrere stärker auf maschinelles Lernen fokussierte Rollen für ein entsprechendes Team unerlässlich:
- Datenwissenschaftler. Datenwissenschaftler entwerfen Experimente und erstellen Modelle, um Ergebnisse vorherzusagen und Muster zu erkennen. Sie sammeln und analysieren Datensätze, bereinigen und verarbeiten Daten vor, entwerfen Modellarchitekturen, interpretieren Modellergebnisse und teilen die Ergebnisse Führungskräften und Stakeholdern mit. Datenwissenschaftler benötigen Fachwissen in Statistik, Computerprogrammierung und maschinellem Lernen, einschließlich gängiger Sprachen wie Python und R und Frameworks wie PyTorch und TensorFlow.
- Dateningenieur. Dateningenieure sind für die Infrastruktur verantwortlich, die Machine-Learning-Projekte unterstützt, und stellen sicher, dass Daten auf zugängliche Weise gesammelt, verarbeitet und gespeichert werden. Sie entwerfen, erstellen und warten Datenpipelines, verwalten große Datenverarbeitungssysteme und erstellen und optimieren Datenintegrationsprozesse. Sie benötigen Fachwissen in den Bereichen Datenbankverwaltung, Data Warehousing, Programmiersprachen wie SQL und Scala sowie Big-Data-Technologien wie Hadoop und Apache Spark.
- Machine Learning Engineer. Auch bekannt als MLOps-Ingenieure, helfen Machine Learning Engineers dabei, die von Datenwissenschaftlern entwickelten Modelle mithilfe der von Dateningenieuren gewarteten ML-Pipelines in Produktionsumgebungen zu bringen. Sie optimieren Algorithmen für die Leistung, setzen ML-Modelle ein und überwachen sie, warten und skalieren die Infrastruktur und automatisieren den Lebenszyklus durch Verfahren wie CI/CD und Datenversionierung. Neben Kenntnissen in maschinellem Lernen und KI benötigt ein Machine Learning Engineer in der Regel Fachwissen in den Bereichen Softwareentwicklung, Datenarchitektur und Cloud Computing.

Schritte zur Einrichtung von Machine Learning Workflows
Sobald das Machine-Learning-Team gebildet ist, ist es wichtig, dass alles reibungslos läuft. Stellen Sie sicher, dass die Teammitglieder Wissen und Ressourcen problemlos austauschen können, um konsistente Arbeitsabläufe und bewährte Verfahren zu etablieren. Implementieren Sie beispielsweise Tools für die Zusammenarbeit, Versionskontrolle und das Projektmanagement, wie zum Beispiel Git und Jira.
Eine klare und gründliche Dokumentation ist auch für die Fehlerbehebung, den Wissenstransfer und die Wartbarkeit wichtig. Bei Machine-Learning-Projekten umfasst dies die Dokumentation von Datensätzen, Modellläufen und Code mit detaillierten Beschreibungen von Datenquellen, Vorverarbeitungsschritten, Modellarchitekturen, Hyperparametern und Versuchsergebnissen.
Eine gängige Methode zur Verwaltung von ML-Projekten ist MLOps, kurz für Machine Learning Operations: eine Reihe von Verfahren zur Bereitstellung, Überwachung und Wartung von ML-Modellen in der Produktion. Sie ist von DevOps inspiriert, berücksichtigt aber die Nuancen, die maschinelles Lernen von der Softwareentwicklung unterscheiden. So wie DevOps die Zusammenarbeit zwischen Softwareentwicklern und IT-Abteilungen verbessert, verbindet MLOps Datenwissenschaftler und Machine Learning Engineers mit Entwicklungs- und Betriebsteams.
Durch die Einführung von MLOps wollen Organisationen die Konsistenz, Reproduzierbarkeit und Zusammenarbeit in ML-Workflows verbessern. Dazu gehört die Nachverfolgung von Experimenten, die Verwaltung von Modellversionen und die detaillierte Protokollierung von Daten- und Modelländerungen. Durch die Aufzeichnung von Modellversionen, Datenquellen und Parametereinstellungen wird sichergestellt, dass Projektteams Änderungen leicht nachverfolgen und verstehen können, wie sich verschiedene Variablen auf die Modellleistung auswirken.
Ebenso reduzieren standardisierte Arbeitsabläufe und die Automatisierung sich wiederholender Aufgaben den Zeit- und Arbeitsaufwand für die Übertragung von Modellen von der Entwicklung in die Produktion. Dazu gehört die Automatisierung von Modelltraining, -tests und -bereitstellung. Nach der Bereitstellung wird durch kontinuierliche Überwachung und Protokollierung sichergestellt, dass die Modelle immer mit den neuesten Daten aktualisiert werden und optimal funktionieren.
Tools und Plattformen für maschinelles Lernen
Die Entwicklung von ML stützt sich auf eine Reihe von Plattformen, Software-Frameworks, Codebibliotheken und Programmiersprachen. Hier finden Sie eine Übersicht über jede Kategorie und einige der wichtigsten Tools in dieser Kategorie.
Plattformen
Machine-Learning-Plattformen sind integrierte Umgebungen, die Tools und Infrastruktur zur Unterstützung des ML-Modelllebenszyklus bereitstellen. Zu den wichtigsten Funktionen gehören Datenverwaltung, Modellentwicklung, -training, -validierung und -bereitstellung sowie Überwachung und Verwaltung nach der Bereitstellung. Viele Plattformen enthalten auch Funktionen zur Verbesserung der Zusammenarbeit, Compliance und Sicherheit sowie Komponenten für automatisiertes maschinelles Lernen (AutoML), die Aufgaben wie Modellauswahl und Parametrisierung automatisieren.
Jeder der drei großen Cloud-Anbieter bietet eine Machine-Learning-Plattform an, die für die Integration in sein Cloud-Ökosystem konzipiert ist: Google Vertex AI, Amazon SageMaker und Microsoft Azure Machine Learning. Diese vereinheitlichten Umgebungen bieten Tools für die Modellentwicklung, das Training und die Bereitstellung, einschließlich AutoML- und MLOps-Funktionen und Unterstützung für beliebte Frameworks wie TensorFlow und PyTorch. Die Wahl hängt oft davon ab, welche Plattform sich am besten in die bestehende IT-Umgebung einer Organisation integrieren lässt.
Zusätzlich zu den Angeboten der Cloud-Anbieter gibt es mehrere Drittanbieter- und Open-Source-Alternativen. Im Folgenden sind einige weitere beliebte Plattformen aufgeführt:
- IBM Watson Studio. Bietet umfassende Tools für Datenwissenschaftler, Anwendungsentwickler und MLOps-Ingenieure. Es legt den Schwerpunkt auf KI-Ethik und Transparenz und lässt sich gut in die IBM Cloud integrieren.
- Databricks. Eine einheitliche Analyseplattform, die sich gut für die Verarbeitung großer Datenmengen eignet. Sie bietet Funktionen für die Zusammenarbeit, wie zum Beispiel kollaborative Notizbücher, und eine verwaltete Version von MLflow, einem von Databricks entwickelten Open Source Tool zur Verwaltung des ML-Lebenszyklus.
- Snowflake. Eine Cloud-Datenplattform, die Data Warehousing und Unterstützung für Machine-Learning- und datenwissenschaftliche Arbeitslasten bietet. Sie lässt sich in eine Vielzahl von Daten-Tools und Frameworks integrieren.
- DataRobot. Eine Plattform für die schnelle Modellentwicklung, -bereitstellung und -verwaltung, die den Schwerpunkt auf AutoML und MLOps legt. Sie bietet eine umfangreiche Auswahl an vorgefertigten Modellen und Tools zur Datenaufbereitung.
Frameworks und Bibliotheken
Machine-Learning-Frameworks und -Bibliotheken bilden die Bausteine für die Modellentwicklung: Sammlungen von Funktionen und Algorithmen, die Ingenieure nutzen können, um maschinelle Lernmodelle schneller und effizienter zu entwerfen, zu trainieren und einzusetzen.
In der Praxis werden die Begriffe Framework und Bibliothek oft synonym verwendet. Genau genommen ist ein Framework jedoch eine umfassende Umgebung mit hochrangigen Tools und Ressourcen für die Erstellung und Verwaltung von ML-Anwendungen, während eine Bibliothek eine Sammlung von wiederverwendbarem Code für bestimmte ML-Aufgaben ist.
Im Folgenden sind einige der gängigsten Frameworks und Bibliotheken aufgeführt:
- TensorFlow. Ein Open-Source-Framework, das ursprünglich von Google entwickelt wurde. Es wird häufig für Deep Learning verwendet, da es umfassende Unterstützung für neuronale Netze und groß angelegtes maschinelles Lernen bietet.
- PyTorch. Ein Open-Source-Framework, das ursprünglich von Meta entwickelt wurde. Es ist für seine Flexibilität und Benutzerfreundlichkeit bekannt und wird, wie TensorFlow, häufig für Deep-Learning-Modelle verwendet.
- Keras. Eine Open-Source-Python-Bibliothek, die als Schnittstelle für den Aufbau und das Training neuronaler Netze dient. Sie ist benutzerfreundlich und wird häufig als High-Level-API für TensorFlow und andere Backends verwendet.
- Scikit-learn. Eine Open-Source-Python-Bibliothek für Datenanalyse und maschinelles Lernen, auch bekannt als sklearn. Sie eignet sich ideal für Aufgaben wie Klassifizierung, Regression und Clustering.
- OpenCV. Eine Computer-Vision-Bibliothek, die Python, Java und C++ unterstützt. Sie bietet Tools für Echtzeit-Computer-Vision-Anwendungen, einschließlich Bildverarbeitung, Videoerfassung und -analyse.
- NLTK. Eine Python-Bibliothek, die auf NLP-Aufgaben spezialisiert ist. Zu ihren Funktionen gehören unter anderem Textverarbeitungsbibliotheken für Klassifizierung, Tokenisierung, Stemming, Tagging und Parsing.
Programmiersprachen
Theoretisch kann fast jede Programmiersprache für maschinelles Lernen verwendet werden. In der Praxis wählen die meisten Programmierer jedoch eine Sprache für ein Projekt basierend auf Überlegungen wie der Verfügbarkeit von Codebibliotheken, Community-Support und Vielseitigkeit.
In den meisten Fällen bedeutet dies Python, die am häufigsten verwendete Sprache im Bereich des maschinellen Lernens. Python ist einfach und gut lesbar, sodass es für Programmieranfänger oder Entwickler, die mit anderen Sprachen vertraut sind, leicht zu erlernen ist. Python verfügt außerdem über eine Vielzahl von datenwissenschaftlichen und Machine-Learning-Bibliotheken und -Frameworks, darunter TensorFlow, PyTorch, Keras, scikit-learn, pandas und NumPy.
Zu den weiteren verwendeten Sprachen gehören:
- R. R ist für seine statistischen Analyse- und Visualisierungsfunktionen bekannt und wird in Wissenschaft und Forschung häufig eingesetzt. Es eignet sich gut für die Datenmanipulation, statistische Modellierung und grafische Darstellung.
- Julia. Julia ist eine weniger bekannte Sprache, die speziell für numerische und wissenschaftliche Berechnungen entwickelt wurde. Sie ist für ihre hohe Leistung bekannt, insbesondere bei der Verarbeitung mathematischer Berechnungen und großer Datensätze.
- C++. C++ ist eine effiziente und leistungsstarke Allzwecksprache, die häufig in Produktionsumgebungen eingesetzt wird. Sie wird wegen ihrer Geschwindigkeit und der Kontrolle über Systemressourcen geschätzt, wodurch sie sich gut für leistungskritische maschinelle Lernanwendungen eignet.
- Scala. Die prägnante Allzwecksprache Scala wird häufig mit Big-Data-Frameworks wie Apache Spark verwendet. Scala kombiniert objektorientierte und funktionale Programmierparadigmen und bietet eine skalierbare und effiziente Datenverarbeitung.
- Java. Wie Scala eignet sich Java gut für die Arbeit mit Big-Data-Frameworks. Es handelt sich um eine leistungsstarke, portable und skalierbare Allzwecksprache, die häufig in Unternehmensumgebungen zu finden ist.
Wie sieht die Zukunft des maschinellen Lernens aus?
Angetrieben durch umfangreiche Forschungen von Unternehmen, Universitäten und Regierungen auf der ganzen Welt entwickelt sich das maschinelle Lernen weiterhin rasant weiter. Durchbrüche in KI und maschinellem Lernen kommen häufig vor und machen anerkannte Praktiken fast schon überflüssig, sobald sie etabliert sind. Eine Gewissheit über die Zukunft des maschinellen Lernens ist seine weiterhin zentrale Rolle im 21. Jahrhundert, die die Art und Weise, wie wir arbeiten und leben, verändert.
Mehrere aufkommende Trends prägen die Zukunft des maschinellen Lernens:
- NLP. Fortschritte bei Algorithmen und Infrastruktur haben zu einer flüssigeren Konversations-KI, vielseitigeren ML-Modellen, die sich an neue Aufgaben anpassen können, und maßgeschneiderten Sprachmodellen, die auf die Bedürfnisse von Unternehmen abgestimmt sind, geführt. Large Language Models (LLM) gewinnen an Bedeutung und ermöglichen eine anspruchsvolle Erstellung von Inhalten und verbesserte Mensch-Computer-Interaktionen.
- Computer Vision. Es wird erwartet, dass sich die Weiterentwicklung der Computer-Vision-Fähigkeiten tiefgreifend auf viele Bereiche auswirken wird. Im Gesundheitswesen spielt sie eine immer wichtigere Rolle bei der Diagnose und Überwachung. Die Umweltwissenschaften profitieren von der Fähigkeit von Computer-Vision-Modellen, Wildtiere und ihre Lebensräume zu analysieren und zu überwachen. In der Softwareentwicklung ist sie eine Kernkomponente von Augmented- und Virtual-Reality-Technologien.
- Unternehmenstechnologie. Große Anbieter wie Amazon, Google, Microsoft, IBM und OpenAI wetteifern darum, Kunden für AutoML-Plattformdienste zu gewinnen, die das gesamte Spektrum der Machine-Learning-Aktivitäten abdecken, einschließlich Datenerfassung, -aufbereitung und -klassifizierung, Modellbildung und -training sowie Anwendungsbereitstellung.
- Interpretierbares maschinelles Lernen und erklärbare KI. Diese Konzepte gewinnen an Bedeutung, da Organisationen versuchen, ihre Machine-Learning-Modelle transparenter und verständlicher zu gestalten. Techniken wie LIME, SHAP und interpretierbare Modellarchitekturen werden zunehmend in die Entwicklung integriert, um sicherzustellen, dass KI-Systeme nicht nur genau, sondern auch verständlich und vertrauenswürdig sind.
Bei aller Begeisterung stehen Unternehmen vor ähnlichen Herausforderungen wie bei früheren innovativen, sich schnell entwickelnden Technologien. Zu diesen Herausforderungen gehören die Anpassung der bestehenden Infrastruktur an Machine-Learning-Systeme, die Minderung von Verzerrungen und anderen schädlichen Auswirkungen sowie die Optimierung des Einsatzes von maschinellem Lernen zur Erzielung von Gewinnen bei gleichzeitiger Minimierung der Kosten. Ethische Überlegungen, Datenschutz und die Einhaltung gesetzlicher Vorschriften sind ebenfalls wichtige Themen, mit denen sich Unternehmen befassen müssen, wenn sie fortschrittliche KI- und ML-Technologien in ihre Abläufe integrieren.





