Deep Learning

Deep Learning ist eine Form des Machine Learning (ML) und der künstlichen Intelligenz (KI), die die Art und Weise imitiert, wie Menschen bestimmte Arten von Wissen erlangen. Deep Learning ist ein wichtiges Element der Data Science (Datenwissenschaft), die Statistik und Predictive Modelling (prädiktive Modellierung) umfasst. Es ist äußerst vorteilhaft für Data Scientists, die mit dem Sammeln, Analysieren und Interpretieren großer Datenmengen betraut sind: Deep Learning beschleunigt und vereinfacht diesen Prozess.
Im einfachsten Fall kann man sich Deep Learning als eine Möglichkeit vorstellen, Predictive Analytics zu automatisieren. Während traditionelle Algorithmen für Machine Learning linear sind, sind Deep-Learning-Algorithmen in einer Hierarchie zunehmender Komplexität und Abstraktion zusammengefasst.
Um Deep Learning zu verstehen, kann man sich ein Kleinkind vorstellen, dessen erstes Wort Hund ist. Das Kleinkind lernt, was ein Hund ist – und was nicht – indem es auf Objekte zeigt und das Wort „Hund“ sagt. Die Eltern sagen: „Ja, das ist ein Hund“, oder „Nein, das ist kein Hund“. Während das Kleinkind weiterhin auf Objekte zeigt, wird es sich der Merkmale, die alle Hunde besitzen, immer mehr bewusst. Das Kleinkind verdeutlicht, ohne es zu wissen, eine komplexe Abstraktion – das Konzept des Hundes – indem es eine Hierarchie aufbaut, in der jede Abstraktionsebene mit dem Wissen aus der vorangegangenen Ebene der Hierarchie erstellt wird.
Wie Deep Learning funktioniert
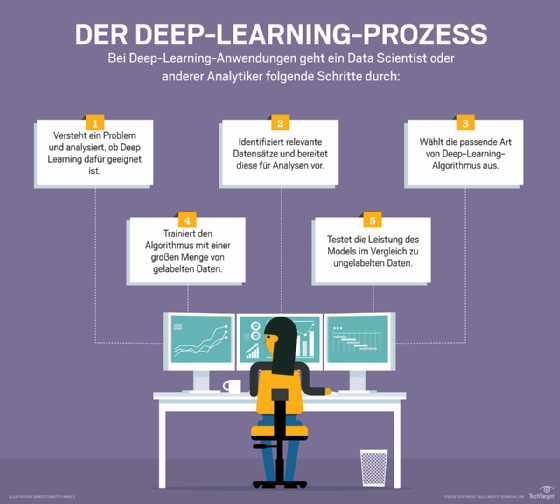
Computerprogramme, die Deep Learning verwenden, durchlaufen einen ähnlichen Prozess wie das Kleinkind, das lernt, den Hund zu identifizieren. Jeder Algorithmus in der Hierarchie wendet eine nichtlineare Transformation auf seine Eingabe an und verwendet das Gelernte, um ein statistisches Modell als Ausgabe zu erstellen. Die Iterationen werden so lange fortgesetzt, bis die Ausgabe ein akzeptables Maß an Genauigkeit erreicht hat. Die Anzahl der Verarbeitungsschichten, die die Daten durchlaufen müssen, ist das, was die Bezeichnung deep, also tief, inspiriert hat.
Beim traditionellen maschinellen Lernen ist der Lernprozess überwacht, und der Programmierer muss dem Computer sehr genau sagen, nach welchen Dingen er suchen soll, um zu entscheiden, ob ein Bild einen Hund enthält oder nicht. Dies ist ein mühsamer Prozess, der als Merkmalsextraktion bezeichnet wird, und die Erfolgsrate des Computers hängt vollständig von der Fähigkeit des Programmierers ab, einen Merkmalssatz für Hund genau zu definieren. Der Vorteil von Deep Learning ist, dass das Programm den Feature-Satz ohne Überwachung selbst aufbaut. Unüberwachtes Lernen ist nicht nur schneller, sondern in der Regel auch genauer.
Zu Beginn werden dem Computerprogramm Trainingsdaten zur Verfügung gestellt – ein Satz von Bildern, für die ein Mensch jedes Bild mit Metatags als Hund oder nicht Hund gekennzeichnet hat. Das Programm verwendet die Informationen, die es aus den Trainingsdaten erhält, um einen Merkmalssatz für Hund und ein Vorhersagemodell zu erstellen. In diesem Fall kann das Modell, das der Computer zuerst erstellt, vorhersagen, dass alles in einem Bild, das vier Beine und einen Schwanz hat, als Hund bezeichnet werden sollte. Natürlich kennt das Programm die Bezeichnungen vier Beine oder Schwanz nicht. Es wird einfach nach Mustern von Pixeln in den digitalen Daten suchen. Mit jeder Iteration wird das prädiktive Modell komplexer und genauer.
Im Gegensatz zu einem Kleinkind, das Wochen oder sogar Monate braucht, um den Begriff Hund zu verstehen, kann ein Computerprogramm, das Deep-Learning-Algorithmen verwendet, mit einem Trainingssatz Millionen von Bildern durchsuchen und innerhalb weniger Minuten genau erkennen, auf welchen Bildern Hunde zu sehen sind.
Um ein akzeptables Maß an Genauigkeit zu erreichen, benötigen Deep-Learning-Programme Zugang zu immensen Mengen an Trainingsdaten und Rechenleistung – beides war für Programmierer bis zur Ära von Big Data und Cloud Computing nicht ohne weiteres verfügbar.
Da Deep-Learning-Programme komplexe statistische Modelle direkt aus ihrer eigenen iterativen Ausgabe erstellen können, sind sie in der Lage, genaue Vorhersagemodelle aus großen Mengen von nicht gelabelten, unstrukturierten Daten zu erstellen. Dies ist wichtig, da das Internet der Dinge (Internet of Things, IoT) immer allgegenwärtiger wird, da die meisten von Menschen und Maschinen erzeugten Daten unstrukturiert und nicht gelabelt sind.
Deep-Learning-Methoden
Es können verschiedene Methoden verwendet werden, um starke Deep-Learning-Modelle zu erstellen. Hierzu zählen unter anderem die Lernrate, Transferlernen, das Training von Grund auf und Dropout.
Lernrate (Learning Rate Decay). Die Lernrate ist ein Hyperparameter – ein Faktor, der das System definiert oder Bedingungen für seinen Betrieb vor dem Lernprozess festlegt – der steuert, wie stark sich das Modell als Reaktion auf den geschätzten Fehler jedes Mal ändert, wenn die Modellgewichte geändert werden. Zu hohe Lernraten können zu instabilen Trainingsprozessen oder zum Lernen eines suboptimalen Satzes von Gewichten führen. Lernraten, die zu klein sind, können zu einem langwierigen Trainingsprozess führen, bei dem die Gefahr besteht, dass er stecken bleibt.
Die Methode der Lernratenabnahme (Learning Rate Decay) – auch Lernratenglühen oder adaptive Lernraten genannt – ist der Prozess der Anpassung der Lernrate, um die Leistung zu erhöhen und die Trainingszeit zu reduzieren. Zu den einfachsten und häufigsten Anpassungen der Lernrate während des Trainings gehören Techniken zur Verringerung der Lernrate im Laufe der Zeit.
Transferlernen (Transfer Learning). Dieser Prozess beinhaltet die Perfektionierung eines zuvor trainierten Modells. Er erfordert eine Schnittstelle zu den Interna eines bereits existierenden Netzwerks. Zunächst füttert der Benutzer das bestehende Netzwerk mit neuen Daten, die bisher unbekannte Klassifizierungen enthalten. Sobald Anpassungen am Netzwerk vorgenommen wurden, können neue Aufgaben mit spezifischeren Kategorisierungsfähigkeiten durchgeführt werden. Diese Methode hat den Vorteil, dass sie viel weniger Daten benötigt als andere, wodurch sich die Berechnungszeit auf Minuten oder Stunden reduziert.
Training von Grund auf (Training from Scratch). Bei dieser Methode muss ein Entwickler einen großen gelabelten Datensatz sammeln und eine Netzwerkarchitektur konfigurieren, die die Merkmale und das Modell lernen kann. Diese Technik ist besonders nützlich für neue Anwendungen sowie für Anwendungen mit einer großen Anzahl von Ausgabekategorien. Insgesamt handelt es sich jedoch um einen weniger verbreiteten Ansatz, da er übermäßig große Datenmengen erfordert, wodurch das Training Tage oder Wochen dauern kann.
Dropout. Diese Methode versucht, das Problem der Überanpassung in Netzwerken mit großen Mengen an Parametern zu lösen, indem Einheiten und ihre Verbindungen während des Trainings zufällig aus dem neuronalen Netzwerk entfernt werden. Es wurde bewiesen, dass die Dropout-Methode die Leistung von neuronalen Netzwerken bei überwachten Lernaufgaben in Bereichen wie Spracherkennung, Dokumentenklassifizierung und Computerbiologie verbessern kann.
Neuronale Netze mit Deep Learning?
Den meisten Deep-Learning-Modellen liegt eine Art fortschrittlicher Algorithmus für maschinelles Lernen zugrunde, der als künstliches neuronales Netzwerk bekannt ist. Aus diesem Grund wird Deep Learning manchmal auch als Deep Neural Learning oder Deep Neural Networking bezeichnet.
Neuronale Netzwerke gibt es in verschiedenen Formen, darunter rekurrente neuronale Netzwerke, konvolutionäre neuronale Netzwerke, künstliche neuronale Netzwerke und neuronale Feedforward-Netzwerke, und jedes hat Vorteile für bestimmte Anwendungsfälle. Sie funktionieren jedoch alle auf ähnliche Weise, indem sie Daten einspeisen und das Modell selbst herausfinden lassen, ob es die richtige Interpretation oder Entscheidung über ein bestimmtes Datenelement getroffen hat.
Neuronale Netzwerke arbeiten nach dem Prinzip Trail and Error und benötigen daher große Mengen an Daten, die sie trainieren können. Es ist kein Zufall, dass neuronale Netzwerke erst populär wurden, nachdem die meisten Unternehmen Big Data Analytics eingeführt und große Datenmengen angehäuft hatten. Da es sich bei den ersten Iterationen des Modells um Vermutungen über den Inhalt eines Bildes oder Teile von Sprache handelt, müssen die in der Trainingsphase verwendeten Daten gelabelt werden, damit das Modell erkennen kann, ob seine Vermutung richtig war.
Das bedeutet, obwohl viele Unternehmen, die Big Data nutzen, über große Datenmengen verfügen, sind unstrukturierte Daten weniger hilfreich. Unstrukturierte Daten können von einem Deep-Learning-Modell erst dann analysiert werden, wenn es trainiert wurde und einen akzeptablen Genauigkeitsgrad erreicht hat, aber Deep-Learning-Modelle können nicht auf unstrukturierten Daten trainiert werden.
Beispiele für Deep Learning
Da Deep-Learning-Modelle Informationen auf ähnliche Weise wie das menschliche Gehirn verarbeiten, können sie auf viele Aufgaben angewendet werden, die Menschen erledigen. Deep Learning wird derzeit in den meisten gängigen Tools zur Bilderkennung, Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) und Spracherkennungssoftware eingesetzt. Diese Tools tauchen allmählich in so unterschiedlichen Anwendungen wie selbstfahrenden Autos und Sprachübersetzungsdiensten auf.
Zu den Anwendungsfällen für Deep Learning gehören heute alle Arten von Big-Data-Analyseanwendungen, insbesondere solche, die sich auf NLP, Sprachübersetzung, medizinische Diagnose, Börsensignale, Netzwerksicherheit und Bilderkennung konzentrieren.
Zu den spezifischen Bereichen, in denen Deep Learning derzeit eingesetzt wird, gehören:
- Customer Experience (CX). Deep-Learning-Modelle werden bereits für Chatbots eingesetzt. Mit zunehmender Reife wird erwartet, dass Deep Learning in verschiedenen Unternehmen eingesetzt wird, um CX zu verbessern und die Kundenzufriedenheit zu erhöhen.
- Texterstellung. Maschinen lernen die Grammatik und den Stil eines Textes und verwenden dieses Modell dann, um automatisch einen komplett neuen Text zu erstellen, der der korrekten Rechtschreibung, Grammatik und dem Stil des ursprünglichen Textes entspricht.
- Luft- und Raumfahrt und Militär. Deep Learning wird eingesetzt, um Objekte von Satelliten zu erkennen, die Gebiete von Interesse sowie sichere oder unsichere Zonen für Truppen identifizieren.
- Industrielle Automatisierung. Deep Learning verbessert die Sicherheit der Arbeiter in Umgebungen wie Fabriken und Lagerhäusern, indem es Dienste bereitstellt, die automatisch erkennen, wenn ein Arbeiter oder ein Objekt einer Maschine zu nahe kommt.
- Hinzufügen von Farbe. Mit Deep-Learning-Modellen können Schwarz-Weiß-Fotos und Videos Farbe hinzugefügt werden. In der Vergangenheit war dies ein zeitaufwendiger, manueller Prozess.
- Medizinische Forschung. Krebsforscher haben begonnen, Deep Learning in ihre Praxis zu implementieren, um Krebszellen automatisch zu erkennen.
- Computer Vision. Deep Learning hat Computer Vision stark verbessert und bietet Computern eine extreme Genauigkeit bei der Objekterkennung und Bildklassifizierung, -wiederherstellung und -segmentierung.
Grenzen und Herausforderungen
Die größte Einschränkung von Deep-Learning-Modellen ist, dass sie durch Beobachtungen lernen. Das bedeutet, dass sie nur wissen, was in den Daten war, mit denen sie trainiert wurden. Wenn ein Benutzer eine kleine Menge an Daten hat oder diese aus einer bestimmten Quelle stammen, die nicht unbedingt repräsentativ für den breiteren Funktionsbereich ist, werden die Modelle nicht auf eine Weise lernen, die verallgemeinerbar ist.
Die Frage der Verzerrungen ist ebenfalls ein großes Problem für Deep-Learning-Modelle. Wenn ein Modell auf Daten trainiert, die Verzerrungen enthalten, wird das Modell diese Verzerrungen in seinen Vorhersagen reproduzieren. Dies ist ein großes Problem für Deep-Learning-Programmierer, da Modelle lernen, auf der Grundlage von subtilen Variationen in Datenelementen zu differenzieren. Oft sind die Faktoren, die es als wichtig erachtet, dem Programmierer nicht explizit bekannt. Das bedeutet zum Beispiel, dass ein Gesichtserkennungsmodell Feststellungen über die Eigenschaften von Menschen auf der Grundlage von Dingen wie Rasse oder Geschlecht treffen kann, ohne dass der Programmierer dies bemerkt.
Auch die Lernrate kann zu einer großen Herausforderung für Deep-Learning-Modelle werden. Wenn die Rate zu hoch ist, konvergiert das Modell zu schnell, was zu einer suboptimalen Lösung führt. Wenn die Rate zu niedrig ist, kann der Prozess stecken bleiben, und es wird noch schwieriger, eine Lösung zu erreichen.
Auch die Hardwareanforderungen für Deep-Learning-Modelle können zu Einschränkungen führen. Um eine verbesserte Effizienz und einen geringeren Zeitaufwand zu gewährleisten, sind leistungsstarke Multicore-Grafikprozessoren (GPUs) und andere ähnliche Verarbeitungseinheiten erforderlich. Diese Einheiten sind jedoch teuer und verbrauchen große Mengen an Energie. Weitere Hardwareanforderungen sind Arbeitsspeicher und ein Festplattenlaufwerk (HDD) oder ein RAM-basiertes Solid-State Drive (SSD).
Weitere Einschränkungen und Herausforderungen sind unter anderem:
- Deep Learning erfordert große Mengen an Daten. Außerdem benötigen die leistungsfähigeren und genaueren Modelle mehr Parameter, die wiederum mehr Daten erfordern.
- Einmal trainiert, werden Deep-Learning-Modelle unflexibel und können nicht mit Multitasking umgehen. Sie können zwar effiziente und genaue Lösungen liefern, aber nur für ein bestimmtes Problem. Selbst das Lösen eines ähnlichen Problems würde ein erneutes Training des Systems erfordern.
- Jede Anwendung, die logisches Denken erfordert (zum Beispiel Programmieren oder die Anwendung wissenschaftlicher Methoden), langfristige Planung und algorithmenähnliche Datenmanipulation ist völlig jenseits dessen, was aktuelle Deep-Learning-Techniken leisten können, selbst bei großen Datenmengen.
Deep Learning versus Machine Learning
Deep Learning ist eine Untergruppe des Machine Learning, die sich durch die Art und Weise unterscheidet, wie sie Probleme löst. Machine Learning erfordert einen Domänenexperten, um die meisten angewandten Merkmale zu identifizieren. Deep Learning hingegen versteht Features inkrementell, sodass keine Domänenexpertise erforderlich ist.
Dies führt dazu, dass Deep-Learning-Algorithmen viel länger zum Trainieren brauchen als Machine-Learning-Algorithmen, die nur ein paar Sekunden bis ein paar Stunden benötigen. Beim Testen verhält es sich jedoch umgekehrt. Deep-Learning-Algorithmen benötigen viel weniger Zeit für Tests als Machine-Learning-Algorithmen, deren Testzeit mit der Größe der Daten steigt.

Außerdem sind für Machine Learning nicht die gleichen teuren High-End-Maschinen und leistungsstarken GPUs erforderlich wie für Deep Learning.
Letztendlich entscheiden sich viele Data Scientists für klassisches Machine Learning gegenüber Deep Learning aufgrund der besseren Interpretierbarkeit beziehungsweise der Fähigkeit, die Lösungen sinnvoll zu interpretieren. Machine-Learning-Algorithmen werden auch bevorzugt, wenn die Datenmenge klein ist.
Zu den Fällen, in denen Deep Learning vorzuziehen ist, gehören Situationen, in denen eine große Datenmenge vorliegt, ein Mangel an Domänenverständnis für die Feature-Introspektion oder komplexe Probleme, wie zum Beispiel Spracherkennung und NLP.







