Big Data
Was ist Big Data?
Big Data ist eine Kombination aus strukturierten, semistrukturierten und unstrukturierten Daten, die von Unternehmen gesammelt und für Machine-Learning-Projekte, Predictive Modeling und andere Advanced-Analytics-Anwendungen verwendet werden.
Systeme, die Big Data verarbeiten und speichern, sind zu einer gängigen Komponente von Datenmanagementarchitekturen in Unternehmen geworden. Big Data wird häufig durch die 3Vs charakterisiert: das große Datenvolumen in vielen Umgebungen (Volume), die große Vielfalt an Datentypen (Variety), die in Big-Data-Systemen gespeichert werden, und die Geschwindigkeit (Velocity), mit der die Daten erzeugt, gesammelt und verarbeitet werden.
Diese Merkmale wurden erstmals 2001 von Doug Laney, damals Analyst bei Meta Group Inc. Identifiziert. Gartner hat diese nach der Übernahme der Meta Group im Jahr 2005 weiter popularisiert. In jüngerer Zeit wurden verschiedene Beschreibungen von Big Data um weitere Vs ergänzt, darunter Wahrhaftigkeit (Veracity), Wert (Value) und Variabilität (Variability).
Obwohl Big Data nicht mit einem bestimmten Datenvolumen gleichzusetzen ist, umfassen Big-Data-Implementierungen oft Terabytes (TB), Petabytes (PB) und sogar Exabytes (EB) an Daten, die im Laufe der Zeit erfasst werden.
Bedeutung von Big Data
Unternehmen nutzen die in ihren Systemen gesammelten Big Data, um ihre Abläufe zu verbessern, einen besseren Kundenservice zu bieten, personalisierte Marketingkampagnen auf der Grundlage spezifischer Kundenpräferenzen zu erstellen und letztendlich die Rentabilität zu steigern. Unternehmen, die Big Data nutzen, haben einen potenziellen Wettbewerbsvorteil gegenüber Unternehmen, die dies nicht tun, da sie in der Lage sind, schnellere und fundiertere Geschäftsentscheidungen zu treffen, sofern sie die Daten effektiv nutzen.
Big Data kann Unternehmen beispielsweise wertvolle Einblicke zu ihren Kunden liefern, die zur Verfeinerung von Marketingkampagnen und -techniken genutzt werden können, um die Kundenbindung (Customer Engagement) und Conversion Rate zu erhöhen.
Darüber hinaus ermöglicht die Nutzung von Big Data den Unternehmen, zunehmend kundenorientiert zu werden. Historische und Echtzeitdaten können verwendet werden, um die sich entwickelnden Vorlieben der Verbraucher zu bewerten, was es Unternehmen ermöglicht, ihre Marketingstrategien zu aktualisieren und zu verbessern und besser auf die Wünsche und Bedürfnisse der Kunden einzugehen.
Big Data wird auch von medizinischen Forschern genutzt, um Risikofaktoren für Krankheiten zu identifizieren, und von Ärzten, um die Diagnose von Krankheiten zu unterstützen. Darüber hinaus versorgen Daten aus elektronischen Gesundheitsakten, sozialen Medien, dem Internet und anderen Quellen Gesundheitsorganisationen und Regierungsbehörden mit aktuellen Informationen über Bedrohungen oder Ausbrüche von Infektionskrankheiten.
In der Energiebranche hilft Big Data Öl- und Gasunternehmen, potenzielle Bohrstellen zu identifizieren und den Betrieb von Pipelines zu überwachen; ebenso nutzen Versorgungsunternehmen Daten, um Stromnetze zu überwachen. Finanzdienstleister setzen Big-Data-Systeme ein für das Risikomanagement und die Echtzeitanalyse von Marktdaten. Hersteller und Transportunternehmen verlassen sich auf Big Data, um ihre Lieferketten zu verwalten und Lieferwege zu optimieren. Andere staatliche Anwendungen umfassen Notfallmaßnahmen, Verbrechensprävention und Smart-City-Initiativen.
Beispiele für Big Data
Big Data stammen aus unzähligen verschiedenen Quellen, wie zum Beispiel Geschäftstransaktionssystemen, Kundendatenbanken, medizinischen Aufzeichnungen, Internet-Click-Stream-Protokollen, mobilen Anwendungen, sozialen Netzwerken, wissenschaftlichen Forschungsspeichern, maschinengenerierten Daten und Echtzeit-Datensensoren, die in Internet-of-Things-Umgebungen (IoT) eingesetzt werden. Die Daten können in Big-Data-Systemen in ihrer Rohform belassen oder mit Data Mining Tools oder Datenaufbereitungssoftware vorverarbeitet werden, sodass sie für bestimmte Analysezwecke bereit sind.
Am Beispiel von Kundendaten sind die verschiedenen Analysezweige, die mit den in Big-Data-Sätzen gefundenen Informationen durchgeführt werden können, folgende:
- Vergleichende Analyse. Dies beinhaltet die Untersuchung von Metriken zum Nutzerverhalten und die Beobachtung des Kundenengagements in Echtzeit, um die Produkte, Dienstleistungen und die Markenautorität eines Unternehmens mit denen der Konkurrenz zu vergleichen.
- Soziale Medien. Hierbei werden Informationen darüber gesammelt, was Menschen in sozialen Medien über ein bestimmtes Unternehmen oder Produkt sagen, die über das hinausgehen, was in einer Umfrage oder einer Datenerhebung geliefert werden kann. Diese Daten können genutzt werden, um Zielgruppen für Marketingkampagnen zu identifizieren, indem die Aktivität rund um bestimmte Themen über verschiedene Quellen hinweg beobachtet wird.
- Marketinganalyse. Dazu gehören Informationen, die genutzt werden können, um die Werbung für neue Produkte, Dienstleistungen und Initiativen fundierter und innovativer zu gestalten.
- Kundenzufriedenheit und Stimmungsanalyse. Alle gesammelten Informationen können Aufschluss darüber geben, wie Kunden über ein Unternehmen oder eine Marke denken, ob es möglicherweise Probleme gibt, wie die Markentreue erhalten und wie der Kundenservice verbessert wird.
Die drei Vs aufschlüsseln
Das Datenvolumen (Volume) ist die am häufigsten zitierte Eigenschaft von Big Data. Eine Big-Data-Umgebung muss nicht zwangsläufig eine große Menge an Daten enthalten, aber die meisten tun dies aufgrund der Art der Daten, die in ihnen gesammelt und gespeichert werden. Clickstreams, Systemprotokolle und Stream-Processing-Systeme gehören zu den Quellen, die typischerweise laufend große Mengen an Big Data produzieren.
Big Data umfasst auch eine Vielzahl von Datentypen, einschließlich der folgenden:
- strukturierte Daten in Datenbanken und Data Warehouses, die auf Structured Query Language (SQL) basieren;
- unstrukturierte Daten, wie Text- und Dokumentdateien, die in Hadoop-Clustern oder NoSQL-Datenbanksystemen gespeichert sind; und
- semistrukturierte Daten, wie zum Beispiel Webserver-Protokolle oder Streaming-Daten von Sensoren.
All diese verschiedenen Datentypen können zusammen in einem Data Lake gespeichert werden, der typischerweise auf Hadoop oder einem Cloud-Object-Storage-Service basiert. Darüber hinaus umfassen Big-Data-Anwendungen oft mehrere Datenquellen, die sonst möglicherweise nicht integriert werden. Ein Big-Data-Analyseprojekt kann beispielsweise versuchen, den Erfolg eines Produkts und künftige Verkäufe einzuschätzen, indem vergangene Verkaufsdaten, Rückgabedaten und Online-Käuferbewertungsdaten für dieses Produkt korreliert werden.

Velocity (Geschwindigkeit) bezieht sich auf die Geschwindigkeit, mit der Big Data generiert, verarbeitet und analysiert wird. In vielen Fällen werden Big-Data-Datensätze in Echtzeit oder nahezu in Echtzeit aktualisiert, im Gegensatz zu den täglichen, wöchentlichen oder monatlichen Aktualisierungen, die in vielen traditionellen Data Warehouses vorgenommen werden.
Big-Data-Analyseanwendungen nehmen die eingehenden Daten auf, korrelieren und analysieren sie und geben dann eine Antwort oder ein Ergebnis basierend auf einer übergreifenden Abfrage aus. Das bedeutet, dass Data Scientists und andere Datenanalysten ein detailliertes Verständnis der verfügbaren Daten haben und ein gewisses Gespür dafür haben müssen, nach welchen Antworten sie suchen, um sicherzustellen, dass die Informationen, die sie erhalten, gültig und auf dem neuesten Stand sind.
Die Verwaltung der Datengeschwindigkeit ist auch wichtig, da sich Big Data Analytics auf Bereiche wie Machine Learning (ML) und künstliche Intelligenz (KI) ausweitet, wo analytische Prozesse automatisch Muster in den gesammelten Daten finden und diese zur Generierung von Erkenntnissen nutzen.
Weitere Merkmale von Big Data
Über die ursprünglichen 3Vs hinausgehend, bezieht sich die Wahrhaftigkeit oder Richtigkeit der Daten (Veracity) auf den Grad, wie weit man den Daten vertrauen kann. Unsichere Rohdaten, die aus verschiedenen Quellen gesammelt werden, wie zum Beispiel Social-Media-Plattformen und Webseiten, können zu schwerwiegenden Datenqualitätsproblemen führen, die unter Umständen nur schwer zu erkennen sind. Ein Unternehmen, das beispielsweise Big-Data-Sätze aus Hunderten von Quellen sammelt, kann möglicherweise ungenaue Daten identifizieren, aber seine Analysten benötigen Informationen zur Datenabfolge, um nachzuvollziehen, wo die Daten gespeichert sind, damit sie die Probleme korrigieren können.
Schlechte Daten führen zu ungenauen Analysen und untergraben den Wert von Business Analytics, da sie dazu führen, dass Führungskräfte den Daten als Ganzes misstrauen. Die Menge der unsicheren Daten in einem Unternehmen muss berücksichtigt werden, bevor sie in Big-Data-Analytics-Anwendungen verwendet werden. IT- und Analyseteams müssen außerdem sicherstellen, dass sie über genügend genaue Daten verfügen, um valide Ergebnisse zu erzielen.
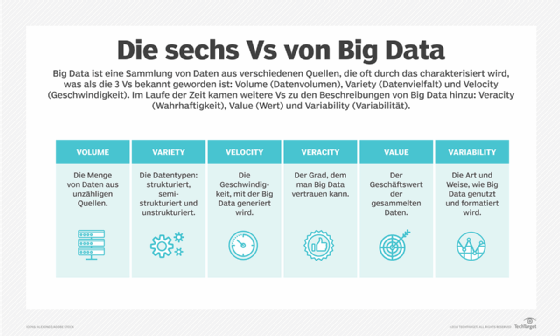
Einige Data Scientists fügen der Liste der Merkmale von Big Data ebenfalls einen Wert (Value) hinzu. Wie oben erläutert, haben nicht alle gesammelten Daten einen echten Geschäftswert, und die Verwendung ungenauer Daten kann die von Analyseanwendungen gelieferten Erkenntnisse schwächen. Es ist wichtig, dass Unternehmen Praktiken wie Datenbereinigung anwenden und bestätigen, dass sich die Daten auf relevante Geschäftsprobleme beziehen, bevor sie sie in einem Big-Data-Analyseprojekt verwenden.
Die Variabilität (Variability) gilt auch für Datensätze, die weniger konsistent sind als herkömmliche Transaktionsdaten und möglicherweise mehrere Bedeutungen haben oder von einer Datenquelle zur anderen unterschiedlich formatiert sind – Faktoren, die die Verarbeitung und Analyse der Daten weiter erschweren. Manche Leute schreiben Big Data noch mehr Vs zu. Data Scientists und Berater haben verschiedene Listen mit sieben bis zehn Vs erstellt.
Wie Big Data gespeichert und verarbeitet wird
Die Notwendigkeit, große Datenmengen schnell zu verarbeiten, stellt besondere Anforderungen an die zugrunde liegende Datenverarbeitungsinfrastruktur. Die Rechenleistung, die für die schnelle Verarbeitung riesiger Datenmengen und -arten erforderlich ist, kann einen einzelnen Server oder Server-Cluster überfordern. Unternehmen müssen für Big-Data-Aufgaben eine angemessene Verarbeitungskapazität bereitstellen, um die erforderliche Geschwindigkeit zu erreichen. Dies kann potenziell Hunderte oder Tausende von Servern erfordern, die die Verarbeitungsarbeit verteilen und in einer geclusterten Architektur zusammenarbeiten können, die oft auf Technologien wie Hadoop und Apache Spark basiert.
Eine solche Geschwindigkeit auf kosteneffektive Weise zu erreichen, ist ebenfalls eine Herausforderung. Viele Unternehmensleiter sind zurückhaltend, in eine umfangreiche Server- und Speicherinfrastruktur zu investieren, um Big Data Workloads zu unterstützen, insbesondere solche, die nicht rund um die Uhr laufen. Infolgedessen ist Public Cloud Computing mittweile ein primärer Weg für das Hosting von Big-Data-Systemen. Ein Public-Cloud-Anbieter kann Petabytes an Daten speichern und die erforderliche Anzahl an Servern hochskalieren, um ein Big-Data-Analyseprojekt abzuschließen. Das Unternehmen zahlt nur für die tatsächlich genutzte Speicher- und Rechenzeit, und die Cloud-Instanzen können abgeschaltet werden, bis man sie wieder benötigt.
Um die Service-Levels noch weiter zu verbessern, bieten Public-Cloud-Anbieter Big-Data-Funktionen über verwaltete Services an, unter anderem:
- Amazon EMR (ehemals Elastic MapReduce)
- Microsoft Azure HDInsight
- Google Cloud Dataproc
In Cloud-Umgebungen kann Big Data auf folgende Arten gespeichert werden:
- Hadoop Distributed File System (HDFS);
- kostengünstiger Cloud-Objektspeicher, wie zum Beispiel Amazon Simple Storage Service (S3);
- NoSQL-Datenbanken; und
- relationale Datenbanken.
Für Unternehmen, die Big-Data-Systeme lokal bereitstellen möchten, werden neben Hadoop und Spark auch die folgenden Open-Source-Technologien von Apache verwendet:
- YARN, der in Hadoop integrierte Ressourcenmanager und Job Scheduler, der für Yet Another Resource Negotiator steht, aber allgemein nur unter diesem Akronym bekannt ist;
- das MapReduce-Programmier-Framework, ebenfalls eine Kernkomponente von Hadoop;
- Kafka, eine Messaging- und Daten-Streaming-Plattform;
- die HBase-Datenbank; und
- SQL on Hadoop Query Engines, wie Drill, Hive, Impala und Presto.
Anwender können die Open-Source-Versionen der Technologien selbst installieren oder auf kommerzielle Big-Data-Plattformen zurückgreifen, die von Cloudera, welche im Januar 2019 mit dem ehemaligen Konkurrenten Hortonworks fusionierte, oder von Hewlett Packard Enterprise (HPE), die im August 2019 MapR übernahmen, angeboten werden. Beide Anbieter stellen auch Cloud-Lösungen zur Verfügung.
Herausforderungen bei Big Data
Neben den Problemen mit der Verarbeitungskapazität und den Kosten ist das Design einer Big-Data-Architektur eine weitere häufige Herausforderung für Anwender. Big-Data-Systeme müssen auf die speziellen Anforderungen eines Unternehmens zugeschnitten werden – eine Art Heimwerkerprojekt, das IT-Teams und Anwendungsentwickler dazu zwingt, aus allen verfügbaren Technologien eine Reihe von Tools zusammenzustellen. Die Bereitstellung und Verwaltung von Big-Data-Systemen erfordert außerdem neue Fähigkeiten im Vergleich zu denen von Datenbankadministratoren (DBA) und Entwicklern, die sich auf relationale Software konzentrieren.
Beide Probleme können durch die Nutzung eines verwalteten Cloud-Dienstes abgeschwächt werden, doch IT-Manager müssen die Cloud-Nutzung genau im Auge behalten, um sicherzustellen, dass die Kosten nicht aus dem Ruder laufen. Auch die Migration von lokalen Datensätzen und Verarbeitungslasten in die Cloud ist für Unternehmen oft ein komplexer Prozess.
Die Daten in Big-Data-Systemen für Data Scientists und andere Analysten zugänglich zu machen, ist ebenfalls eine Herausforderung, insbesondere in verteilten Umgebungen, die eine Mischung aus verschiedenen Plattformen und Datenspeichern umfassen. Um Analysten bei der Suche nach relevanten Daten zu unterstützen, arbeiten IT- und Analyseteams zunehmend an der Erstellung von Datenkatalogen, die Funktionen zur Verwaltung von Metadaten und der Datenabfolge enthalten. Datenqualität und Data Governance müssen ebenfalls Priorität haben, um sicherzustellen, dass Big-Data-Sätze sauber und konsistent sind und richtig verwendet werden.
Praktiken und Regeln zum Sammeln von Big Data
Viele Jahre lang hatten Unternehmen nur wenige Einschränkungen bezüglich der Daten, die sie von ihren Kunden sammelten. Doch mit der zunehmenden Sammlung und Nutzung von Big Data hat auch der Datenmissbrauch zugenommen. Besorgte Bürger, die den falschen Umgang mit ihren persönlichen Daten erlebt haben oder Opfer einer Datenpanne wurden, fordern daher immer wieder Gesetze zur Transparenz der Datensammlung und zum Schutz der Verbraucherdaten.
Dies hat die Europäische Union dazu veranlasst, die Datenschutz-Grundverordnung (EU-DSGVO) zu verabschieden, die im Mai 2018 in Kraft getreten ist; sie schränkt die Arten von Daten ein, die Organisationen sammeln dürfen, und erfordert die Zustimmung von Einzelpersonen oder die Einhaltung anderer festgelegter rechtmäßiger Gründe für die Sammlung personenbezogener Daten. Die EU-DSGVO beinhaltet auch ein Recht auf Vergessenwerden, das es EU-Bürgern ermöglicht, Unternehmen um die Löschung ihrer Daten zu bitten.
Während es in den USA keine ähnlichen Bundesgesetze gibt, zielt der California Consumer Privacy Act (CCPA) darauf ab, den Einwohnern Kaliforniens mehr Kontrolle über die Sammlung und Verwendung ihrer persönlichen Daten durch Unternehmen zu geben. Der CCPA ist am 1. Januar 2020 in Kraft getreten. Darüber hinaus untersuchen Regierungsbeamte in den USA die Praktiken im Umgang mit Daten, insbesondere bei Unternehmen, die Verbraucherdaten sammeln und sie an andere Unternehmen zur unbekannten Verwendung verkaufen.
Die menschliche Seite von Big Data Analytics
Letztendlich hängen der Wert und die Effektivität von Big Data von den Mitarbeitern ab, die damit beauftragt sind, die Daten zu verstehen und die richtigen Abfragen zu formulieren, um Big-Data-Analyseprojekte zu steuern. Einige Big Data Tools decken spezialisierte Nischen ab und ermöglichen es auch weniger technisch versierten Anwendern, alltägliche Geschäftsdaten in Predictive-Analytics-Anwendungen zu nutzen. Andere Technologien – wie Hadoop-basierte Big Data Appliances – helfen Unternehmen bei der Implementierung einer geeigneten Infrastruktur, um Big-Data-Projekte in Angriff zu nehmen.
Big Data kann Small Data gegenübergestellt werden, einem anderen sich entwickelnden Begriff, der oft verwendet wird, um Daten zu beschreiben, deren Volumen und Format leicht für Self-Service-Analysen verwendet werden können. Eine häufig zitierte Redewendung lautet: Big Data ist für Maschinen, Small Data ist für Menschen.






