Die sechs Vs von Big Data
Was sind die 6 V's von Big Data?
Die Vs von Big Data – Velocity, Volume, Value, Variety, Veracity und Variability – sind die sechs wichtigsten und inhärent Merkmale von Big Data. Data Scientists (Datenwissenschaftler), die diese Eigenschaften kennen, können mehr Wert aus ihren Daten ziehen und gleichzeitig ihre Organisationen kundenorientierter gestalten.
Anfang des 21. Jahrhunderts sprach man zunächst bei Big Data von den drei V's – Volume, Velocity und Variety. Im Laufe der Zeit kamen weitere V's hinzu – Value, Veracity und Variability – um es Datenwissenschaftlern zu ermöglichen, die wichtigen Merkmale von Big Data effektiver zu formulieren und zu kommunizieren.
Was ist Big Data?
Big Data besteht aus einer Kombination aus unstrukturierten, halbstrukturierten oder strukturierten Daten, die von Unternehmen gesammelt werden. Diese Datensätze können ausgewertet werden, um Erkenntnisse zu gewinnen und in Projekten für maschinelles Lernen, Vorhersagemodelle und andere fortschrittliche Analyseanwendungen zu nutzen.
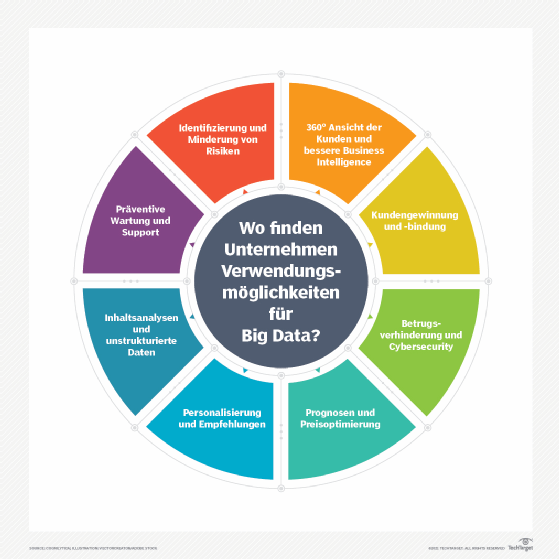
Big Data lässt sich nutzen, um Abläufe zu verbessern, einen besseren Kundenservice zu bieten und individualisierte Marketingkampagnen zu erstellen – alles Dinge, die den Wert eines Unternehmens steigern können. Big-Data-Analysenkönnen Unternehmen beispielsweise wertvolle Erkenntnisse über ihre Kunden liefern, die dann zur Verfeinerung von Marketingmaßnahmen verwendet werden können, um die Kundenbindung und die Konversionsraten zu erhöhen.
Big Data kann im Gesundheitswesen eingesetzt werden, um Krankheitsrisikofaktoren zu ermitteln, oder Ärzte können Big Data nutzen, um Krankheiten bei Patienten zu diagnostizieren. Die Energiebranche kann Big Data zur Überwachung von Stromnetzen, zum Risikomanagement oder zur Analyse von Marktdaten in Echtzeit einsetzen.
Unternehmen, die Big Data nutzen, haben einen potenziellen Wettbewerbsvorteil gegenüber jenen, die dies nicht tun, da sie schnellere und fundiertere Geschäftsentscheidungen treffen können, die durch die ausgewerteten Daten ermöglicht werden.
Was sind die 6 V's?
Die 6 Vs sind wie folgt definiert:
Velocity – Die Geschwindigkeit beschreibt, wie schnell die Daten erstellt werden und wie schnell sie sich bewegen.
- Volume – Die Menge der Daten, die als Big Data bezeichnet wird.
- Value – Der Wert, den die Daten bieten.
- Variety – Die Vielfalt der Datentypen.
- Veracity – Die Wahrhaftigkeit ist die Qualität und Genauigkeit der Daten.
- Variability – Datenvariabilität, auch bekannt als Streuung oder Dispersion, bezieht sich darauf, wie weit ein Datensatz gestreut ist.
Velocity – Geschwindigkeit
Die Geschwindigkeit bezieht sich darauf, wie schnell Daten erzeugt werden und wie schnell sie sich bewegen. Dies ist ein wichtiger Aspekt für Unternehmen, die einen zügigen Datenfluss benötigen, damit die Daten zum richtigen Zeitpunkt verfügbar sind, um die bestmöglichen Geschäftsentscheidungen zu treffen.
Ein Unternehmen, das Big Data einsetzt, hat einen großen und kontinuierlichen Datenfluss, der erstellt und an sein Endziel gesendet wird. Die Daten können aus Quellen wie Maschinen, Netzwerken, Smartphones oder sozialen Medienstammen. Die Geschwindigkeit bezieht sich auf das Tempo, mit dem diese Informationen eintreffen – beispielsweise wie viele Beiträge in sozialen Medien pro Tag aufgenommen werden – sowie auf die Geschwindigkeit, mit der sie verarbeitet und analysiert werden müssen – oft schnell und manchmal fast in Echtzeit.
Ein Beispiel aus dem Gesundheitswesen: Viele medizinische Geräte sind heute darauf ausgelegt, Patienten zu überwachen und Daten zu sammeln. Von medizinischen Geräten im Krankenhaus bis hin zu tragbaren Geräten müssen die gesammelten Daten schnell an ihren Bestimmungsort gesendet und analysiert werden.
In einigen Fällen kann es jedoch besser sein, eine begrenzte Menge an gesammelten Daten zu haben, als mehr Daten zu sammeln, als eine Organisation verarbeiten kann – denn dies kann zu einer langsameren Datengeschwindigkeit führen.
Volume – Menge/Umfang
Das Volumen bezieht sich auf die Menge der vorhandenen Daten. Das Volumen ist sozusagen die Basis von Big Data, da es sich um die ursprüngliche Größe und Menge der gesammelten Daten handelt. Wenn das Datenvolumen groß genug ist, kann man es als Big Data bezeichnen. Was als Big Data gilt, ist jedoch relativ und hängt von der verfügbaren Rechenleistung auf dem Markt ab.
Ein Unternehmen, das Hunderte von Geschäften in mehreren Bundesstaaten betreibt, generiert beispielsweise Millionen von Transaktionen pro Tag. Dies gilt als Big Data, und die durchschnittliche Anzahl der Gesamttransaktionen pro Tag in allen Geschäften stellt das Volumen dar.
Value – Wert
Der Begriff Wert bezieht sich auf die Vorteile, die Big Data bieten kann, und bezieht sich direkt darauf, was Unternehmen mit den gesammelten Daten tun können. Die Fähigkeit, aus Big Data einen Nutzen zu ziehen, ist eine Voraussetzung, da der Wert von Big Data in Abhängigkeit von den Erkenntnissen, die aus ihnen gewonnen werden können, erheblich steigt.
Unternehmen können Big-Data-Tools zum Sammeln und Analysieren der Daten verwenden, aber die Art und Weise, wie sie aus diesen Daten einen Wert ableiten, sollte individuell sein. Tools wie Apache Hadoop können Unternehmen dabei helfen, diese riesigen Datenmengen zu speichern, zu bereinigen und schnell zu verarbeiten.
Ein gutes Beispiel für den Nutzen von Big Data ist die Erfassung individueller Kundendaten. Wenn ein Unternehmen ein Profil seiner Kunden erstellen kann, ist es in der Lage, deren Erfahrungen in Marketing und Vertrieb zu personalisieren, die Effizienz der Kontakte zu verbessern und eine höhere Kundenzufriedenheit zu erreichen.
Variety – Vielfalt
Variety bezieht sich auf die Vielfalt der Datentypen. Ein Unternehmen kann Daten aus verschiedenen Datenquellen beziehen, die von unterschiedlichem Wert sein können. Die Daten können aus Quellen innerhalb und außerhalb des Unternehmens stammen. Die Herausforderung bei der Datenvielfalt besteht in der Standardisierung und Verteilung aller gesammelten Daten.
Wie bereits erwähnt, können die gesammelten Daten unstrukturiert, halbstrukturiert oder strukturiert sein. Unstrukturierte Daten sind Daten, die unorganisiert sind und in verschiedenen Dateien oder Formaten vorliegen. Unstrukturierte Daten eignen sich in der Regel nicht für eine herkömmliche relationale Datenbank, da sie nicht in herkömmliche Datenmodelle passen. Bei halbstrukturierten Daten handelt es sich um Daten, die nicht in einem spezialisierten Repository organisiert sind, sondern über zugehörige Informationen, wie zum Beispiel Metadaten, verfügen. Dadurch sind sie leichter zu verarbeiten als unstrukturierte Daten. Strukturierte Daten hingegen sind Daten, die in einem formatierten Repository organisiert sind. Dies bedeutet, dass die Daten für eine effektive Datenverarbeitung und -analyse besser adressierbar sind.
Auch Rohdaten zählen zu den Datentypen. Während Rohdaten in andere Kategorien fallen können – strukturiert, halbstrukturiert oder unstrukturiert – werden sie als roh bezeichnet, wenn sie keinerlei Verarbeitung erfahren haben. In den meisten Fällen handelt es sich bei Rohdaten um Daten, die von anderen Organisationen importiert oder von Benutzern eingereicht oder eingegeben wurden. Daten aus sozialen Medien fallen oft in diese Kategorie.
Ein konkreteres Beispiel wäre ein Unternehmen, das eine Vielzahl von Daten über seine Kunden sammelt. Dabei kann es sich um strukturierte Daten handeln, die aus Transaktionen stammen, oder um unstrukturierte Social-Media-Posts und Call-Center-Texte. Viele dieser Daten können in Form von Rohdaten eingehen, die vor der Verarbeitung bereinigt werden müssen.
Veracity – Wahrhaftigkeit
Wahrhaftigkeit bezieht sich auf die Qualität, Genauigkeit, Integrität und Glaubwürdigkeit der Daten. Die gesammelten Daten könnten Lücken aufweisen, ungenau sein oder keinen echten, wertvollen Einblick bieten. Die Wahrhaftigkeit bezieht sich auf den Grad des Vertrauens in die gesammelten Daten.
Daten können manchmal unübersichtlich und schwierig zu verwenden sein. Eine große Menge an Daten kann mehr Verwirrung stiften als Erkenntnisse bringen, wenn sie unvollständig sind. Wenn beispielsweise im medizinischen Bereich die Daten darüber, welche Medikamente ein Patient einnimmt, unvollständig sind, könnte das Leben des Patienten gefährdet sein.
Sowohl der Wert als auch die Wahrhaftigkeit von Daten tragen dazu bei, die Qualität und die aus ihnen gewonnenen Erkenntnisse zu definieren. Schwellenwerte für den Wahrheitsgehalt von Daten gibt es oft – und sollte es auch geben – in einem Unternehmen auf der Führungsebene, um festzustellen, ob die Daten für die Entscheidungsfindung auf höchster Ebene geeignet sind.
Wo könnten Warnanzeichen über den Wahrheitsgehalt von Daten auftauchen? Zum Beispiel könnte es an einer ordnungsgemäßen Datenherkunft fehlen, das heißt an einer überprüfbaren Rückverfolgung ihrer Herkunft und Bewegung.
Variability – Variabilität
Die obigen 5 V decken einen großen Bereich ab und tragen wesentlich zur Klärung der richtigen Verwendung von Big Data bei. Aber es gibt noch ein weiteres V, das ernsthaft in Betracht gezogen werden sollte – die Variabilität – die nicht so sehr Big Data definiert, sondern vielmehr die Notwendigkeit unterstreicht, sie gut zu verwalten.
Variabilität bezieht sich auf Unstimmigkeiten bei der Verwendung oder dem Fluss von Big Data. Im Falle von Big Data kann ein Unternehmen mehr als eine Definition für bestimmte Daten verwenden. In einem Versicherungsunternehmen könnte beispielsweise eine Abteilung einen Satz von Risikoschwellenwerten verwenden, während eine andere Abteilung einen anderen Satz verwendet. Im zweiten Fall können Daten, die dezentral in die Datenspeicher des Unternehmens einfließen – ohne gemeinsamen Eingangspunkt oder vorherige Validierung – ihren Weg in verschiedene Systeme finden, die sie verändern, was zu widersprüchlichen Quellen der Wahrheit auf der Berichtsseite führt.
Um die Variabilität von Big Data zu minimieren, müssen die Datenflüsse sorgfältig konstruiert werden, wenn die Daten die Systeme des Unternehmens durchlaufen – von den Transaktions- bis zu den Analysesystemen und allem, was dazwischen liegt. Der größte Vorteil ist die Wahrhaftigkeit von Big Data, denn eine konsistente Datennutzung führt zu stabileren Berichten und Analysen und damit zu mehr Vertrauen.






