Relationale Datenbank
Was ist eine relationale Datenbank?
Eine relationale Datenbank ist eine Art von Datenbank, die Datenpunkte mit definierten Beziehungen für einen einfachen Zugriff organisiert. Im relationalen Datenbankmodell bleiben die Datenstrukturen – Datentabellen, Indizes und Ansichten – von den physischen Speicherstrukturen getrennt, sodass Datenbankadministratoren den physischen Datenspeicher bearbeiten können, ohne die logische Datenstruktur zu beeinflussen.
In Unternehmen werden relationale Datenbanken verwendet, um Daten zu organisieren und Beziehungen zwischen wichtigen Datenpunkten zu identifizieren. Sie erleichtern das Sortieren und Auffinden von Informationen, wodurch Unternehmen Geschäftsentscheidungen effizienter treffen und Kosten minimieren können. Sie eignen sich gut für strukturierte Daten.
Wie funktioniert eine relationale Datenbank?
Relationale Datenbanken organisieren Daten in einer tabellarischen Struktur. Diese Struktur erleichtert das Auffinden von Beziehungen zwischen Datenpunkten.
Die Tabellen sind in Zeilen und Spalten unterteilt. Jede Zeile stellt einen einzelnen Datensatz dar und jede Spalte enthält Attribute und Werte.
Jede Zeile enthält einen Datensatz mit einem eindeutigen Identifikator, der als Primärschlüssel bezeichnet wird. Neben der eindeutigen Identifizierung jedes Datensatzes in einer Tabelle stellen Primärschlüssel auch sicher, dass keine doppelten Zeilen vorhanden sind. Jeder Datensatz weist jedem Merkmal einen Wert zu, wodurch Beziehungen zwischen Datenpunkten leicht zu erkennen sind.
Zusammen stellen sowohl die Zeilen als auch die Spalten in der Tabelle eine Sammlung verwandter Werte eines Objekts oder einer Entität dar.
Verschiedene Tabellen in einer relationalen Datenbank können auch miteinander verknüpft werden, um tiefere Einblicke zwischen verschiedenen Datenpunkten zu erhalten. Dies geschieht mithilfe von Fremdschlüsseln. Ein Fremdschlüssel verbindet eine oder mehrere Spalten in einer Tabelle mit einem Primärschlüssel in einer anderen Tabelle. Er stellt im Wesentlichen eine Verbindung zwischen zwei Tabellen her. Der Fremdschlüssel in einer Tabelle definiert die Beziehungen in einer anderen Tabelle.

Ein relationales Datenbankmanagementsystem (RDBMS) wird zur Verwaltung relationaler Datenbanken verwendet. Zu den Hauptfunktionen eines RDBMS gehören Datenspeicherung, -abruf, -manipulation, Datensicherheit und -sicherung.
Die Standard-Benutzer- und Programmschnittstelle (API) einer relationalen Datenbank ist die Structured Query Language (SQL). SQL-Anweisungen werden sowohl für interaktive Abfragen von Informationen aus einer relationalen Datenbank als auch für die Datenerfassung für Berichte verwendet. Definierte Datenintegritätsregeln müssen befolgt werden, um sicherzustellen, dass die relationale Datenbank korrekt und zugänglich ist.
Wie ist ein relationales Datenbankmodell aufgebaut?
E. F. Codd, damals Programmierer bei IBM, erfand 1970 die relationale Datenbank. In seinem Aufsatz A Relational Model of Data for Large Shared Data Banks schlug Codd vor, Daten nicht mehr in hierarchischen oder navigatorischen Strukturen zu speichern, sondern in einer tabellarischen Struktur aus Tabellen mit Zeilen und Spalten zu organisieren.
Jede Tabelle, manchmal auch als Relation bezeichnet, in einer relationalen Datenbank enthält eine oder mehrere Datenkategorien in Spalten oder Attributen. Jede Zeile, auch als Datensatz oder Tupel bezeichnet, enthält eine eindeutige Instanz von Daten oder einen Schlüssel für die durch die Spalten definierten Kategorien. Jede Tabelle hat einen eindeutigen Primärschlüssel, der die Informationen in einer Tabelle identifiziert. Die Beziehung zwischen Tabellen kann durch die Verwendung von Fremdschlüsseln festgelegt werden – ein Feld in einer Tabelle, das mit dem Primärschlüssel einer anderen Tabelle verknüpft ist.
Eine typische Datenbank für Bestellungen würde beispielsweise eine Tabelle enthalten, die einen Kunden mit Spalten für Name, Adresse und Telefonnummer beschreibt. Eine andere Tabelle würde eine Bestellung beschreiben, einschließlich Informationen wie Produkt, Kunde, Datum und Verkaufspreis.
Ein Benutzer kann einen Datenbankbericht mit den von ihm benötigten Daten abrufen. Ein Filialleiter möchte beispielsweise einen Bericht über alle Kunden, die nach einem bestimmten Datum Produkte gekauft haben. Ein Finanzmanager im selben Unternehmen kann aus denselben Tabellen einen Bericht über Benutzerkonten erhalten, die noch Waren bezahlen müssen.
Beim Erstellen einer relationalen Datenbank definieren Benutzer den Wertebereich möglicher Werte in einer Datenspalte und Einschränkungen, die für diesen Datenwert gelten können. Beispielsweise kann ein Wertebereich möglicher Produkte bis zu zehn mögliche Produktnamen zulassen, in einer Tabelle sind jedoch nur drei dieser Produktnamen spezifizierbar.
Zwei Einschränkungen beziehen sich auf die Datenintegrität und die Primär- und Fremdschlüssel:
- Die Entitätsintegrität stellt sicher, dass der Primärschlüssel in einer Tabelle eindeutig ist und der Wert nicht auf null gesetzt wird.
- Die referenzielle Integrität erfordert, dass jeder Wert in einer Fremdschlüsselspalte im Primärschlüssel der Tabelle gefunden wird, aus der er stammt.
Darüber hinaus verfügen relationale Datenbanken über physische Datenunabhängigkeit. Dies bezieht sich auf die Fähigkeit eines Systems, Änderungen am inneren Schema vorzunehmen, ohne die externen Schemata oder Anwendungsprogramme zu verändern. Zu den Änderungen am inneren Schema gehören:
- Verwendung neuer Speichergeräte
- Indizes ändern
- von einer bestimmten Zugriffsmethode zu einer anderen wechseln
- verschiedene Datenstrukturen verwenden
- verschiedene Speicherstrukturen oder Dateiorganisationen verwenden
Logische Datenunabhängigkeit ist die Fähigkeit eines Systems, das konzeptionelle Schema zu verwalten, ohne das externe Schema oder die Anwendungsprogramme zu ändern. Änderungen am konzeptionellen Schema können das Hinzufügen oder Löschen neuer Beziehungen, Entitäten oder Attribute umfassen, ohne dass bestehende externe Schemata geändert oder Anwendungsprogramme neu geschrieben werden müssen.
Welche Arten von Datenbanken gibt es?
Es gibt zahlreiche verfügbare Datenbankkategorien, von einfachen Flat Files, die nicht relational sind, bis hin zu SQL (NoSQL) und neueren Graphdatenbanken, die als noch relationaler als standardmäßige relationale Datenbanken gelten. Einige Datenbanktypen sind:
Flat-File-Datenbank
Diese Datenbanken bestehen aus einer einzelnen Datentabelle ohne jegliche Beziehung – in der Regel Textdateien. Bei dieser Art von Datei können Benutzer Datenattribute wie Spalten und Datentypen angeben.

NoSQL-Datenbank
Diese Art von Datenbank ist eine Alternative, die sich besonders für große, verteilte Datensätze eignet. NoSQL-Datenbanken unterstützen eine Vielzahl von Datenmodellen, darunter Schlüssel-Wert-, Dokumenten-, Spalten- und Diagrammformate.
Graphdatenbank
Diese NoSQL-Datenbank geht über herkömmliche spalten- und zeilenorientierte relationale Datenmodelle hinaus und verwendet Knoten und Kanten, die Verbindungen zwischen Datenbeziehungen darstellen und neue Beziehungen zwischen den Daten erkennen können. Graphdatenbanken sind komplexer als relationale Datenbanken. Sie werden zur Betrugserkennung oder für Webempfehlungsmaschinen verwendet.

Objektrelationale Datenbank
Eine objektrelationale Datenbank (ORD) besteht sowohl aus einem RDBMS als auch aus einem objektorientierten Datenbankmanagementsystem (OODBMS). Sie enthält Merkmale sowohl des RDBMS- als auch des OODBMS-Modells. Eine herkömmliche Datenbank wird zur Speicherung der Daten verwendet. Der Zugriff und die Bearbeitung erfolgen dann über Abfragen, die in einer Abfragesprache wie SQL geschrieben sind. Daher basiert der grundlegende Ansatz einer ORD auf einer relationalen Datenbank.
Ein ORD kann jedoch auch als Objektspeicher betrachtet werden, insbesondere für Software, die in der objektorientierten Programmiersprache geschrieben wurde, und greift somit auf objektorientierte Merkmale zurück. In diesem Fall werden APIs für die Speicherung und den Abruf von Daten verwendet.
Verteilt
Eine verteilte Datenbank ist eine Art Datenbank, die Datensätze oder Dateien an mehreren verschiedenen physischen Speicherorten speichert. Die Datenverarbeitung ist ebenfalls verteilt und wird in verschiedenen Teilen des Netzwerks repliziert.
Cloud
Cloud-Datenbanken werden in einer öffentlichen, privaten oder hybriden Cloud für eine virtualisierte Umgebung erstellt. Cloud-Datenbanken bieten eine hohe Skalierbarkeit und Verfügbarkeit auf Abruf. Die Abrechnung für die Benutzer erfolgt auf der Grundlage der von ihnen genutzten Speicherkapazität und Bandbreite. Diese Datenbanken, einschließlich relationaler Datenbanken, können auch als Service angeboten werden. Das As-a-Service-Angebot wird als Database as a Service (DBaaS) bezeichnet.
Multi-Modell
Eine Multi-Modell-Datenbank ist eine Art von Datenbank, die mehrere Datenmodelle unterstützt. Durch Multi-Modell können IT-Teams verschiedene Anwendungsanforderungen erfüllen, ohne unterschiedliche Datenbanksysteme einsetzen zu müssen.
Selbststeuernd
Eine selbststeuernde oder autonome Datenbank ist eine Art von Datenbank, die regelmäßige Datenverwaltungsaufgaben automatisiert, einschließlich Backups, Updates, Tuning und Sicherheit. Diese Datenbanken sind Cloud-basiert und nutzen maschinelle Lernprozesse bei ihrer Automatisierung.
Was sind die Vorteile relationaler Datenbanken?
Zu den wichtigsten Vorteilen relationaler Datenbanken gehören:
- Daten kategorisieren. Datenbankadministratoren können Daten in einer relationalen Datenbank einfach kategorisieren und speichern, die dann abgefragt und gefiltert werden können, um Informationen für Berichte zu extrahieren. Relationale Datenbanken lassen sich außerdem leicht erweitern und sind nicht auf eine physische Organisation angewiesen. Nach der ursprünglichen Erstellung der Datenbank kann eine neue Datenkategorie hinzugefügt werden, ohne dass die vorhandenen Anwendungen geändert werden müssen.
- Genauigkeit. Daten werden nur einmal gespeichert, wodurch die Datendeduplizierung bei Speicherverfahren entfällt.
- Benutzerfreundlichkeit. Komplexe Abfragen können von Benutzern mit SQL, der wichtigsten Abfragesprache für relationale Datenbanken, einfach ausgeführt werden.
- Zusammenarbeit. Mehrere Benutzer können auf dieselbe Datenbank zugreifen.
- Sicherheit. Der direkte Zugriff auf Daten in Tabellen innerhalb eines RDBMS kann auf bestimmte Benutzer beschränkt werden.
- ACID/AKID. Relationale Datenbanken unterstützen AKID – Atomizität, Konsistenz, Isolation und Dauerhaftigkeit.
- Gespeicherte Prozeduren. Relationale Datenbanken unterstützen auch gespeicherte Prozeduren, wodurch sichergestellt wird, dass bestimmte Datenfunktionen detailliert implementiert werden.
- Redundanz. Normalisierung und gespeicherte Prozeduren tragen dazu bei, Redundanz zu reduzieren. Ebenso stellen Primärschlüssel sicher, dass keine doppelten Zeilen vorhanden sind.
Was sind die Nachteile relationaler Datenbanken?
Zu den Nachteilen relationaler Datenbanken gehören die folgenden:
- Struktur. Relationale Datenbanken erfordern viel Struktur und ein gewisses Maß an Planung, da Spalten definiert werden müssen und Daten korrekt in relativ starre Kategorien passen müssen. Die Struktur ist in manchen Situationen gut, führt aber zu Problemen im Zusammenhang mit den anderen Nachteilen, wie Wartung und mangelnde Flexibilität und Skalierbarkeit.
- Wartungsprobleme. Entwickler und andere für die Datenbank verantwortliche Mitarbeiter müssen Zeit für die Verwaltung und Optimierung der Datenbank aufwenden, wenn Daten hinzugefügt werden.
- Mangelnde Flexibilität. Relationale Datenbanken sind nicht ideal für die Verarbeitung großer Mengen unstrukturierter Daten. Daten, die größtenteils qualitativ, nicht leicht zu definieren oder dynamisch sind, sind für relationale Datenbanken nicht optimal. Wenn sich die Daten ändern oder weiterentwickeln, muss sich das Schema mitentwickeln, was Zeit in Anspruch nimmt.
- Mangelnde Skalierbarkeit: Relationale Datenbanken lassen sich nicht gut horizontal über physische Speicherstrukturen mit mehreren Servern skalieren. Es ist schwierig, relationale Datenbanken über mehrere Server hinweg zu verwalten, da die Struktur gestört wird, wenn ein Datensatz größer und verteilter wird, und die Verwendung mehrerer Server Auswirkungen auf die Leistung – wie zum Beispiel die Reaktionszeiten der Anwendungen – und die Verfügbarkeit hat.
- Leistung im Laufe der Zeit. Komplexe relationale Datenbanken enthalten viele verschiedene Tabellen. Mit der Zeit und zunehmender Datenmenge kann die Leistung nachlassen und die Reaktionszeiten bei Abfragen können sich verlangsamen.
Beispiele für relationale Datenbanken
Standardmäßige relationale Datenbanken ermöglichen es Benutzern, vordefinierte Datenbeziehungen über mehrere Datenbanken hinweg zu verwalten. Zu den gängigen Beispielen für standardmäßige relationale Datenbanken gehören Microsoft SQL Server, Oracle Database, MySQL und IBM DB2.
Cloud-basierte relationale Datenbanken sind ebenfalls weit verbreitet, da sie es Unternehmen ermöglichen, die Anforderungen an die Datenbankwartung, das Patchen und den Infrastruktur-Support auszulagern. Zu den relationalen Cloud-Datenbanken gehören Amazon Relational Database Service (RDS), Google Cloud SQL, IBM DB2 on Cloud, SQL Azure und Oracle Cloud.
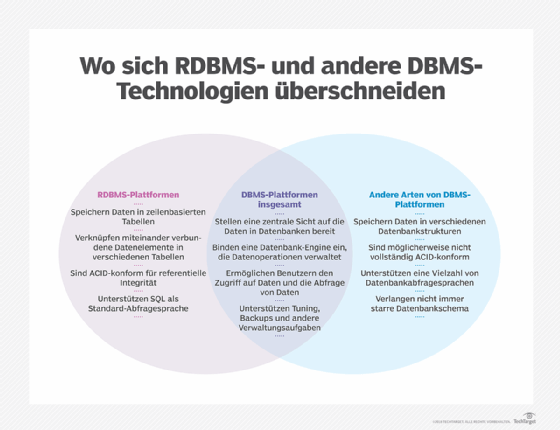
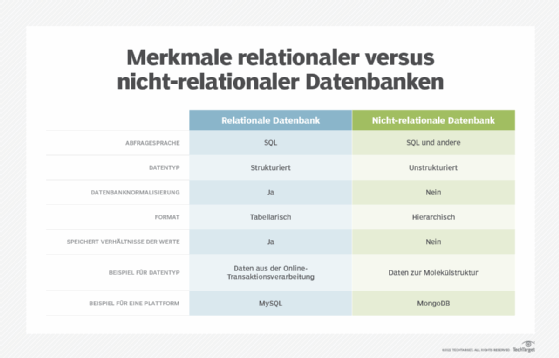
Was sind die Unterschiede zwischen relationalen Datenbanken, nicht-relationalen Datenbanken und NoSQL?
Der wichtigste Unterschied zwischen relationalen Datenbanksystemen und nicht-relationalen Datenbanksystemen besteht darin, dass relationale Datenbanken normalisiert sind. Das heißt, sie speichern Daten in tabellarischer Form, die in einer Tabelle mit Zeilen und Spalten angeordnet sind. Eine nicht-relationale Datenbank speichert Daten als Dateien.
Weitere Unterschiede sind:
- Verwendung von Primärschlüsseln. Relationale Datenbanktabellen haben jeweils einen Primärschlüssel-Identifikator. In einer nicht relationalen Datenbank werden Daten normalerweise in hierarchischer oder navigatorischer Form ohne Verwendung von Primärschlüsseln gespeichert.
- Datenwertbeziehungen. Da Daten in einer relationalen Datenbank in Tabellen gespeichert werden, wird auch die Beziehung zwischen diesen Datenwerten gespeichert. Da eine nicht relationale Datenbank Daten als Dateien speichert, gibt es keine Beziehung zwischen den Datenwerten.
- Integritätsbeschränkungen. In einer relationalen Datenbank sind Integritätsbeschränkungen alle Beschränkungen, die die Datenbankintegrität sicherstellen. Sie werden für den Zweck von ACID definiert. Nicht-relationale Datenbanken verwenden keine Integritätsbeschränkungen.
- Strukturierte versus unstrukturierte Daten. Relationale Datenbanken eignen sich gut für strukturierte Daten, die einem vordefinierten Datenmodell entsprechen und sich nicht wesentlich ändern. Nicht-relationale Datenbanken eignen sich besser für unstrukturierte Daten, die keinem vordefinierten Datenmodell entsprechen und nicht in einem RDBMS gespeichert werden können. Beispiele für unstrukturierte Daten sind Text, E-Mails, Fotos, Videos und Webseiten.
Nicht-relationale Datenbanken werden auch als NoSQL-Datenbanken bezeichnet. Die Begriffe werden synonym verwendet, es gibt jedoch Unterschiede.
SQL ist die Abfragesprache, die mit relationalen Datenbanken verwendet wird. Relationale Datenbanken und ihre Managementsysteme verwenden fast immer SQL als zugrunde liegende Abfragesprache. NoSQL-Datenbanken (oder nicht nur SQL) verwenden SQL und andere Abfragesprachen. Beispielsweise verwendet das NoSQL-Datenbankmanagementprogramm MongoDB JSON-ähnliche Dokumente zum Speichern und Organisieren von Daten. (Technisch gesehen wird eine Variante von JSON namens BSON oder binäres JSON verwendet.)
Die Kategorisierung von Datenbanken als nicht-relational oder relational basiert auf ihrer Architektur. Die Kategorisierung als SQL oder NoSQL basiert auf der Abfragesprache, ob es sich ausschließlich um SQL oder not only SQL handelt. Oft kann eine relationale Datenbank als SQL-Datenbank bezeichnet werden, da viele von ihnen SQL verwenden, und nicht-relationale Datenbanken können als NoSQL-Datenbanken bezeichnet werden. NoSQL- und nicht-relationale Datenbanken eignen sich gut für flexiblere Datenmodelle, wie zum Beispiel in der Konstruktion von Bauteilen und der Molekülmodellierung, wo sich Daten ständig ändern.
Sowohl relationale als auch nicht-relationale Datenbankplattformen haben ihre Nachteile. NewSQL-Datenbanken versuchen, die Vorteile beider Typen zu bieten, indem sie die Datenintegrität und Anwendungszugriffskontrolle, die relationale Datenbanken bieten, und die horizontale Skalierbarkeit, die nicht-relationale oder NoSQL-Plattformen bieten, zur Verfügung stellen.
Auswahl der richtigen Datenbank
Relationale Datenbanken eignen sich für strukturierte Daten mit definierten Beziehungen, die in einem Tabellenformat organisiert werden können. Bei der Auswahl der richtigen Datenbankarchitektur geht es jedoch um weit mehr als nur um die Wahl zwischen relationalen und nicht-relationalen Datenbanken. Die Art der verwendeten oder entwickelten Daten und Anwendungen sind entscheidende Faktoren, die es zu berücksichtigen gilt.
Zu den weiteren zu berücksichtigenden Faktoren gehören die Datenmenge, die Anzahl der Benutzer, die gleichzeitig Zugriff benötigen, die bevorzugte Programmiersprache, die geografische Verteilung der Daten, das Budget, die Integrationsanforderungen, die Verfügbarkeitsanforderungen und die Skalierungsanforderungen.






