
diajengwd - stock.adobe.com
Netzwerke mit VXLAN und EVPN planen: Die Netzwerkarchitektur
Klassische Dreischicht-Architekturen mit VLANs und Spanning Tree stoßen an Skalierungsgrenzen. EVPN/VXLAN ermöglicht flexible, hochverfügbare Netzwerke auch für Campusumgebungen.

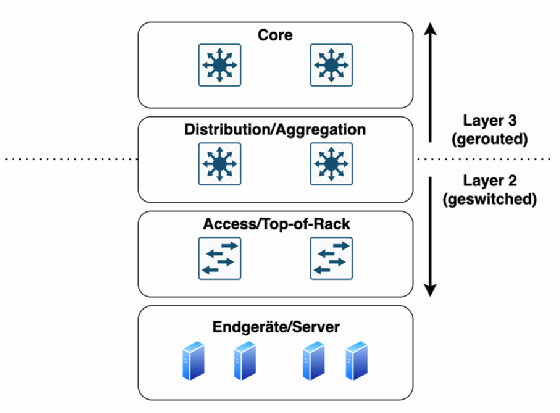
Netzwerkplaner stehen häufig vor der Herausforderung, skalierbare, flexible, automatisierbare, sichere und hochverfügbare Netzwerkarchitekturen zu entwerfen, die die benötigte Performance liefern. Dabei stoßen klassische Netzwerkarchitekturen mit hierarchischen Dreischicht-Konzepten und Core-, Distribution- sowie Access-Ebenen allerdings an ihre Grenzen.
Immer mehr Unternehmen und Behörden denken deshalb über eine Migration zu EVPN/VXLAN-Architekturen nach. Diese stammen ursprünglich aus dem Rechenzentrumsumfeld, doch immer mehr Hersteller stellen die Funktionalitäten auch für Campusnetze bereit, da sie auch dort ihre Vorteile ausspielen können. Diese Artikelserie beschreibt die Beschränkungen klassischer Architekturen, Lösungsansätze sowie die Grundlagen von VXLAN und EVPN und enthält Implementierungsbeispiele.
Die Grenzen von VLAN
Klassischerweise wird die Netzwerksicherheit durch VLAN-Segmentierung zur Verkleinerung der Broadcast-Domänen sowie durch Firewalls und Zugriffskontrolllisten (ACL) erreicht. Die Terminierung der VLANs erfolgt in der Dreischicht-Architektur auf der Distributions-/Aggregationsebene. Routing-Redundanz wird über sogenannte First-Hop-Redundanz-Protokolle wie VRRP oder HSRP abgewickelt. In redundanten Architekturen wird dadurch jedoch nur eine von mehreren Komponenten aktiv genutzt, was eine suboptimale Ressourcennutzung darstellt. Mit maximal 4094 VLAN-IDs skalieren VLANs jedoch nur begrenzt. Zur Sicherstellung der Schleifenfreiheit auf Layer 2 des OSI-Modells sind zusätzliche Protokolle wie Spanning Tree (IEEE 802.1D), Rapid Spanning Tree (IEEE 802.1w) oder Multiple Spanning Tree (IEEE 802.1s) erforderlich. Diese sorgen zwar für Schleifenfreiheit, blockieren jedoch redundante Pfade und erlauben somit nur einen aktiven Pfad. Dies geht zulasten der verfügbaren Bandbreite. Zudem ist die Anzahl der unterstützten Spanning-Tree-Instanzen auf manchen Switches limitiert, was die Skalierbarkeit wiederum einschränkt. Des Weiteren führen Anpassungen im Spanning Tree zu vergleichsweise hohen Konvergenzzeiten mit MAC-Tabellen-Clearings, also dem kompletten Neu-Erlernen von MAC-Adressen.
Layer-2-Schleifen führen zu sogenannten Broadcast-Stürmen, bei denen sich die Frames unendlich vermehren und an alle Endgeräte im jeweiligen VLAN gesendet werden. Dies kann zur Überlastung der Switches und Endgeräte führen. Ethernet bietet auch keine Möglichkeit, Pakete nach einer gewissen Anzahl an Weiterleitungen (Hop-Count) zu verwerfen, wie es bei IP-Paketen auf Layer 3 durch die Time to Live (TTL) gegeben ist.
Ein möglicher Ausweg wäre eine durchgehend geroutete Netzwerkarchitektur. Dabei bleibt ein VLAN jeweils lokal auf einem Switch, beispielsweise einem Access-Switch im Campusnetz (sogenannter Routed Access) oder einem Top-of-Rack-Switch im Rechenzentrum. Bereits auf deren Uplinks in Richtung Distribution/Aggregation beginnt das Routing. Dies ermöglicht Redundanz und Lastverteilung über mehrere Layer-3-Pfade auf den Uplinks. Layer-2-Schleifen können auf diesen Transit-Links nicht entstehen.
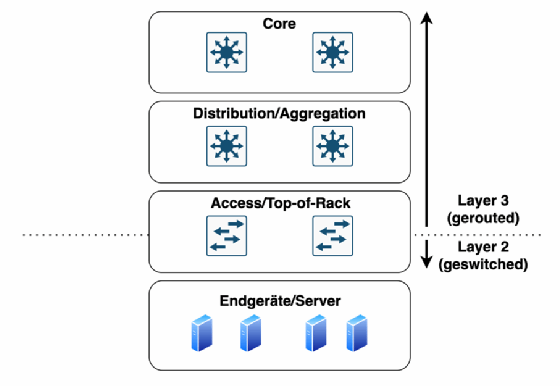
In Rechenzentrumsumgebungen ist dieses Vorgehen jedoch problematisch. Viele Anwendungen setzen auch heute noch für Redundanzzwecke auf Layer-2-Konnektivität. Hinzu kommen Anforderungen aus der Servervirtualisierung. Funktionen wie Broadcom/VMware vMotion oder Disaster Recovery über Standortgrenzen hinweg erfordern Layer-2-Transparenz. In klassischen Routing-Szenarien wären solche Workloads ohne IP-Re-Adressierung nicht zwischen Racks verschiebbar. In typischen Netzwerken für Endnutzer in Campusumgebungen ist das durch die dynamische Adressvergabe per DHCP meist unkritisch. Im Rechenzentrum ist dies jedoch nicht akzeptabel.
VXLAN als Lösungsansatz
Als Lösungsansatz kann das Overlay-Protokoll VXLAN (Virtual Extensible LAN) dienen. VXLAN kann Layer-2-Domänen innerhalb eines VXLAN-Tunnels über ein Layer-3-Netz (Underlay) hinweg erweitern. VXLAN wurde in RFC 7348 mit Beiträgen von großen Herstellern wie Cisco, Arista, VMware, Red Hat, Broadcom und Intel definiert.
VXLAN kapselt Ethernet-Frames in UDP-Segmente (Port 4789) und ermöglicht so die Kommunikation zwischen Hosts innerhalb desselben VXLAN-Segments. Darunter versteht man eine logische Layer-2-Domäne über Layer-3-Grenzen im Underlay hinweg. Durch den 24-Bit-VXLAN-Network-Identifier (VNI) lassen sich bis zu 16 Millionen logische Netzwerke abbilden, also weit mehr als die 4094 VLANs des IEEE-802.1Q-Standards. Diese enorme Skalierbarkeit ist vor allem für Multi-Tenant-Umgebungen von Bedeutung, etwa bei Hosting-Providern.

Das auf IP/UDP basierende Overlay erlaubt zusätzlich den Einsatz von Equal-Cost Multipath (ECMP). So lassen sich alle verfügbaren Links des Underlays optimal ausnutzen und Lasten gleichmäßig auf die Pfade des zugrunde liegenden Routing-Protokolls im Underlay verteilen.
Die Endpunkte eines VXLAN-Tunnels werden als VXLAN Tunnel Endpoints (VTEP) bezeichnet. Sie kapseln und entkapseln die Datenpakete und führen die Zuordnung von VLANs zu VNIs durch. VTEPs können physische Netzwerkgeräte (Router, Switches) oder virtuelle Komponenten, wie virtuelle Switches im Hypervisor, sein. Die Endgeräte selbst benötigen keinerlei Anpassung und erkennen im Normalfall keinen Unterschied zur klassischen Layer-2-Verbindung. Wichtig ist lediglich, dass die VTEPs im Underlay IP-seitig erreichbar sind. Dabei sollte die MTU auf den Transit-Links zwischen den VTEPs für IPv4 50 Byte und für IPv6 70 Byte höher sein als im Overlay benötigt. Dies ergibt sich aus
8 Byte (VXLAN) + 8 Byte (UDP) + 20 Byte (IPv4) + 14 Byte (Ethernet) = 50 Byte für IPv4
beziehungsweise aus
8 Byte (VXLAN) + 8 Byte (UDP) + 40 Byte (IPv4) + 14 Byte (Ethernet) = 70 Byte für IPv6.
Je nach VXLAN-Implementierung kann auch Multicast-Unterstützung erforderlich sein. Bei der Auswahl der Switches sollte darauf geachtet werden, dass diese keine Re-Zirkulation, also multiple Routing-Abfragen im Overlay und Underlay, benötigen, da dies die Latenz erhöhen würde.
Leaf-Spine-Architektur
Im Gegensatz zu klassischen Netzwerken nutzen physische VXLAN-Infrastrukturen meist sogenannte Leaf-Spine-Architekturen. Leaf-Spine-Architekturen haben sich als moderne und effiziente Netzwerktopologie etabliert und kommen besonders in Rechenzentren und großen Unternehmensnetzwerken zum Einsatz. Diese Architektur basiert auf dem Prinzip der CLOS-Topologie, die ursprünglich vom amerikanischen Ingenieur Charles Clos bei Bell Labs für Telefonvermittlungsstellen entwickelt wurde. Sie bietet eine skalierbare, verfügbare, deterministische und latenzarme Lösung für die Anforderungen der modernen Datenübertragung.
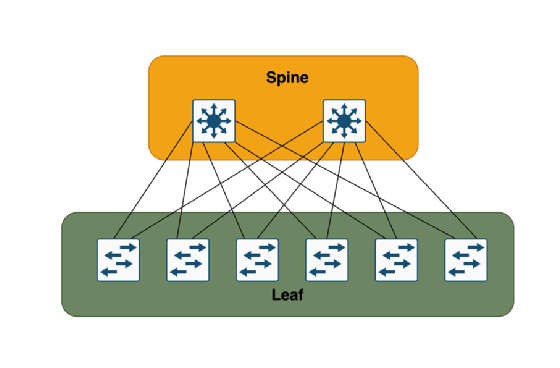
Die Leaf-Spine-Architektur besteht aus zwei Hauptkomponenten: Leaf-Switches und Spine-Switches. Die Leaf-Switches bilden die unterste Ebene der Architektur. Sie sind direkt mit den Endgeräten verbunden. Dazu zählen Server, Speichersysteme und andere Netzwerkgeräte. Jeder Leaf-Switch ist mit jedem Spine-Switch verbunden. Dadurch entsteht eine voll vermaschte Topologie. Im Normalfall sind Leafs nicht direkt physisch mit anderen Leafs verbunden. Diese Struktur ermöglicht eine effiziente und redundante Datenübertragung, was besonders im Zusammenhang mit EVPN und VXLAN von Vorteil ist. Somit gibt es keine Single Points of Failure, sodass auch Update-Prozesse oder Hardware- oder Softwarefehler einzelner Komponenten nicht zu einem Ausfall der Fabric führen.
Die Spine-Switches bilden die oberste Ebene der Architektur und sind für die Verbindung der Leaf-Switches untereinander verantwortlich. Sie stellen sicher, dass Datenpakete mit immer genau einem Zwischen-Hop, dem Spine-Switch, effizient zwischen den Leaf-Switches weitergeleitet werden können. Dies bildet die Grundlage für eine deterministische, latenzarme und skalierbare Netzwerkinfrastruktur.
Ein wesentlicher Vorteil der Leaf-Spine-Architektur im Kontext von EVPN/VXLAN ist ihre Skalierbarkeit. Durch das Hinzufügen weiterer Leaf- und Spine-Switches kann das Netzwerk einfach erweitert werden. Falls mehr Bandbreite benötigt wird, lassen sich weitere Spine-Switches hinzufügen. Wenn mehr Ports für Server oder Endgeräte erforderlich sind, können weitere Leaf-Switches hinzugefügt werden.
Aufgrund der klaren Funktionstrennung und der hierarchischen Struktur in der Leaf-Spine-Architektur lassen sich Änderungen, Erweiterungen oder potenzielle Fehlerbehebungen beschleunigen. Zudem vereinfacht diese Struktur die Nutzung von Automatisierungstools wie Ansible für das Konfigurationsmanagement.




