SPoF (Single Point of Failure)

Ein Single Point of Failure (SPOF) ist ein potenzielles Risiko, das durch einen Fehler in der Konstruktion, Implementierung oder Konfiguration einer Schaltung oder eines Systems entsteht. SPOF bezieht sich auf einen Fehler oder eine Fehlfunktion, die dazu führen kann, dass ein gesamtes System den Betrieb einstellt.
SPOFs in einem Rechenzentrum oder einer anderen IT-Umgebung können die Verfügbarkeit von Workloads oder des gesamten Rechenzentrums beeinträchtigen, je nach Standort und Abhängigkeiten, die mit dem Ausfall verbunden sind.
Beispiele für Single Points of Failure
Hier sind zwei Beispiele dafür, wie sich ein SPOF manifestieren kann:
- Ein einzelner Server. Stellen Sie sich ein Rechenzentrum vor, in dem ein Server allein eine Anwendung ausführt. Die zugrunde liegende Serverhardware würde in diesem Szenario einen Single Point of Failure für diese Anwendung darstellen: Fällt sie aus, dann stürzt die Anwendung ab. Die Folge wären Tickets verärgerter Nutzer und Datenverlust.
Mit Server-Clustern können sie die Wahrscheinlichkeit reduzieren, dass das passiert. Indem Sie die Anwendung auf einen zweiten, dritten und vierten Server verteilen und kopieren, schaffen Sie zusätzliche Versionen, auf die Sie im Ernstfall ausweichen können.
- Ein einsamer Netzwerk-Switch. Ein weiteres Beispiel wäre ein Server-Array, in dem nur ein einziger Switch installiert ist. Fällt er aus, oder wird vom Stromnetz getrennt, sind alle mit diesem Switch verbundenen Server für den Rest des Netzwerks nicht mehr erreichbar. Hier ist der Switch ein Single Point of Failure. Bei einem großen Switch könnte dies Dutzende von Servern und deren Workloads betreffen. Redundante Switches und Netzwerkverbindungen stellen alternative Netzwerkpfade für miteinander verbundene Server her, falls der ursprüngliche Switch ausfallen sollte, so dass es keinen SPOF mehr gibt
Identifizierung von Single Points of Failure
Viele der potenziellen SPOFs existieren im Rechenzentrum ohne Wissen der Administratoren. Nahezu jede einzelne Komponente in einem Rechenzentrum kann zum Point of Failure werden, oft weil nur ein Primärsystem im Einsatz ist. Zu diesen Komponenten gehören Server, Speicher, Stromversorgungsgeräte und Infrastrukturmanagementsysteme.
Klassische SPOFS finden Sie überall da, wo es ein System nur ein einziges Mal gibt, das spezifisch für eine Aufgabe zuständig ist. Der Verlust eines solchen Systems, insbesondere eines nicht fehlertoleranten Systems, kann den Rechenzentrums- oder den gesamten Betrieb eines Unternehmens stören.
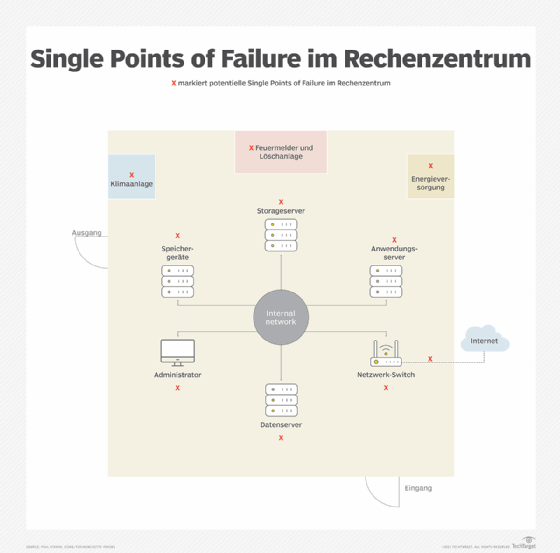
Nicht alle SPOFs liegen auf der Hand. Die folgenden Tipps können Ihnen helfen, sie zu finden:
- Erstellen und analysieren Sie eine Karte des Rechenzentrums, auf der alle Komponenten und deren Standorte aufgeführt sind.
- Gehen Sie physisch mit einer Taschenlampe durch das Rechenzentrum und entfernen Sie Bodenfliesen und andere Platten, die Geräte und Kabel abdecken.
- Sehen Sie sich die Netzwerkdiagramme des Rechenzentrums und anderer Gebäudeteile an.
- Untersuchen Sie externe Kabel – beispielsweise für Netzteile und Kommunikation.
- Stellen Sie sicher, dass die technischen Diagramme selbst auf dem neuesten Stand sind; sie können auch ein Single Point of Failure werden.
Single Points of Failure vermeiden
Es liegt in der Verantwortung des Rechenzentrumsarchitekten, Fehlerquellen, die im Design der Infrastruktur auftreten, zu identifizieren und zu beheben. Ausfallsicherheit hat jedoch ihren Preis – zum Beispiel Ausgaben für zusätzliche Server innerhalb eines Clusters und zusätzlicher Switches, Netzwerkschnittstellen und Verkabelung. Sie sollten also sorgfältig, Workload für Workload, abwägen, wann die Kosten bei einem Ausfall höher sind als die Kosten für eine redundante Architektur. Hier kann eine Risikomanagementstrategie bei der Entscheidungsfindung helfen.

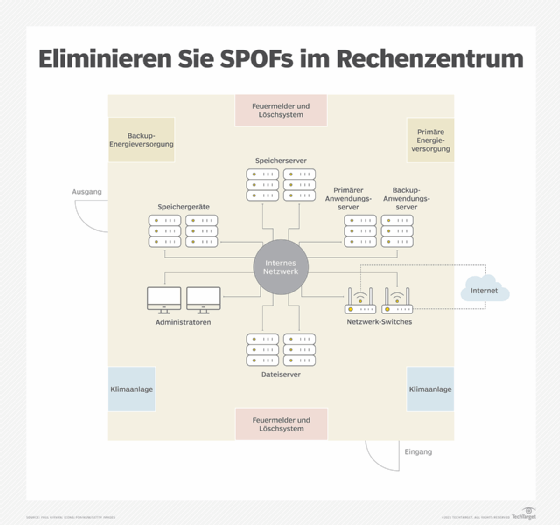
Sie können SPOFs entweder komplett eliminieren, oder aber nur die Wahrscheinlichkeit senken, dass der Ernstfall eintritt. Dafür haben Sie verschiedene Methoden zur Wahl:
- Backups und redundante Systeme und Softwarekomponenten sichern den Verlust eines Primärsystems.
- Ein zweiter Kanal oder Kanal für redundante Netzwerkverkabelung schützt vor Verbindungsverlusten zu lokalen Netzbetreibern und Internetdienstanbietern.
- Load Balancer senden Anfragen nur an Server, die online sind und verwendet werden. Infolgedessen sind sie gut geeignet, um den Verkehr auf Ausweichserver umzuleiten, wenn es zu einem Ausfall kommt.
- Notstromsysteme schützen vor Stromausfällen. Blitzableiter und elektrische Erdung reduzieren die Gefahr von Überspannungen.
- Eine moderne Datensicherheitsinfrastruktur mindert die Bedrohung durch Cyber-Angriffe. Dazu gehören Firewalls die Sie mit Datenbanken und Patches laufend aktuell halten.
- Menschen können auch zu SPOFs werden. Wenn nur ein einziger Mitarbeiter in bestimmtes System verwenden oder warten kann, ist das für Ihren Betrieb ein großes Risiko. Sorgen Sie dafür, dass es immer mehrere Mitarbeiter gibt, die für ihn einspringen, auch, wenn sie normalerweise andere Aufgaben ausführen.