
hakinmhan - stock.adobe.com
Der Unterschied zwischen Datenbereinigung und -transformation
Datenbereinigung korrigiert Fehler, um die Datenqualität zu verbessern, wogegen die Datentransformation Datenformat und -struktur ändert, um Analyseprozesse zu unterstützen.

Daten sind der Motor moderner Unternehmen, aber die damit verbundenen Begriffe sind vielfältig und oft verwirrend. Von der Datenaufbereitung und -bereinigung bis hin zur Datenaggregation und darüber hinaus – die vielfältigen Techniken und deren Vokabular können wie ein Buch mit sieben Siegeln erscheinen.
Viele dieser Prozesse sind jedoch für die Aufrechterhaltung der Datenqualität und die Förderung von Data Science und Analytics von entscheidender Bedeutung. Datenbereinigung und -transformation sind zwei der wichtigsten – und am häufigsten missverstandenen – Prozesse.
Das Verständnis der Unterschiede zwischen Datenbereinigung und Datentransformation sowie ihrer jeweiligen Verwendung ist für eine effektive Datenverwaltung und die Gewinnung zuverlässiger Erkenntnisse von entscheidender Bedeutung.
Was ist Datenbereinigung?
Datenbereinigung ist der Prozess der Identifizierung und Korrektur von Fehlern in einem Datensatz. Er beginnt mit der Bewertung der Datenqualität und der Kennzeichnung von falschen, inkonsistenten oder unvollständigen Informationen innerhalb eines Datensatzes. Der nächste Schritt umfasst die Korrektur dieser Fehler, um sicherzustellen, dass alle Daten korrekt und zuverlässig sind.
Das primäre Ziel der Datenbereinigung ist die Verbesserung der Datenqualität. Dies ist für das Datenmanagement von entscheidender Bedeutung, da ungenaue Daten zu ungenauen Erkenntnissen und damit zu fehlerhaften Entscheidungen führen können. Hochwertige Daten hingegen ermöglichen es Datenwissenschaftlern, Analysten und Geschäftsanwendern, fundiertere, datengestützte Entscheidungen zu treffen, die sich positiv auf das Geschäftsergebnis auswirken.
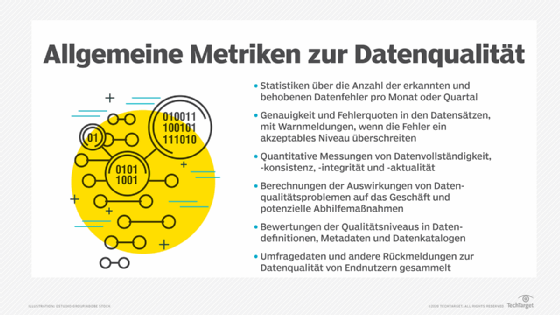
Die Datenbereinigung konzentriert sich auf die Verbesserung der folgenden Dimensionen der Datenqualität:
- Genauigkeit, das heißt wie gut die Daten das beschriebene Attribut widerspiegeln.
- Vollständigkeit, das heißt der Prozentsatz der Daten, die in einem Datensatz fehlen.
- Konsistenz, das heißt die Einheitlichkeit der Daten über Systeme und Quellen hinweg.
- Integrität, das heißt die Gültigkeit von Beziehungen zwischen verschiedenen Datenentitäten.
- Eindeutigkeit, das heißt das Fehlen doppelter oder redundanter Daten.
- Gültigkeit, das heißt der Prozentsatz der Daten, die der definierten Syntax entsprechen.
Obwohl Datenbereinigung auch die Verbesserung anderer Attribute umfassen kann, besteht ihr Hauptzweck darin, Fehler zu beheben und Daten für die Verwendung vorzubereiten.
Was ist Datentransformation?
Datentransformation ist der Prozess der Konvertierung von Daten aus einem Format in ein anderes. Beispielsweise müssen Rohdaten in ein für Datenbanken und Anwendungen lesbares Format konvertiert werden. Die Datentransformation erleichtert diese Konvertierung.
Wie die Datenbereinigung ist auch die Datentransformation oft Teil der Datenaufbereitung und anderer Datenmanagementprozesse, einschließlich Datenintegration und -migration. Dieser Prozess ist notwendig, da Unternehmen Informationen in vielen Formaten aus unterschiedlichen Datenquellen sammeln. Damit diese Daten effektiv gespeichert und analysiert werden können, müssen sie strukturiert und organisiert sein. Die Datentransformation vereinheitlicht Datentypen in konsistente Formate und macht Informationen verwertbar und zugänglich.
Datentransformation spielt auch eine Rolle bei der Verbesserung der Datenqualität. Die Konvertierung von Daten in einheitliche, zuverlässige Formate unterstützt einen breiteren Zugang und ermöglicht eine schnellere und genauere Datenanalyse.
Transformationsprozess
Datentransformation ist die ausführende Phase des Integrationsprozesses Extrahieren, Transformieren und Laden (ETL) oder Extrahieren, Laden und Transformieren (ELT). Obwohl sich ETL und ELT in der Reihenfolge der Vorgänge unterscheiden, umfassen beide Prozesse drei wichtige Phasen:
- Extraktion: Relevante Daten werden aus verschiedenen Quellen gesammelt, häufig durch Profiling und Mapping.
- Transformation: Die aggregierten Daten werden mithilfe von Techniken wie Datennormalisierung, Anreicherung und Bereinigung in die gewünschte Struktur konvertiert.
- Laden: Die transformierten Daten werden zur Verarbeitung und Analyse in eine Datenbank geladen.
Die Wahl zwischen ETL und ELT hängt weitgehend davon ab, wie, wann und wo die Transformation stattfinden soll.
Transformationstechniken
Für die Datentransformation können verschiedene Techniken verwendet werden, die sich nach ihrer Funktion gruppieren lassen.
Zu den Techniken für die strukturelle Formatierung und Integration gehören:
- Bei der Datenaggregation werden Daten aus verschiedenen Quellen gesammelt und in einer neuen Form zusammengefasst.
- Beim Daten-Mapping werden Datenfelder aus einer Quelle mit denen einer anderen Quelle verknüpft oder abgeglichen.
- Bei der Datenkodierung werden Daten in ein bestimmtes Format, in der Regel ein numerisches, konvertiert, um ihre Verarbeitung zu erleichtern.
- Die Datennormalisierung stellt sicher, dass Datenelemente dieselbe Skala oder dasselbe Format verwenden, um alle Daten über Felder hinweg konsistent darzustellen.
- Die Datenkategorisierung und -klassifizierung organisiert Daten in neue, relevantere Gruppen.
- Die Datenkombination und -integration führt Datenelemente zusammen, mischt sie und vereinheitlicht sie.
Zu den Techniken zur Verbesserung der Datenqualität gehören:
- Datendeduplizierung umfasst die Identifizierung und Eliminierung redundanter Datenkopien, um die Eindeutigkeit sicherzustellen.
- Datenrevision umfasst die Änderung oder Aktualisierung von Daten innerhalb eines Datensatzes, um die Genauigkeit und Konsistenz im Laufe der Zeit sicherzustellen.
- Data Scrubbing – ein Begriff, der oft synonym mit Datenbereinigung verwendet wird – ist der Prozess der Identifizierung und Korrektur von Fehlern in Daten.
- Bei der Datenimputation werden fehlende Daten durch neue, geschätzte Werte ersetzt.
Zu den Techniken zur analytischen Vorbereitung und Verbesserung gehören:
- Bei der Datenermittlung und -profilerstellung werden relevante Daten identifiziert, ihre Struktur und Eigenschaften interpretiert und festgelegt, wie sie transformiert werden sollen.
- Bei der Datendiskretisierung werden Daten in feinere oder detailliertere Elemente zerlegt, um sie leichter analysieren zu können.
- Bei der Datenfilterung werden die relevantesten Daten aus einem größeren Datensatz herausgefiltert und segmentiert.
- Bei der Datengeneralisierung werden detaillierte Datensätze in übergeordnete Kategorien abstrahiert, um sie verständlicher zu machen.
- Bei der Datentrennung und -aufteilung wird ein größerer Datensatz in zwei oder mehr Teilmengen aufgeteilt, häufig um Daten anhand einer Stichprobe zu testen.
- Bei der Datenglättung werden Störsignale oder Ausreißer aus einem Datensatz entfernt, um Muster und Trends leichter erkennen zu können.
- Bei der Datensupplementierung und -anreicherung werden relevante Informationen aus externen Quellen, wie beispielsweise Datensätzen von Drittanbietern, hinzugefügt, um einen umfassenderen Datensatz zu erstellen.
Nach der Transformation müssen die Daten validiert und überprüft werden, um sicherzustellen, dass sie den Anforderungen entsprechen und keine Anomalien oder Fehler enthalten.
Unterschiede zwischen Datenbereinigung und Datentransformation
Datenbereinigung und Datentransformation dienen unterschiedlichen Zwecken im Datenaufbereitungsprozess:
- Datenbereinigung konzentriert sich auf die Identifizierung, Korrektur und Beseitigung von Fehlern in Datensätzen.
- Datentransformation umfasst die Konvertierung von Daten in ein bestimmtes Format.
Daten werden häufig zu Beginn des Datentransformationsprozesses bereinigt, um sicherzustellen, dass der Datensatz korrekt und fehlerfrei ist. Die Datentransformation umfasst hingegen in der Regel ein breiteres Spektrum an Techniken. Das Ziel besteht darin, Daten so umzustrukturieren, dass sie leichter verarbeitet werden können, beispielsweise für Analysen, Berichte oder Interpretationen. Die Datentransformation kann zwar wie die Datenbereinigung die Behebung von Fehlern umfassen, beinhaltet jedoch auch die Ergänzung und Erweiterung bestehender Daten, um einen umfassenderen Datensatz zu erstellen.
Gängige Beispiele und Verwendungszwecke
Zu den Aufgaben der Datenbereinigung gehören das Erkennen von Inkonsistenzen in einem Datensatz, das automatische Beheben einfacher Fehler, das Entfernen ungültiger oder redundanter Daten und das Hervorheben fehlender Werte.
Beispiele für die Datenbereinigung sind unter anderem:
- Löschen doppelter Kundendaten in einer Tabelle
- Überprüfen, ob Daten dem richtigen Format entsprechen, zum Beispiel TT/MM/JJJJ
- Markieren von Telefonnummern, bei denen eine Ziffer fehlt
- Entfernen irrelevanter Daten, zum Beispiel HTML-Tags
- Korrektur grundlegender Rechtschreibfehler
Mit der Datentransformation können Daten zwischen verschiedenen Formaten konvertiert, Datensätze umstrukturiert oder kombiniert oder Daten für die weitere Verwendung verbessert werden. Beispiele für die Datentransformation sind unter anderem:
- Aggregieren von Finanzdaten, um Monatsdurchschnitte darzustellen.
- Glätten von Daten, um eine klare Trendlinie für Kundenkäufe zu erstellen.
- Aufteilung von Daten in einen Beispielsatz und einen Kontrollsatz für Experimente.
- Überarbeitung von Daten in Echtzeit, um den Bestand mit dem aktuellen Volumen zu aktualisieren.
- Verbesserung von Daten für die Verwendung in Trainingsmodellen für maschinelles Lernen.
Wann ist was geeignet?
Verwenden Sie Datenbereinigung, wenn das Ziel darin besteht, bestimmte Dimensionen der Datenqualität zu verbessern, zum Beispiel Genauigkeit, Konsistenz, Eindeutigkeit und Gültigkeit. Der Prozess dient dazu, Fehler zu erkennen und zu beheben, Redundanzen zu entfernen und ungenaue Informationen zu korrigieren.
Verwenden Sie Datentransformation, um die Verwendbarkeit der Daten zu verbessern. Dies kann die Änderung von Datenformaten, die Erweiterung von Datensätzen, die Zusammenfassung von Daten oder die Aufschlüsselung eines Datensatzes in detailliertere Informationen bedeuten. In der Regel handelt es sich hierbei um einen komplexeren Prozess als die Datenbereinigung, mit viel mehr Anwendungsfällen.
Obwohl es einige Überschneidungen gibt, werden Datenbereinigung und Deduplizierung im Allgemeinen als Teil des umfassenderen Datentransformationsprozesses betrachtet. Datentransformation kann eine Vielzahl zusätzlicher Techniken umfassen, während Datenbereinigung sich enger auf die Korrektur und Entfernung von Fehlern konzentriert. Beispielsweise kann die Datenbereinigung nur redundante Informationen entfernen, während die Datentransformation Einträge zu einem größeren Datensatz zusammenfassen kann, um mehr Kontext hinzuzufügen und die Daten anzureichern.







