Datenqualität
Was ist Datenqualität?
Die Datenqualität misst den Zustand eines Datensatzes anhand von Faktoren wie Genauigkeit, Vollständigkeit, Konsistenz, Aktualität, Eindeutigkeit und Gültigkeit. Die Messung der Datenqualität kann Unternehmen dabei unterstützen, Fehler und Inkonsistenzen in ihren Daten zu identifizieren und zu beurteilen, ob die Daten für den vorgesehenen Zweck geeignet sind.
Unternehmen legen zunehmend Wert auf Datenqualität, da sie erkannt haben, wie wichtig Daten für Geschäftsabläufe und fortschrittliche Analysen sind, die geschäftliche Entscheidungen beeinflussen. Das Datenqualitätsmanagement ist ein zentraler Bestandteil der gesamten Data-Governance-Strategie eines Unternehmens.
Data Governance stellt sicher, dass Daten ordnungsgemäß gespeichert, verwaltet, geschützt und unternehmensweit einheitlich verwendet werden.
Warum ist Datenqualität wichtig?
Daten von geringer Qualität können erhebliche geschäftliche Folgen für ein Unternehmen haben. Schlechte Daten sind oft die Ursache für operative Pannen, ungenaue Analysen und schlecht durchdachte Geschäftsstrategien. Sie können beispielsweise zu folgenden Problemen führen:
- Versand von Produkten an falsche Kundenadressen.
- Verpasste Verkaufschancen aufgrund fehlerhafter oder unvollständiger Kundendaten.
- Geldstrafen wegen unsachgemäßer Finanz- oder Compliance-Berichterstattung.
Laut dem Monte-Carlo-Bericht The Annual State of Data Quality Survey nehmen Datenqualitätsprobleme in vielen Unternehmen zu und ihre negativen Auswirkungen werden immer größer. Die durchschnittliche Anzahl der Datenqualitätsvorfälle pro Unternehmen stieg von 59 im Jahr 2022 auf 67 im Jahr 2023; die durchschnittliche Zeit für die Behebung von Datenqualitätsproblemen stieg von weniger als vier Stunden im Jahr 2022 auf mehr als vier Stunden; und der durchschnittliche Prozentsatz der betroffenen Einnahmen stieg von 26 Prozent im Jahr 2022 auf 31 Prozent.
Darüber hinaus stufen laut dem Bericht 2025 Outlook: Data Integrity Trends and Insights, der von der Drexel University in Zusammenarbeit mit dem Datenintegritätsanbieter Precisely veröffentlicht wurde, 64 Prozent der befragten Unternehmen die Qualität als das wichtigste Problem der Datenintegrität ein, und das Misstrauen gegenüber Daten als Entscheidungshilfe ist von 55 Prozent im Jahr 2023 auf 67 Prozent gestiegen.
Das mangelnde Vertrauen von Führungskräften und Geschäftsleitern in Daten wird häufig als eines der größten Hindernisse für den Einsatz von Business Intelligence (BI) und Analyse-Tools zur Verbesserung der Entscheidungsfindung in Unternehmen genannt. Gleichzeitig wachsen die Datenmengen mit atemberaubender Geschwindigkeit und die Daten sind vielfältiger denn je. Nie zuvor war es für ein Unternehmen so wichtig, eine effektive Strategie für das Datenqualitätsmanagement zu implementieren.
Was sind die sechs Elemente der Datenqualität?
Daten von geringer Qualität können zu Problemen bei der Transaktionsverarbeitung in operativen Systemen und zu fehlerhaften Ergebnissen in Analyseanwendungen führen. Solche Daten müssen identifiziert, dokumentiert und korrigiert werden, um sicherzustellen, dass Führungskräfte, Datenanalysten und andere Geschäftsanwender mit guten Informationen arbeiten. Hochwertige Daten sollten die folgenden sechs Merkmale aufweisen:
- Genauigkeit. Die Daten geben die Entitäten oder Ereignisse, die sie darstellen sollen, korrekt wieder und stammen aus überprüfbaren und vertrauenswürdigen Quellen.
- Vollständigkeit. Die Daten umfassen alle Werte und Datentypen, die sie enthalten sollen, einschließlich aller Metadaten, die zu den Datensätzen gehören.
- Konsistenz. Die Daten sind system- und datensatzübergreifend einheitlich, und es gibt keine Konflikte zwischen denselben Datenwerten in verschiedenen Systemen oder Datensätzen.
- Aktualität. Die Daten sind aktuell (im Hinblick auf ihre spezifischen Anforderungen) und stehen bei Bedarf zur Verfügung.
- Eindeutigkeit. Die Daten enthalten keine doppelten Datensätze innerhalb eines einzelnen Datensatzes, und jeder Datensatz kann eindeutig identifiziert werden.
- Gültigkeit. Die Daten entsprechen definierten Geschäftsregeln und Parametern, die sicherstellen, dass sie ordnungsgemäß strukturiert sind und die erforderlichen Werte enthalten.
Ein Datensatz, der alle diese Kriterien erfüllt, ist wesentlich zuverlässiger und vertrauenswürdiger als ein Datensatz, bei dem dies nicht der Fall ist. Dies sind jedoch nicht unbedingt die einzigen Standards, die Unternehmen zur Bewertung ihrer Datensätze heranziehen. Beispielsweise können sie auch Eigenschaften wie Angemessenheit, Glaubwürdigkeit, Relevanz, Zuverlässigkeit oder Verwendbarkeit berücksichtigen. Das Ziel besteht darin, über vertrauenswürdige Daten zu verfügen, die für den vorgesehenen Zweck geeignet sind.
Vorteile einer guten Datenqualität
Die Aufrechterhaltung einer guten Datenqualität führt zu einer Vielzahl positiver Ergebnisse, darunter die folgenden:
- Unternehmen können die Kosten senken, die mit der Identifizierung und Behebung fehlerhafter Daten verbunden sind, wenn ein datenbezogenes Problem auftritt. Die Aufrechterhaltung der Datenqualität trägt auch dazu bei, Betriebsfehler und Ausfälle von Geschäftsprozessen zu vermeiden, die zu höheren Betriebskosten und geringeren Einnahmen führen können.
- Die Genauigkeit von Analysen, einschließlich solcher, die auf KI-Technologien basieren, wird erhöht. Dies kann zu besseren Geschäftsentscheidungen führen, was wiederum zu verbesserten internen Prozessen, Wettbewerbsvorteilen und höheren Umsätzen führen kann. Gute Datenqualität verbessert auch die Informationen, die über BI-Dashboards und andere Analysen verfügbar sind. Wenn Geschäftsanwender die Analysen als vertrauenswürdig erachten, verlassen sie sich eher auf diese, anstatt Entscheidungen auf Basis von Bauchgefühl oder einfachen Tabellenkalkulationen zu treffen.
- Dadurch können sich Datenteams auf produktivere Aufgaben konzentrieren, anstatt Probleme zu beheben und Daten zu bereinigen, wenn Probleme auftreten. So können sie beispielsweise mehr Zeit darauf verwenden, Geschäftsanwendern und Datenanalysten dabei zu helfen, die verfügbaren Daten zu nutzen, und gleichzeitig Best Practices für die Datenqualität im Geschäftsbetrieb zu fördern.
Datenqualität versus Datenintegrität versus Data Profiling
Die Begriffe Datenqualität und Datenintegrität werden manchmal synonym verwendet, obwohl sie unterschiedliche Bedeutungen haben. Gleichzeitig betrachten manche Menschen Datenintegrität als einen Aspekt der Datenqualität oder Datenqualität als einen Bestandteil der Datenintegrität. Andere betrachten sowohl Datenqualität als auch Datenintegrität als Teil einer umfassenderen Data Governance, während einige Datenintegrität als ein breiteres Konzept betrachten, das Datenqualität, Data Governance und Datenschutz zu einer einheitlichen Maßnahme zur Gewährleistung der Genauigkeit, Konsistenz und Sicherheit von Daten kombiniert.
Aus einer breiteren Perspektive betrachtet, konzentriert sich die Datenintegrität auf die logische und physische Gültigkeit der Daten. Die logische Integrität umfasst Datenqualitätsmaßnahmen und Datenbankattribute wie die referenzielle Integrität, die sicherstellt, dass verwandte Datenelemente in verschiedenen Datenbanktabellen gültig sind.
Die physische Integrität befasst sich mit Zugriffskontrollen und anderen Sicherheitsmaßnahmen, die verhindern sollen, dass Daten von unbefugten Benutzern verändert oder beschädigt werden. Sie befasst sich auch mit Schutzmaßnahmen wie Backups und Disaster Recovery. Im Gegensatz dazu konzentriert sich die Datenqualität eher auf die Fähigkeit der Daten, ihren spezifischen Zweck zu erfüllen.
Data Profiling fügt eine weitere Ebene hinzu: Während die Datenqualität sicherstellt, dass Daten verwendbar sind, und die Datenintegrität sicherstellt, dass sie vertrauenswürdig sind, spezifiziert Data Profiling, was tatsächlich in den Daten enthalten ist. Dazu gehört die Untersuchung, Analyse und Zusammenfassung von Daten, um deren Struktur und Inhalt zu verstehen.
Es ist hilfreich, sich die Datenqualität als Endziel, die Datenintegrität als Leitprinzip und Data Profiling als den Diagnoseprozess vorzustellen, mit dem die beiden anderen Ziele erreicht werden sollen.
Wie man die Datenqualität bewertet
Die folgenden wesentlichen Schritte müssen Teil einer Datenqualitätsbewertung sein:
- Definieren Sie Anforderungen an die Datenqualität. Was bedeutet hohe Qualität für das Unternehmen? Welche Dimensionen sind am wichtigsten und wie werden sie gemessen?
- Erfassen Sie die Datenbestände. Führen Sie Basisstudien durch, um die relative Genauigkeit, Eindeutigkeit und Gültigkeit jedes Datensatzes zu messen. Die festgelegten Basiswerte können dann kontinuierlich mit den Daten verglichen werden, um sicherzustellen, dass bestehende Probleme behoben werden, und um neue Probleme mit der Datenqualität zu identifizieren.
- Listen Sie die Datenquellen auf und priorisieren Sie sie. Erfassen Sie alle Datenbanken, Programmierschnittstellen (API) und anderen Quellen, die in den Umfang der Qualitätsbewertung fallen.
- Erstellen Sie ein Datenprofil. Analysieren Sie die Struktur und den Inhalt aller Daten unter Berücksichtigung von Vollständigkeit, Wertverteilungen, Formatkonsistenz und Ausreißern.
- Bewerten und berichten Sie über die Datenqualität. Messen Sie anhand ausgewählter Dimensionen, vergeben Sie Bewertungen und ordnen Sie die identifizierten Probleme nach ihrer Bedeutung.
- Untersuchen Sie die Ursachen der Probleme. Sobald Probleme identifiziert wurden, verfolgen Sie diese zurück zu den Arbeitsabläufen und Einstiegspunkten, um die Ursachen für die Behebung zu ermitteln.
- Führen Sie eine kontinuierliche Überwachung durch. Nachdem Problembereiche identifiziert wurden, behalten Sie diese im Auge.
Für die Bewertung der Datenqualität wurden verschiedene Methoden entwickelt. So haben beispielsweise die Datenmanager der Optum Healthcare Services, einer Tochtergesellschaft der UnitedHealth Group, im Jahr 2009 das Data Quality Assessment Framework (DQAF) entwickelt, um eine Methode zur Bewertung der Datenqualität zu formalisieren. Das DQAF enthält Richtlinien zur Messung der Datenqualität anhand von vier Dimensionen: Vollständigkeit, Aktualität, Gültigkeit und Konsistenz. Optum hat Details zu diesem Rahmenwerk als mögliches Modell für andere Organisationen veröffentlicht.

Der Internationale Währungsfonds (IWF), der das globale Währungssystem überwacht, hat ebenfalls eine Bewertungsmethodik (PDF) mit dem gleichen Namen wie die von Optum festgelegt. Sein Rahmenwerk konzentriert sich auf Genauigkeit, Zuverlässigkeit, Konsistenz und andere Datenqualitätsmerkmale in den statistischen Daten, die die Mitgliedsländer dem IWF vorlegen müssen. Darüber hinaus hat das Office of the National Coordinator for Health Information Technology der US-Regierung ein Datenqualitäts-Framework für demografische Patientendaten, die von Gesundheitsorganisationen erfasst werden, detailliert beschrieben.
Wie man die Datenqualität verbessert
Die Bewertung ist wichtig. Aber die kontinuierliche Verbesserung der Daten sollte Priorität haben. Die folgenden Schritte sind für die Verbesserung der Datenqualität unerlässlich:
- Legen Sie klare Ziele fest. Eine zentrale Frage bei der Bewertung der Datenqualität lautet: Was bedeutet hochwertige Daten für die Organisation? Die Antworten auf diese Frage sollten dazu verwendet werden, die Geschäftsziele mit den Datenqualitätsanforderungen in Einklang zu bringen, die für die kontinuierliche Datenverbesserung festgelegt werden. Die priorisierten Dimensionen – Genauigkeit, Vollständigkeit, Aktualität und Gültigkeit – stehen dabei im Mittelpunkt.
- Priorisieren Sie die Probleme. Sobald Datenqualitätsprobleme in der Organisation aufgedeckt wurden, ist es wichtig, sie nach ihren Auswirkungen auf die Prozesse und die Effizienz der Organisation zu ordnen, um die wichtigsten Probleme effektiv zu beheben. Dies kann sich im Laufe der Zeit ändern und sollte daher regelmäßig überprüft werden.
- Legen Sie Standards für die Behebung fest. Stellen Sie im Interesse der Konsistenz und Effizienz sicher, dass die Maßnahmen zur Behebung im gesamten Unternehmen bekannt sind, verstanden werden und eingehalten werden.
- Implementieren Sie Data Governance. Es ist ratsam, Datenrollen festzulegen – Eigentümer, Verwalter und Verwahrer. Datenrichtlinien und -standards sollten offiziell veröffentlicht und gepflegt werden, und Metadaten, Datendefinitionen und Transformationslogik sollten dokumentiert werden.
In vielen Unternehmen sind Analysten, Ingenieure und Datenqualitätsmanager in erster Linie für die Behebung von Datenfehlern und die Lösung anderer Datenqualitätsprobleme verantwortlich. Sie haben gemeinsam die Aufgabe, fehlerhafte Daten in Datenbanken und anderen Datenrepositorien zu finden und zu bereinigen, oft mit Unterstützung anderer Datenmanagementexperten, darunter Datenmanager und Data-Governance-Programmmanager.
An einer Datenqualitätsinitiative können auch Geschäftsanwender, Datenwissenschaftler und andere Analysten beteiligt sein, um die Anzahl der Datenqualitätsprobleme zu reduzieren. Die Teilnahme kann zumindest teilweise durch das Data-Governance-Programm des Unternehmens erleichtert werden. Darüber hinaus bieten viele Unternehmen Schulungen für Endnutzer zu Best Practices im Bereich Datenqualität an. Ein gängiges Mantra unter Datenmanagern lautet, dass jeder in einem Unternehmen für die Datenqualität verantwortlich ist.
Um Datenqualitätsprobleme anzugehen, erstellt ein Datenmanagementteam häufig eine Reihe von Datenqualitätsregeln, die auf den Geschäftsanforderungen für Betriebs- und Analysedaten basieren. Die Regeln definieren die erforderlichen Datenqualitätsstufen und legen fest, wie Daten bereinigt und standardisiert werden sollten, um Genauigkeit, Konsistenz und andere Datenqualitätsmerkmale zu gewährleisten.
Nachdem die Regeln festgelegt wurden, führt ein Datenmanagementteam in der Regel eine Datenqualitätsbewertung durch und dokumentiert Fehler und andere Probleme – ein Verfahren, das in regelmäßigen Abständen wiederholt werden sollte, um eine möglichst hohe Datenqualität zu gewährleisten.
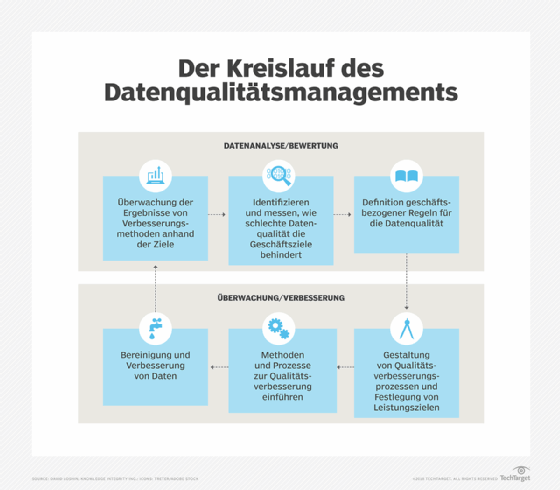
Allerdings gehen nicht alle Datenmanagementteams gleich mit dem Thema Datenqualität um. So hat beispielsweise der Datenmanagementberater David Loshin einen Datenqualitätsmanagementzyklus (PDF) skizziert, der mit der Identifizierung und Messung der Auswirkungen schlechter Daten auf den Geschäftsbetrieb beginnt. Anschließend definiert das Team Datenqualitätsregeln und legt Leistungsziele zur Verbesserung der Datenqualitätskennzahlen fest.
Als Nächstes entwirft und implementiert das Team spezifische Prozesse zur Verbesserung der Datenqualität. Dazu gehören die Datenbereinigung oder das Data Scrubbing, die Behebung von Datenfehlern und die Verbesserung von Datensätzen durch Hinzufügen fehlender Werte oder Bereitstellung aktuellerer Informationen oder zusätzlicher Datensätze.
Die Ergebnisse werden dann überwacht und anhand der Leistungsziele gemessen. Verbleibende Mängel in der Datenqualität dienen als Ausgangspunkt für die nächste Runde geplanter Verbesserungen. Ein solcher Zyklus soll sicherstellen, dass die Bemühungen zur Verbesserung der Gesamtdatenqualität auch nach Abschluss einzelner Projekte fortgesetzt werden.
Tools und Techniken für das Datenqualitätsmanagement
Unternehmen greifen häufig auf Tools für das Datenqualitätsmanagement zurück, um ihre Bemühungen zu optimieren. Diese Tools können Datensätze abgleichen, Duplikate löschen, neue Daten validieren, Korrekturmaßnahmen festlegen und personenbezogene Daten in Datensätzen identifizieren. Einige Produkte können auch Datenprofile erstellen, die Datensätze untersuchen, analysieren und zusammenfassen.
Viele dieser Tools verfügen mittlerweile über erweiterte Datenqualitätsfunktionen, die Aufgaben und Verfahren automatisieren, häufig durch den Einsatz von maschinellem Lernen und anderen KI-Technologien. Die meisten Tools umfassen auch zentralisierte Konsolen oder Portale für die Durchführung von Verwaltungsaufgaben. Beispielsweise können Benutzer über die zentrale Schnittstelle Regeln für den Umgang mit Daten erstellen, Datenbeziehungen identifizieren oder Datentransformationen automatisieren.
Datenqualitätsmanager und Datenverwalter können auch Collaboration- und Workflow-Tools verwenden, die gemeinsame Ansichten der Data Repositories des Unternehmens bieten und es ihnen ermöglichen, bestimmte Datensätze zu überwachen. Diese und andere Datenmanagementtools können als Teil einer umfassenderen Data-Governance-Strategie eines Unternehmens ausgewählt werden. Die Tools können auch eine Rolle bei den Stammdatenmanagement-Initiativen des Unternehmens spielen, mit denen Register für Daten zu Kunden, Produkten, Lieferketten und anderen Datenbereichen eingerichtet werden.
Im Folgenden finden Sie Beispiele für Datenqualitätsplattformen:
- Acceldata
- Ataccama
- Bigeye
- Great Expectations GX Cloud
- Informatica Data Quality
- Monte Carlo Data + AI Observability Platform
- Qlik
- SAP Data Services
- SAS Data Quality
- Soda Core
Zu den aktuellen Techniken für das Datenqualitätsmanagement gehören das KI-gestützte Qualitätsmanagement, bei dem Plattformen automatisch Qualitätsregeln erstellen und durchsetzen, sowie die Stream-First-Qualitätsüberwachung, die die Echtzeitvalidierung und Anomalieerkennung für unbegrenzte Datenströme unterstützt. Beachten Sie, dass einige dieser Plattformen Open Source sind.
Neue Herausforderungen für die Datenqualität
Viele Jahre lang konzentrierten sich die Bemühungen um Datenqualität auf strukturierte Daten, die in relationalen Datenbanken gespeichert waren, der damals dominierenden Technologie für die Datenverwaltung. Mit der zunehmenden Verbreitung von Cloud Computing und Big-Data-Initiativen wuchs jedoch auch die Bedeutung der Datenqualität. Neben strukturierten Daten müssen Datenmanager nun auch unstrukturierte und semistrukturierte Daten berücksichtigen, wie Textdateien, Internet-Clickstream-Datensätze, Sensordaten sowie Netzwerk-, System- und Anwendungsprotokolle.
Die folgenden Faktoren spielen eine Rolle für die Datenqualität und erhöhen die Komplexität der Datenverwaltung:
- Viele Unternehmen arbeiten heute sowohl mit lokalen als auch mit Cloud-Systemen.
- Die Datenquellen nehmen rasant zu, da Unternehmen immer mehr externe Daten in ihre Prozesse integrieren.
- Moderne Data Stacks werden immer komplexer.
- Immer mehr Unternehmen integrieren maschinelles Lernen und andere KI-Technologien in ihre Abläufe und Produkte; die Qualitätsanforderungen an die in diesen Abläufen verwendeten Daten sind in der Regel sehr hoch.
- Viele Unternehmen haben Echtzeit-Daten-Streaming-Plattformen implementiert, die kontinuierlich große Datenmengen in Unternehmenssysteme einspeisen.
- Vielen Unternehmen fehlt eine einheitliche Governance.
- Datenwissenschaftler implementieren komplexe Datenpipelines, um ihre Forschung und fortgeschrittenen Analysen zu unterstützen.
Auch aufgrund der Einführung von Datenschutzgesetzen wie der Datenschutz-Grundverordnung der Europäischen Union und dem California Consumer Privacy Act nehmen die Bedenken hinsichtlich der Datenqualität zu. Beide Maßnahmen geben Menschen das Recht, auf die personenbezogenen Daten zuzugreifen, die Unternehmen über sie sammeln. Das bedeutet, dass Unternehmen in der Lage sein müssen, alle Datensätze zu einer Person in ihren Systemen zu finden, ohne dass aufgrund ungenauer oder inkonsistenter Daten etwas übersehen wird.







