Data Lineage (Datenherkunft)
Was ist Data Lineage (Datenherkunft)?
Datenherkunft ist der Prozess der Dokumentation des Weges, den Daten im Laufe der Zeit durch die IT-Systeme eines Unternehmens nehmen, wobei ihre Quelle, ihr Fluss zwischen den Systemkomponenten, ihre mögliche Umwandlung für verschiedene Verwendungszwecke innerhalb der Datenpipeline und ihr endgültiger Bestimmungsort aufgezeigt werden.
Data-Lineage-Werkzeuge verwenden Metadaten, um sowohl Endbenutzern als auch Datenmanagement-Experten die Möglichkeit zu geben, die Historie von Datenbeständen zu verfolgen und Informationen über den geschäftlichen Nutzen oder die technischen Eigenschaften dieser Bestände zu erhalten. Ein effektiver Data-Lineage-Prozess ermöglicht es den Beteiligten, die Genauigkeit und Konsistenz der Daten zu überprüfen und die Ursache von Fehlern zurückzuverfolgen, um die Datenqualität sicherzustellen.
Informationen zur Datenherkunft werden aus operativen Systemen während der Datenverarbeitung sowie aus Data Warehouses und Data Lakes erfasst, in denen Datensätze für Business Intelligence (BI) und Datenanalyseanwendungen gespeichert sind. Zusätzlich zur detaillierten Dokumentation können Datenflusskarten und -diagramme erstellt werden, um eine visuelle Darstellung der Datenherkunft in Bezug auf Geschäftsprozesse zu ermöglichen. Um Endbenutzern den Zugriff auf Informationen zur Datenherkunft zu vereinfachen, werden diese häufig in Datenkataloge integriert, in denen Datenbestände und die zugehörigen Metadaten inventarisiert werden.
Warum ist die Datenherkunft wichtig?
Der Data-Lineage-Prozess liefert wichtige Informationen, die für das Datenmanagement, die Datenverwaltung und die Datenanalyse eines Unternehmens von entscheidender Bedeutung sind. Die Herkunftsdetails identifizieren die Datenquelle, den Zielort, die durchgeführten Transformationen sowie etwaige Anomalien oder Fehler. Die Verfolgung des Prozesses hilft Unternehmen, die Daten effektiver zu verwalten und zu nutzen. Ohne diese Details ist es viel schwieriger, den potenziellen Geschäftswert der Daten voll auszuschöpfen. Ein Mangel an Informationen über Daten macht es außerdem kostspielig und zeitaufwändig, Daten zu überprüfen, um ihre Genauigkeit, Konsistenz und Gesamtqualität sicherzustellen.
Zu den wichtigsten Vorteilen der Datenherkunft gehören:
- Genauere und nützlichere Analysen. Da Analyseteams und Geschäftsanwender wissen, woher die Daten stammen und was sie bedeuten, verbessert die Datenherkunft ihre Fähigkeit, die Daten zu finden, die sie für BI, Data Science und andere Zwecke benötigen. Dies führt zu besseren Analyseergebnissen und erhöht die Wahrscheinlichkeit, dass die Datenanalyse aussagekräftige Informationen liefert, die eine bessere Entscheidungsfindung unterstützen und vorantreiben.
- Stärkere Data Governance. Die Datenherkunft hilft auch bei der Verfolgung von Daten und der Durchführung anderer wichtiger Teile des Daten-Governance-Prozesses. Sie unterstützt Data-Governance-Manager und Teammitglieder dabei, sicherzustellen, dass Daten valide, sauber und konsistent sind und dass sie im gesamten Unternehmen sicher, ordnungsgemäß verwaltet und verwendet werden.
- Strengere Datensicherheit und Datenschutz. Unternehmen können Datenherkunftsinformationen nutzen, um sensible Daten zu identifizieren, die besonders strenge Sicherheitskontrollen erfordern. Sie können auch verwendet werden, um unterschiedliche Zugriffsrechte für Benutzer basierend auf Datentyp, Benutzerrolle oder Sicherheits- und Datenschutzrichtlinien festzulegen. Darüber hinaus erleichtert die Datenherkunft die Bewertung potenzieller Risiken für Daten im Rahmen einer umfassenderen Risikomanagementstrategie für Unternehmen.
- Verbesserte Einhaltung gesetzlicher Vorschriften. Die Datenherkunft kann bei der Planung und Umsetzung strengerer Sicherheitsmaßnahmen für Unternehmensdaten helfen. Diese Schutzmaßnahmen können Unternehmen dabei unterstützen, die Einhaltung von Datenschutzgesetzen und anderen Vorschriften sicherzustellen. Eine gut dokumentierte Data Lineage erleichtert auch die Durchführung interner Compliance Audits und die Berichterstattung über den Compliance-Status. Dies kann Unternehmen dabei helfen, Compliance-Lücken zu schließen und sicherzustellen, dass alle innerhalb des Unternehmens verwendeten und verarbeiteten Daten den internen Richtlinien und gesetzlichen Standards entsprechen.
- Optimiertes Datenmanagement. Neben der Verbesserung der Datenqualität verbessert die Datenherkunft eine Vielzahl anderer Datenmanagementaufgaben. Beispiele hierfür sind die Verwaltung von Datenmigrationen sowie die Erkennung und Behebung von Lücken in Datensätzen. Darüber hinaus kann der Datenherkunftsprozess dazu beitragen, Datenflüsse und -änderungen innerhalb der Datenpipeline zu verdeutlichen, Datensilos aufzubrechen und den Datenaustausch sowie die datengesteuerte Zusammenarbeit zwischen Benutzern, Teams und Abteilungen zu erleichtern.
Einsatzgebiete für Data Lineage
Data-Lineage-Datensätze liefern nützliche Informationen über Daten während ihres gesamten Lebenszyklus. Diese Datensätze können Datenwissenschaftlern, Datenanalysten und Geschäftsanwendern helfen, die Daten, mit denen sie arbeiten, zu verstehen und ihre verschiedenen Berührungspunkte entlang der Datenpipeline nachzuverfolgen. Der Data-Lineage-Prozess trägt auch dazu bei, Daten fehlerfrei, konsistent und relevant für die spezifischen Informationsbedürfnisse der Benutzer zu machen.
Die Datenherkunft spielt auch eine wichtige Rolle bei der Datenverwaltung. Ohne Kenntnis und Visualisierung des gesamten Datenflusses kann es sehr schwierig sein, die Verfügbarkeit, Verwendbarkeit, Integrität und Sicherheit von Daten zu verwalten und die Datennutzung auf der Grundlage interner Standards und Richtlinien zu kontrollieren. Die Data Lineage vereinfacht auch zwei wichtige Verfahren der Data Governance: die Analyse der Ursachen von Datenqualitätsproblemen und die Bewertung der Auswirkungen von Änderungen an Datensätzen. Durch ein besseres Verständnis dieser Aspekte der Daten ermöglicht Data Lineage eine schnellere und effektivere Behebung von Datenfehlern.
Die Verfolgung der Datenherkunft ist auch für das Stammdatenmanagement (Master Data Management, MDM) wichtig. Das Hauptziel von MDM ist die Erstellung eines einheitlichen Datensatzes zu Geschäftseinheiten über verschiedene IT-Systeme hinweg, um die unternehmensweite Genauigkeit und Konsistenz dieser Einheiten sicherzustellen. Genaue und konsistente Datenelemente optimieren den Datenaustausch zwischen unterschiedlichen Geschäftssystemen, vereinfachen die Datenverarbeitung in IT-Umgebungen und tragen dazu bei, die Zuverlässigkeit der in Business Intelligence (BI) und Analyseanwendungen verwendeten Daten zu erhöhen.
Ein weiterer wichtiger Anwendungsfall für die Datenherkunft ist die Einhaltung gesetzlicher Vorschriften. Die Datenherkunft liefert Prüfpfade für Daten, mit denen Daten- und Compliance-Experten sicherstellen können, dass das Unternehmen Daten in Übereinstimmung mit allen geltenden Data-Governance-Richtlinien und -Vorschriften erfasst, speichert, verarbeitet und nutzt. Einfach ausgedrückt: Die Rückverfolgung der Datenherkunft kann Unternehmen dabei helfen, die Einhaltung relevanter Datenschutz- und Sicherheitsvorschriften wie der Datenschutz-Grundverordnung (DSGVO), des Health Insurance Portability and Accountability Act (HIPAA), des Payment Card Industry Data Security Standard (PCI DSS) und des California Consumer Privacy Act (CCPA) kontinuierlich sicherzustellen.
Data Lineage ist auch für die Datenmodellierung und Datenmigration wichtig. Mit einem Datenherkunftsprozess können Unternehmen die Verknüpfungen und Abhängigkeiten zwischen verschiedenen Datenelementen modellieren und visualisieren. Dies erleichtert die Datenverwaltung und fördert eine effektivere Datenanalyse und -nutzung. Die Datenherkunft erleichtert auch die Datenmigration, indem sie Datenorte und -typen klar definiert. Das Verständnis dieser Aspekte ermöglicht es Migrationsteams, Migrationen besser zu planen und die Umstellung auf ein neues Speichersystem zu beschleunigen, während Fehler und Kostenüberschreitungen minimiert werden.
Data Lineage im Vergleich zu Datenklassifizierung und Data Provenance
Die Datenherkunft ist eng mit zwei anderen Datenverwaltungsprozessen verbunden: der Datenklassifizierung und der Data Provenance. Die drei Prozesse werden oft zusammen verwendet, aber es gibt einige Unterschiede zwischen ihnen. Es ist wichtig, diese Unterschiede zu verstehen, um den Geschäftswert der Unternehmensdaten zu maximieren.
Datenklassifizierung
Wie der Begriff schon sagt, werden bei der Datenklassifizierung Daten anhand ihrer Merkmale in verschiedene Kategorien eingeteilt, vor allem aus Sicherheits- und Compliance-Gründen. Diese Merkmale werden in der Regel vom Benutzer definiert.
Die Klassifizierung kategorisiert Daten anhand ihrer Sensibilität. Sie können beispielsweise als personenbezogene, geschützte, vertrauliche oder öffentliche Informationen klassifiziert werden. Auf diese Weise werden Datensätze, die ein höheres Maß an Sicherheit und strengere Zugriffskontrollen erfordern, von denen getrennt, die dieses Maß an Überwachung nicht benötigen. Die Datenherkunft wiederum liefert Informationen über Datensätze, die bei deren Klassifizierung hilfreich sein können.
Die Klassifizierung von Daten hilft zu klären, um welche Daten es sich handelt, wo sie sich befinden und in welcher Beziehung sie zu anderen Daten stehen. Diese Informationen über Daten erleichtern das Datenmanagement, das Risikomanagement und die Einhaltung gesetzlicher Vorschriften und ermöglichen es Benutzern, Daten einfacher abzurufen, zu sortieren und zu speichern oder zu löschen.
Data Provenance
Die Data Provenance ist die Geschichte der Daten. Obwohl sie oft als Synonym für Data Lineage angesehen wird, konzentriert sich die Datenherkunft eigentlich enger auf die Ursprünge der Daten. Sie liefert eine historische Aufzeichnung der Herkunft der Daten, das heißt ihres Erstellers, ihres Quellsystems, wie sie generiert wurden und wie, wann und von wem sie geändert wurden. Data Lineage und Data Provenance arbeiten Hand in Hand, wobei Letztere eine hochgradige Dokumentation darüber liefert, woher Daten stammen und was sie enthalten. Dies ermöglicht es Datenwissenschaftlern und anderen Benutzern, den Datenfluss und -änderungen zu verfolgen, was für die Gewährleistung der Genauigkeit, die Fehlerbehebung und die Optimierung der gesamten Datenpipeline wichtig ist.
Data Lineage und Data Governance
Der Kern der Data Governance besteht darin, Unternehmensrichtlinien für den Umgang mit Daten zu erstellen und deren Einhaltung sicherzustellen, um eine konsistente und ordnungsgemäße Datenverwaltung und -nutzung zu gewährleisten. Daten-Governance-Richtlinien können eine Reihe von Vorschriften und Leitlinien umfassen, darunter solche für Datenschutz (Sicherheit), Privatsphäre, Validierung (Qualität), Zugriff und Nutzung.
Um den Nutzen und den Geschäftswert von Daten zu maximieren, müssen Daten-Governance-Manager und Datenverwalter Datenanforderungen von Geschäftsanwendern einholen. Datenfachleute müssen außerdem mit den Mitgliedern des entscheidungsrelevanten Daten-Governance-Ausschusses zusammenarbeiten, um einen Konsens über Datendefinitionen zu erzielen, erforderliche Datenqualitätsmetriken festzulegen und die Richtlinien und zugehörigen Data-Governance-Verfahren zu entwickeln.
Es ist jedoch eine große Herausforderung, die Lücke zwischen der Definition von Daten-Governance-Richtlinien und deren tatsächlicher Umsetzung zu schließen. Die Datenherkunft kann die Umsetzung erleichtern, da sie Datenquellen und -flüsse dokumentiert, sodass Governance-Teams überwachen können, wie Daten durch Systeme fließen und dabei verändert und verwendet werden. Die Herkunftsinformationen tragen dazu bei, dass angemessene Datensicherheit und Zugriffskontrollen vorhanden sind und dass Daten in Übereinstimmung mit den Governance-Richtlinien gespeichert, gepflegt und verwendet werden.
Data Lineage kann auch bestimmte Governance-Aufgaben erleichtern. Ohne eine Möglichkeit, festzustellen, wo Datenfehler in Systeme gelangen, ist es für Datenverwalter und Datenqualitätsanalysten beispielsweise schwierig, diese zu identifizieren und zu beheben. Werden Datenfehler nicht erkannt, kann ein Unternehmen mit inkonsistenten oder ungenauen Analyseergebnissen konfrontiert sein, die zu falschen Geschäftsentscheidungen führen. Ein effektiver Datenherkunftsprozess erleichtert das Aufspüren und Beheben von Datenfehlern und verbessert so die Qualität und Nützlichkeit der Daten.
Bei der Ursachenanalyse von Datenfehlern bieten Lineage-Datensätze Einblick in die Abfolge der Verarbeitungsstufen, die ein Datensatz durchläuft. In jeder Stufe kann die Qualität überprüft werden, um festzustellen, wo Datenfehler ihren Ursprung haben. Ausgehend von der Stelle, an der ein Fehler erstmals festgestellt wurde, kann ein Datenverwalter überprüfen, ob die Daten den Erwartungen entsprachen und wann ein Fehler möglicherweise aufgetreten ist. Durch die genaue Bestimmung der Stufe, auf der die Daten bei der Eingabe konform waren, aber bei der Ausgabe fehlerhaft waren, können die an einem Datenverwaltungsprogramm beteiligten Mitarbeiter die Ursache des Fehlers beseitigen, um dessen Wiederauftreten zu verhindern, anstatt nur die fehlerhaften Daten zu korrigieren (und damit das Risiko eines erneuten Auftretens des Fehlers einzugehen).
Wenn Daten geändert werden, kann dies unbeabsichtigte Folgen nachgelagerter Prozesse haben. Indem ein Datenverwalter vom Zeitpunkt der Datenerstellung oder -erfassung aus vorwärts arbeitet, kann er sich auf die Dokumentation der Datenherkunft stützen, um Datenabhängigkeiten zu verfolgen und die von den Änderungen betroffenen Verarbeitungsphasen zu identifizieren. Diese Phasen können dann neu gestaltet werden, um die Änderungen zu berücksichtigen und sicherzustellen, dass die Daten in verschiedenen Systemen konsistent bleiben.
Data Lineage ist auch für die Business Impact Analysis (BIA) nützlich. Mit solchen Analysen können Unternehmen Probleme, die durch Änderungen an Quelldatenformaten und -strukturen verursacht werden, im Blick behalten und die Auswirkungen von Datenfehlern auf das Geschäft sowie das Risiko bewerten. Dies sind häufige Probleme in den zunehmend dynamischen Datenumgebungen von heute, die durch die Datenherkunft gelöst werden können. Die Datenherkunft ermöglicht es Unternehmen außerdem, eine umfassende und moderne Datenarchitektur zu schaffen, um die Unternehmensdatenlandschaft zu verwalten und das Datenbewusstsein, die Zugänglichkeit und die Vertrauenswürdigkeit zu verbessern.
Wichtige Techniken für Data Lineage
Zur Erfassung und Dokumentation von Data-Lineage-Informationen können verschiedene Techniken verwendet werden. Diese Techniken schließen sich nicht gegenseitig aus, sodass ein Unternehmen je nach Anwendungsanforderungen und Art seiner Datenumgebung mehrere Herkunftstechniken einsetzen kann.
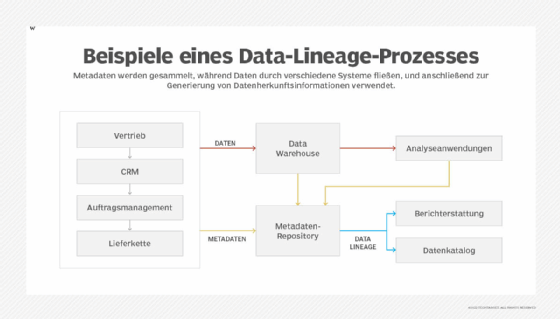
Zu den verfügbaren Methoden gehören:
- Daten-Tagging. Durch die Untersuchung von Metadaten können Tags auf Datensätze angewendet werden, um diese für Datenherkunftszwecke zu beschreiben und zu charakterisieren. Die Kennzeichnung kann manuell durch Datenverwalter, andere Mitglieder des Data-Governance-Teams und Endbenutzer erfolgen oder automatisch durch Software durchgeführt werden. Beispielsweise enthalten Data-Lineage-Tools und in Data-Governance-Software integrierte Lineage-Funktionen häufig automatisierte Algorithmen, mit denen Benutzer Datensätze kennzeichnen können. Um eine konsistente und korrekte Kennzeichnung zu gewährleisten, müssen die Benutzer des Tools dessen Kennzeichnungsstruktur kennen.
- Musterbasierte Lineage. Bei diesem Ansatz wird nach Mustern in mehreren Datensätzen gesucht, zum Beispiel nach ähnlichen Datenelementen, Zeilen und Spalten. Das Vorhandensein dieser Muster deutet darauf hin, dass Datensätze miteinander in Beziehung stehen und möglicherweise Teil eines Datenflusses sind, während Unterschiede in Datenwerten oder Attributen ein Zeichen dafür sind, dass die Daten bei der Übertragung von einem System in ein anderes transformiert wurden. Die Datentransformationen und Datenflüsse können dann als Teil der Datenherkunftsaufzeichnungen dokumentiert werden. Mit dieser Lineage-Methode müssen sich Benutzer nicht mit dem Code befassen, der für die Datengenerierung oder -transformation verwendet wird. Darüber hinaus ist sie technologieunabhängig und funktioniert daher mit jeder Art von Datenbanktechnologie (beispielsweise Oracle oder MySQL).
- Parsing-basierte Lineage. Bei dieser fortschrittlichen Methode analysieren Data-Lineage-Tools die Datenumwandlungs- und -verarbeitungslogik, Laufzeitprotokolldateien, Datenintegrations-Workflows und anderen Datenverarbeitungscode, um Herkunftsinformationen zu identifizieren und zu extrahieren. Das Parsing bietet einen End-to-End-Ansatz für die Verfolgung der Datenherkunft in verschiedenen Systemen und kann genauer sein als die musterbasierte Herkunftsanalyse. Da es jedoch auf der Rückentwicklung der Transformationslogik basiert, ist es auch komplexer.
Ein weiterer Ansatz zur Data Lineage ist vollständig manuell und personenabhängig. Dabei werden Geschäftsanwender, BI-Analysten, Datenwissenschaftler, Datenverwalter, Datenintegrationsentwickler und andere Mitarbeiter dazu befragt, wie Daten durch Systeme fließen und verwendet und verändert werden. Die gesammelten Informationen lassen sich verwenden, um Datenflüsse und Transformationen abzubilden. Diese Methode eignet sich für die Verfolgung der Datenherkunft in kleinen Datensätzen. Mit zunehmender Größe der Datenumgebungen werden Initiativen zur Datenherkunft jedoch immer komplexer. In solchen Fällen ist es sinnvoller, zunächst manuelle Data Lineage zu verwenden, bevor automatisierte Techniken implementiert werden.
Best Practices für Data Lineage
Im Folgenden sind einige Best Practices aufgeführt, die dabei helfen, einen Datenherkunftsprozess auf Kurs zu halten und sicherzustellen, dass er genaue und nützliche Informationen über Datensätze liefert:
- Beziehen Sie Führungskräfte und Anwender von Anfang an mit ein. Data-Governance-Programme benötigen die Unterstützung und Beteiligung der Führungskräfte, um erfolgreich zu sein. Das Gleiche gilt für die Datenherkunft. Die Unterstützung durch die Geschäftsleitung ist unerlässlich, um die Genehmigung und Finanzierung des Programms zu erhalten. Auch Geschäftsleiter und Mitarbeiter sollten einbezogen werden, um sicherzustellen, dass die Datenmanagement-Teams vollständig verstehen, wie Daten in Geschäftsprozessen verwendet werden, und um zu überprüfen, ob die Datenherkunftsinformationen relevant und gültig sind.
- Dokumentieren Sie sowohl die geschäftliche als auch die technische Data Lineage. Die geschäftliche Herkunft konzentriert sich auf hoher Ebene darauf, woher die Daten stammen, wie sie fließen und in welchem geschäftlichen Kontext sie stehen. Die technische Herkunft liefert Details zu Datenumwandlungen, Integrationen und Pipelines sowie eine Mischung aus Tabellen-, Spalten- und Abfrage-Level-Ansichten der Herkunft. Die Erfassung beider Arten liefert nützliche Informationen für Geschäftsanwender und Analyseteams sowie für Datenarchitekten, Datenmodellierer, Datenqualitätsanalysten und andere IT-Fachleute.
- Verbinden Sie die Datenherkunft mit realen Geschäfts- und IT-Anforderungen. Data Lineage sollte keine akademische Übung sein. Durch die Verknüpfung mit realen Geschäfts- und IT-Anforderungen können bessere Geschäftsentscheidungen und Strategien getroffen werden. Außerdem wird die Effektivität der Datenverwaltung und -steuerung verbessert und die Datenqualität und -konsistenz erhöht. Andernfalls ist die Investition wahrscheinlich verschwendet.
- Verfolgen Sie einen unternehmensweiten Ansatz für die Datenherkunft. Ein Datenherkunftsprozess, der sich nur auf einige Datensätze konzentriert, wird dem Unternehmen wahrscheinlich nur wenige Vorteile bringen. Um den Nutzen zu maximieren, sollte es sich um eine umfassende, unternehmensweite Initiative handeln, die alle in der Organisation verwendeten Daten einbezieht und auf einem einzigen, einheitlichen, zentralisierten Metadaten-Repository basiert, das die Herkunftsarbeit unterstützt.
- Erstellen Sie einen Datenkatalog mit eingebetteten Datenherkunftsinformationen. Das Auffinden und Verstehen relevanter Daten ist für BI- und Analytics-Anwender oft eine große Herausforderung. Durch die Erstellung eines Datenkatalogs kann ein Datenmanagementteam den Anwendern eine Bestandsaufnahme der verfügbaren Datenbestände zur Verfügung stellen, die auch Informationen zur Datenherkunft enthält.
Was Sie bei Tools für Data Lineage beachten sollten
Das manuelle Sammeln von Metadaten und das Dokumentieren der Datenherkunft erfordert einen erheblichen Aufwand an Ressourcen. Außerdem ist es fehleranfällig, was zu Problemen führen kann, insbesondere da Unternehmen zunehmend auf Datenanalysen angewiesen sind, um ihre Geschäftsabläufe zu steuern. Der beste Weg, um die Datenverwaltung zu unterstützen, ist der Einsatz von Tools, die die Darstellung der Datenherkunft verwalten und automatisch unternehmensweit abbilden.
Berücksichtigen Sie bei der Bewertung von Technologien für den möglichen Kauf eines Tools für Data Lineage die folgenden Anwendungsfunktionen, die die Lösung bieten sollte:
- Nativ auf eine Vielzahl von Datenquellen und Datenprodukten zugreifen, die darin enthaltenen Metadaten erfassen und für die Datenverwaltung sammeln, zunehmend durch den Einsatz von KI und Algorithmen für maschinelles Lernen.
- Die erfassten Metadaten in einem zentralen Repository aggregieren.
- Datentypen ableiten und ordnen Sie häufige Verwendungen von Referenzdaten Datenelementen aus verschiedenen Systemen zu.
- Endbenutzern vereinfachte Darstellungen der aggregierten Metadaten zur Verfügung stellen und die Zusammenarbeit bei der Validierung der Metadatenbeschreibungen unterstützen.
- Die End-to-End-Zuordnungen der Datenflüsse durch die Systeme des Unternehmens dokumentieren.
- Visualisierte Darstellungen der Datenherkunft erstellen.
- Fügen Sie APIs für Entwickler hinzu, mit denen sie Anwendungen erstellen können, die die Herkunftsdatensätze abfragen können.
- Einen invertierten Index erstellen, um Datenelementnamen ihren Verwendungen in verschiedenen Verarbeitungsstufen zuzuordnen.
- Eine Suchfunktion bieten, um den Datenfluss vom Ursprung bis zu den nachgelagerten Zielen schnell zu verfolgen.
- Benutzern die Überwachung von Datenflüssen ermöglichen, sowohl vorwärts als auch rückwärts.
Anbieter und Tools für Data Lineage
Tools zur Dokumentation und Verwaltung der Datenherkunft werden von einer Vielzahl von Anbietern angeboten:
- Große IT-Anbieter, die Datenmanagement-Plattformen verkaufen, wie IBM, Informatica, Microsoft (Purview), Oracle (Oracle Cloud Infrastructure), SAP und SAS, sowie Cloud-Plattformanbieter AWS (Amazon DataZone) und Google Cloud.
- Softwareanbieter mit breitem Produktportfolio, das Datenmanagement- und Governance-Tools umfasst, wie Hitachi Vantara (Pentaho), OneTrust, Cloudera (Octopai), Precisely und Quest Software.
- Anbieter von Datenmanagement- und Governance-Tools, wie ASG Technologies (Teil von Rocket Software), Ataccama, Boomi, Collibra, Semarchy, Syniti (Teil von Capgemini) und Talend (Teil von Qlik).
- Spezialisten für Metadatenmanagement und Datenherkunft, wie Alex Solutions und Manta (Teil von IBM).
- Anbieter von Datenkatalog-Tools, wie Alation, Atlan, Data.world und OvalEdge.
Anbieter, die Self-Service-Software zur Datenaufbereitung für Dateningenieure und Analyseteams anbieten, wie DataRobot und Alteryx, unterstützen ebenso wie verschiedene Anbieter von BI- und Analyse-Tools Data-Lineage-Funktionen.
Darüber hinaus stehen Open-Source- und/oder kostenlose Tools zur Unterstützung von Datenherkunftsprozessen zur Verfügung, wie Apache Atlas und OpenLineage.
Unternehmen müssen wissen, wo sich ihre Daten befinden, um welche Daten es sich handelt, welche Governance-Anforderungen gelten und in welcher Beziehung sie zu den übrigen Daten stehen. Erfahren Sie mehr über Datenklassifizierung und wie künstliche Intelligenz (KI) dabei helfen kann. Informieren Sie sich auch über Funktionen, auf die Sie bei Datenqualitätsmanagement-Tools achten sollten.
Auf einen Blick: Data Lineage
Data Lineage (Datenherkunft) beschreibt die lückenlose Nachverfolgung von Daten – von ihrer Quelle über Transformationen und Bewegungen in IT-Systemen bis zu ihrem Ziel. Sie liefert Transparenz, verbessert Datenqualität und Analysen, stärkt Governance, Sicherheit und Compliance und unterstützt Unternehmen bei Migrationen, Modellierung und Stammdatenmanagement. Data Lineage ergänzt Prozesse wie Datenklassifizierung und Data Provenance und erleichtert die Umsetzung von Data-Governance-Richtlinien. Mithilfe unterschiedlicher Techniken und spezialisierter Tools, zunehmend automatisiert und KI-gestützt, werden Datenflüsse dokumentiert und visualisiert. Best Practices betonen die enge Verbindung von technischer und geschäftlicher Perspektive sowie die Einbindung in Datenkataloge und Unternehmensprozesse. Damit wird Data Lineage zu einem zentralen Instrument für modernes Datenmanagement und datengestützte Entscheidungsfindung.






