
Looker_Studio - stock.adobe.com
Die Unterschiede strukturierter und unstrukturierter Daten
Strukturierte und unstrukturierte Daten stellen Herausforderungen bei der Kategorisierung, Definition und Speicherung dar. Wir informieren Sie über die wesentlichen Unterschiede.

Die zwei hauptsächlichen Arten von Daten werden als strukturiert und unstrukturiert bezeichnet: Strukturierte Daten sind in der Regel alphanumerisch, aufgrund von geteilten Dateneigenschaften leicht zu kategorisieren und unkompliziert in einem vordefinierten Datenmodell wie zum Beispiel einer Datenbank abzulegen. Unstrukturierte Daten stellen in der Regel etwas anderes als alphanumerische Größen dar: Sie passen nicht korrekt in vordefinierte, gleichförmige Rahmenwerke, und sie werden oft in ihrem natürlichen Format abgespeichert.
Der Begriff Daten umfasst fast alles, was in digitaler Form ausgedrückt oder repräsentiert werden kann. Bis zu einem gewissen Grad spielt die Art der Daten nicht die gleiche Rolle wie ihr Kontext oder die Beziehungen mit anderen Datenbits. Kontext und Beziehungen helfen dabei, Rohdaten in nützliche Informationen zu verwandeln.
Die Fähigkeit, Daten zu beeinflussen, hängt wesentlich davon ab, wie wir Datenelemente mit dem Ziel klassifizieren, ihre Beziehung zu größeren Datensets und ihre Gemeinsamkeiten zu erfassen. Datenklassifizierung ermöglicht die Suche nach Clustern von Daten, um bestimmte Elemente zu entdecken, die den Suchkriterien entsprechen. Um das alles zu erreichen, müssen gleichmäßige Strukturen aufgebaut werden, um Daten in einem konsistenten Zustand zu erfassen oder zu definieren – deshalb spricht man von strukturierten Daten.
Aber mit Daten umzugehen, verläuft nicht immer geradlinig, wie jeder bestätigen kann, der einem Haufen Daten einen Sinn zuzuschreiben versucht hat. Nicht alle Daten neigen dazu, definiert und klassifiziert zu werden – und das kann Probleme verursachen.
Heute sind Daten in der Regel mehr als eine alphanumerische Darstellung von irgend etwas. Es kann sich um Video-, Audio- oder Dokumentdateien, Social-Media-Notizen oder E-Mail-Inhalte handeln. Diese unstrukturierten Datentypen passen nicht unbedingt in vordefinierte Rahmenwerke, während sie schnell zu den vorherrschenden Datenarten in Unternehmen werden.
Um die Sache noch weiter zu verkomplizieren, ist es manchmal notwendig, strukturierte und unstrukturierte Daten miteinander zu kombinieren, um die gewünschten Informationen zu bekommen. Dieser hybride Ansatz steht für einen dritten Datentyp – halbstrukturierte Daten genannt –, der wahrscheinlich die am schnellsten wachsende Kategorie von allen drei darstellt.
Was sind strukturierte Daten?
Strukturierte Daten sind Daten, die aufgrund ihrer Inhalte und ihres Formats kategorisiert, definiert und in einer konsistenten Struktur gespeichert werden können, zum Beispiel in einem Datenbankmanagementsystem (DBMS).
Die einzelnen Elemente von strukturierten Daten können in einer Art und Weise zusammengesetzt sein, die zu Standardvorgaben passen – wie zum Beispiel den folgenden:
- Text-, numerische oder alphanumerische Daten
- Anzahl der Zeichen, die das Element bilden
- Natur der Datenelemente, nach denen sie in logischer Folge gruppiert werden können, basierend auf ähnlichen oder gleichen Werten
Daten in strukturierten Umgebungen zu platzieren, wird manchmal als „schema-on-write“ bezeichnet, was bedeutet, dass Daten neu in spezifisch definierte Felder in ein Data Repository geschrieben oder dorthin bewegt werden. Die Definitionen sind in der Regel eng gefasst, um sicherzustellen, dass nur Daten des gleichen Typs an die geeigneten Stellen im Schema geschrieben werden.
Zum Beispiel kann ein Eingabefeld für Postleitzahlen als ein numerisches Feld mit einer Länge von fünf Stellen definiert sein, um so alle Daten zu verhindern, auf die diese beiden Kriterien zum Eintrag in diese Struktur nicht zutreffen. Zusätzliche Sicherheitsmaßnahmen gegen unberechtigte Daten können durch Filter eingerichtet werden, die einen korrekten Eintrag weiter festlegen – wie zum Beispiel eine Reihe von Postleitzahlen, die alle mit „900“ beginnen müssen.
Eine weitere Methode, um die Einträge auf ein einziges Format festzulegen, besteht in einem genauen Eingabefeld. Diese Vorlage zwingt effektiv jeden Eintrag in eine Form, die externe Suchen erleichtert – zum Beispiel könnte eine Vorlage für Nummern der Sozialversicherung folgendes Format erzwingen: ###-##-####.
Die Fähigkeit, Daten in dieser Art und Weise zu gruppieren, erleichtert die Suche nach bestimmten Eingaben wegen ihrer Uniformität, mit der die Daten gespeichert sind. Eine Datenbank für Adressen wird eventuell folgende Standardfelder aufweisen:
- Vor- und Nachname
- Straße und Hausnummer
- Stadt
- Region
- Postleitzahl
Um zum Beispiel alle Einwohner von Oregon in den USA zu finden und aus der Datei herauszuziehen, könnte man die Postleitzahlen suchen, die mit „97“ beginnen.
Für anspruchsvollere Datenmanipulationen ermöglicht ein relationales DBMS (RDBMS) die Aufstellung von Beziehungen zwischen zwei oder mehr verschiedenen Datensätzen von meistens unähnlichen Daten. Die unterschiedlichen Datensätze innerhalb einer relationalen Datenbank werden „tables“ genannt. Innerhalb dieser Tabellen sind die Datensammlungen nach Spalten (Feldern) und Zeilen (Aufzeichnungen oder Dateneinträge) organisiert. Durch die Verknüpfung einer ähnlichen Spalte oder eines Feldes, das in beiden Tabellen vorkommt, können die Daten effektiv kombiniert werden, um noch mehr Informationen zu erhalten.
Wenn eine Adressdatenbank zum Beispiel aus einer solchen Tabelle und einer zweiten Tabelle mit einer Liste der Studenten mit ihren hauptsächlich besuchten Kursen und ihren Heimatorten besteht, könnte ein neuer Datensatz extrahiert werden, der die Verteilung von Hauptkursen in einer bestimmen Region anzeigt.
SQL (Structured Query Language) erleichtert Extraktion und Zusammenfügen von Daten aus einer Gruppe von Tabellen. SQL etablierte ein Standard-Set von Kommandos, um Zugang zu Daten zu bekommen, Daten zu finden und in aussagekräftigen Formen zu vereinigen.
In einigen Fällen können relationale oder nicht-relationale Datenbanken eine Spalte umfassen, die auf ein unstrukturiertes Datenelement wie zum Beispiel eine Videodatei verweist. Dieses unstrukturierte Element wird ein „BLOB“ oder ein „Binary Large OBject“ genannt. In den meisten Fällen ist der BLOB zu der anderen Information in der Datenzeile verlinkt, so dass er bei einer Suche nach anderen Datenelementen in dem Verzeichnis gefunden werden kann. Der BLOB selbst ist in der Regel nicht per Suche zu finden, außer möglicherweise unter seinem Namen oder Dateityps – zum Beispiel unter MP4, MOV oder WMV für Videodateien.
Was sind unstrukturierte Daten?
Wie bereits erwähnt, gehören zu den unstrukturierten Daten Formate wie Video, Audio- Dokumentdateien, Posts aus den Social Media und E-Mail-Inhalte. Sie verweigern sich einfacher Standardisierung und Kategorisierung. Sie sind oft ähnlich wie Datensammlungen und weniger als einzelne Datenelemente erkennbar – wie zum Beispiel bei gesammelten Dokumenten, die aus Hunderten oder Tausenden von Wörtern bestehen und viele verschiedene Themen adressieren.
Es ist eher schwierig, die Inhalte der Dokumente insgesamt auf einer gemeinsamen Linie zu bestimmen, und Tools für strukturierte Daten bieten oft keine Methoden, durch die Dokumente durchzugehen, um zu einer Kategorisierung der verschiedenen Inhalte zu kommen.
Neue Datenquellen wie zum Beispiel IoT-Sensoren, Satellitenbilder, mit Drohnen eingefangene Daten, Security-Kameras und Systeme für Tonaufnahme produzieren jeden Tag enorme Mengen an unstrukturierten Daten.
Unstrukturierte Daten können verwaltet werden, werden in der Regel aber als ein Object in seinem Originalzustand oder Rohformat abgespeichert und nur verändert, wenn es nötig ist. Dieser Prozess wird als „Schema-on-Read“ bezeichnet, was sich auf einen Ansatz zur Datenanalyse bezieht, der in neueren Datenverwaltungs-Tools wie Hadoop verwendet wird und den Daten beim Lesen eine Struktur verleiht.
Metadaten werden benutzt, wenn unstrukturierte Daten kategorisiert werden. Die Metadaten begleiten das Objekt und stellen eine begrenzte Menge an Standardinformationen darüber zur Verfügung, die als Kriterien für Suche und Einsortieren benutzt werden können. Aber Metadaten sind im Allgemeinen auf Basisinformationen über die Datei begrenzt, zum Beispiel darüber, wann sie erzeugt und modifiziert wurde, ihre Größe und den Dateityp.
Es gibt auch Tools, die unstrukturierte Daten wie zum Beispiel Audio- oder Videodateien scannen und Informationen herausziehen können wie Orte oder gesprochene Sätze, die als zusätzliche Metadaten verwendet werden können. In ähnlicher Weise können Technologien wie zum Beispiel XML (Extensible Markup Language) einige Strukturen zu Textdateien hinzufügen.
Während das Herausziehen oder Assoziationen mit bestimmten Informationen von unstrukturierten Daten schwierig ist, sind Methoden zu solchen Tätigkeiten dringend notwendig. Es gibt Schätzungen, dass 80 Prozent der Daten, die heute von Unternehmen erzeugt oder gesammelt werden, unstrukturiert sind. Neue Datenquellen wie zum Beispiel IoT-Sensoren, Satellitenbilder, von Drohnen eingefangene Daten, Sicherheitskameras und Sprachaufnahmegeräten produzieren jeden Tag riesige Mengen an unstrukturierten Daten. Diese großen Volumes üben Druck auf die Speichersysteme aus, so dass viele Unternehmen auf Systeme für Cloud Storage ausweichen, um ihre unstrukturierten Daten zu speichern.
Halbstrukturierte Daten
Wie die Bezeichnung nahelegt, bestehen halbstrukturierte Daten aus einer Datenmenge, die strukturierte und unstrukturierte miteinander verbindet oder –wahrscheinlicher – aus unstrukturierten Daten, denen eine gewisse Struktur angelegt wurde, um sie leichter zugänglich zu machen.
In einer einfachen Form können halbstrukturierte Daten zum Beispiel aus einer Videodatei bestehen, der strukturierte Daten hinzugefügt wurden, um mehr Details zu liefern – zu ihren Themen, Locations, Teilnehmern, Länge und Format. Jedes dieser Informationsstücke kann dann dazu genutzt werden, um Videos zu lokalisieren oder bestimmte Gruppen von Videos zu unterscheiden.
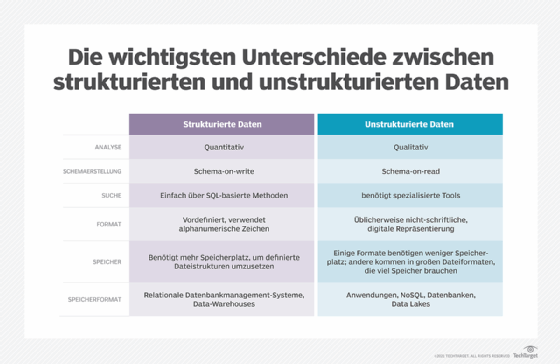
Die wichtigsten Unterschiede zwischen unstrukturierten und strukturierten Daten
Die Unterschiede zwischen strukturierten und unstrukturierten Daten sind tiefgehend, aber beide Varianten liefern wichtige Informationen für Unternehmen. Wie bereits gesagt, gibt es eine größere Bandbreite bei unstrukturierten Daten, und die Analyse-Tools, die für die Bearbeitung unstrukturierter Daten verwendet werden, sind wahrscheinlich neuer und stellen Informationen bereit, die weniger wortwörtlich zu nehmen sind als jene bei strukturierten Daten.
Zum Beispiel kann ein Supermarkt eine relationale Datenbank verwenden, um die Dinge, die ein Kunde kauft, mit seiner Kundenkarte zu verbinden und Coupons für Sachen an ihn ausgeben, die er wahrscheinlich aufgrund seines Verhaltens kaufen wird. Eine Analyse von unstrukturierten Daten in einer Retail-Umgebung könnte Videodaten verwenden, die zeigen, welche Regalreihen er besucht und wie lange und auf welche besondere Art er sich in bestimmten Bereichen aufhält. Auf Basis der gesammelten Informationen, könnte dann das System einen Gutschein für Milch produzieren, nachdem der Kunde sich bei Kaffeeangeboten aufgehalten hat und sich den Milchprodukten nähert.
Wichtigkeit von strukturierten versus unstrukturierten Daten
Strukturierte Daten tendieren zu quantitativen Informationen, während unstrukturierte Daten mehr qualitative Aussagen zur Verfügung stellen. Natürlich sind beide Arten der Datenanalyse wichtig, obwohl nicht alle Unternehmen beide einsetzen.
Wenn es zum Beispiel um neuere Datenanalysen und die Verwendung von Technologien geht, eignen sich strukturierte Daten mehr für KI-Prozesse (Künstliche Intelligenz) wie zum Beispiel maschinelles Lernen (ML).
Analysen von Big-Data- oder Data-Mining-Prozesse erfordern sehr große Datenmengen, und strukturierte Daten werden auch in diesen Fällen vorgezogen. Angesichts der großen Datenmengen von unstrukturierten Daten, die heute gesammelt werden, spielen diese jedoch auch eine Rolle bei Umgebungen von Big Data.






