Datenvorverarbeitung (Data Preprocessing)

Was ist Datenvorverarbeitung?
Die Datenvorverarbeitung (Data Preprocessing), ein Bestandteil der Datenaufbereitung, beschreibt jede Art von Verarbeitung, die an Rohdaten vorgenommen wird, um sie für ein anderes Datenverarbeitungsverfahren auszubereiten. Datenvorverarbeitung ist traditionell ein wichtiger vorbereitender Schritt für den Data-Mining-Prozess. In jüngerer Zeit wurden Datenvorverarbeitungstechniken für das Training von Machine-Learning- und KI-Modellen sowie für die Durchführung von Schlussfolgerungen anhand dieser Modelle angepasst.
Bei der Datenvorverarbeitung werden die Daten in ein Format umgewandelt, das bei Data Mining, maschinellem Lernen und anderen datenwissenschaftlichen Aufgaben einfacher und effektiver verarbeitet werden kann. Die Techniken werden im Allgemeinen in den frühesten Stadien der Entwicklungspipeline für maschinelles Lernen und KI eingesetzt, um genaue Ergebnisse zu gewährleisten.
Für die Vorverarbeitung von Daten gibt es verschiedene Tools und Methoden, darunter:
- Sampling, bei dem eine repräsentative Teilmenge aus einer großen Datenpopulation ausgewählt wird
- Transformation, bei der die Rohdaten so bearbeitet werden, dass ein einziger Input entsteht
- Rauschunterdrückung, bei der Rauschen aus den Daten entfernt wird
- Imputation, bei der statistisch relevante Daten für fehlende Werte synthetisiert werden
- Normalisierung, bei der die Daten für einen effizienteren Zugriff organisiert werden
- Merkmalsextraktion, bei der eine relevante Untergruppe von Merkmalen herausgefiltert wird, die in einem bestimmten Kontext von Bedeutung ist
Diese Tools und Methoden können für eine Vielzahl von Datenquellen verwendet werden, darunter in Dateien oder Datenbanken gespeicherte Daten und Streaming-Daten.
Warum ist Datenvorverarbeitung von Bedeutung?
Praktisch jede Art von Datenanalyse, Datenwissenschaft oder KI-Entwicklung erfordert eine Art von Datenvorverarbeitung, um zuverlässige, präzise und robuste Ergebnisse für Unternehmensanwendungen zu liefern.
Daten in der realen Welt sind unübersichtlich und werden oft von einer Vielzahl von Menschen, Geschäftsprozessen und Anwendungen erstellt, verarbeitet und gespeichert. Infolgedessen können in einem Datensatz einzelne Felder fehlen, manuelle Eingabefehler entstehen sowie doppelte Daten oder unterschiedliche Bezeichnungen für ein und dieselbe Sache vorhanden sein. Menschen können diese Probleme in den Daten, die sie für ihre Arbeit verwenden, oft erkennen und beheben, aber Daten, die zum Trainieren von Algorithmen für maschinelles Lernen oder Deep Learning verwendet werden, müssen automatisch vorverarbeitet werden.
Algorithmen für maschinelles Lernen und Deep Learning funktionieren am besten, wenn die Daten in einem Format präsentiert werden, das die relevanten Aspekte hervorhebt, die zur Lösung eines Problems erforderlich sind. Feature-Engineering-Praktiken, die Data Wrangling, Datentransformation, Datenreduktion, Feature-Auswahl und Feature-Skalierung umfassen, unterstützen bei der Umstrukturierung von Rohdaten in eine Form, die für bestimmte Arten von Algorithmen geeignet ist. Dies kann die Verarbeitungsleistung und die Zeit, die zum Trainieren eines neuen Algorithmus für maschinelles Lernen oder KI oder zur Durchführung von Schlussfolgerungen erforderlich sind, erheblich reduzieren.
Ein Punkt, der bei der Vorverarbeitung von Daten beachtet werden sollte, ist das Potenzial, Verzerrungen in den Datensatz umzucodieren. Das Erkennen und Korrigieren von Verzerrungen ist entscheidend für Anwendungen, die dabei unterstützen, Entscheidungen zu treffen, die Menschen betreffen, wie zum Beispiel Kreditgenehmigungen. Auch wenn Datenwissenschaftler Variablen wie Geschlecht oder Religion absichtlich ignorieren, können diese Merkmale mit anderen Variablen wie Postleitzahlen oder besuchten Schulen korreliert sein, was zu verzerrten Ergebnissen führt.
Die meisten modernen Data-Science-Pakete und -Dienste enthalten inzwischen verschiedene Vorverarbeitungsbibliotheken, mit denen sich viele dieser Aufgaben automatisieren lassen.
Was sind die wichtigsten Schritte bei der Datenvorverarbeitung?
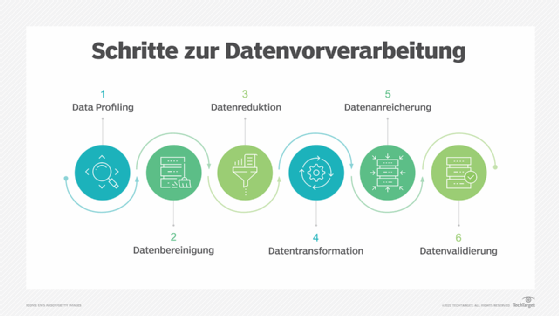
Zu den Schritten der Datenvorverarbeitung gehören:
- Data Profiling. Beim Data Profiling werden die Daten untersucht, analysiert und überprüft, um statistische Daten über ihre Qualität zu sammeln. Er beginnt mit einer Bestandsaufnahme der vorhandenen Daten und ihrer Merkmale. Datenwissenschaftler identifizieren Datensätze, die für das jeweilige Problem relevant sind, inventarisieren deren signifikante Attribute und stellen eine Hypothese über die Merkmale auf, die für die vorgeschlagene Analyse- oder Machine-Learning-Aufgabe relevant sind. Außerdem setzen sie die Datenquellen mit den relevanten Geschäftskonzepten in Beziehung und überlegen, welche Vorverarbeitungsbibliotheken verwendet werden.
- Datenbereinigung. Hier geht es darum, den einfachsten Weg zur Behebung von Qualitätsproblemen zu finden, wie zum Beispiel die Beseitigung schlechter Daten, das Ergänzen fehlender Daten oder die Sicherstellung, dass die Rohdaten für das Feature Engineering geeignet sind.
- Datenreduktion. Rohdatensätze enthalten oft redundante Daten, die sich aus der unterschiedlichen Charakterisierung von Phänomenen ergeben, oder Daten, die für eine bestimmte ML-, KI- oder Analyseaufgabe nicht relevant sind. Bei der Datenreduktion werden Techniken wie die Hauptkomponentenanalyse eingesetzt, um die Rohdaten in eine einfachere Form zu bringen, die für bestimmte Anwendungsfälle geeignet ist.
- Datentransformation. Hier denken Datenwissenschaftler darüber nach, wie verschiedene Aspekte der Daten organisiert werden müssen, um für das Ziel am sinnvollsten zu sein. Dies können Dinge wie die Strukturierung unstrukturierter Daten, die Kombination auffälliger Variablen, wenn dies sinnvoll ist, oder die Identifizierung wichtiger Bereiche, auf die man sich konzentrieren sollte, umfassen.
- Datenanreicherung. In diesem Schritt wenden die Datenwissenschaftler die verschiedenen Feature-Engineering-Bibliotheken auf die Daten an, um die gewünschten Transformationen durchzuführen. Das Ergebnis sollte ein Datensatz sein, der so organisiert ist, dass ein optimales Gleichgewicht zwischen der Trainingszeit für ein neues Modell und der erforderlichen Rechenleistung erreicht wird.
- Validierung der Daten. In dieser Phase werden die Daten in zwei Sätze aufgeteilt. Der erste Satz wird zum Trainieren eines Modells für maschinelles Lernen oder Deep Learning verwendet. Der zweite Satz sind die Testdaten, die verwendet werden, um die Genauigkeit und Robustheit des resultierenden Modells zu beurteilen. Dieser zweite Schritt hilft bei der Identifizierung von Problemen mit den Hypothesen, die bei der Bereinigung und dem Feature Engineering der Daten verwendet wurden. Wenn die Datenwissenschaftler mit den Ergebnissen zufrieden sind, können sie die Vorverarbeitungsaufgabe an einen Dateningenieur weitergeben, der herausfindet, wie sie für die Produktion skaliert werden kann. Ist dies nicht der Fall, können die Datenwissenschaftler zurückgehen und Änderungen an der Art und Weise vornehmen, wie sie die Schritte der Datenbereinigung und des Feature Engineering implementiert haben.
Welche Techniken der Datenvorverarbeitung gibt es?
Es gibt zwei Hauptkategorien der Vorverarbeitung: Datenbereinigung und Feature Engineering. Jede Kategorie umfasst eine Vielzahl von Techniken, die im Folgenden näher erläutert werden.
Datenbereinigung
Zu den Techniken zur Bereinigung nicht geordneter Daten gehören:
Identifizieren und Aussortieren fehlender Daten. Es gibt eine Vielzahl von Gründen, warum in einem Datensatz einzelne Datenfelder fehlen können. Datenwissenschaftler müssen entscheiden, ob es besser ist, Datensätze mit fehlenden Feldern zu verwerfen, sie zu ignorieren oder sie mit einem wahrscheinlichen Wert aufzufüllen. Bei einer IoT-Anwendung, die die Temperatur aufzeichnet, kann es beispielsweise eine sichere Lösung sein, eine fehlende Durchschnittstemperatur zwischen dem vorherigen und dem nachfolgenden Datensatz zu ergänzen.
Datenrauschen reduzieren. Daten aus der realen Welt sind oft verrauscht, was ein analytisches oder KI-Modell verzerren kann. So kann beispielsweise ein Temperatursensor, der durchgängig eine Temperatur von 35 Grad Celsius meldet, fälschlicherweise eine Temperatur von 100 Grad Celsius melden. Zur Verringerung des Rauschens können verschiedene statistische Ansätze verwendet werden, darunter Binning, Regression und Clustering.
Identifizieren und Entfernen von Duplikaten. Wenn sich zwei Datensätze zu wiederholen scheinen, muss ein Algorithmus feststellen, ob dieselbe Messung zweimal aufgezeichnet wurde oder ob die Datensätze unterschiedliche Ereignisse darstellen. In manchen Fällen kann ein Datensatz geringfügige Unterschiede aufweisen, weil ein Feld falsch erfasst wurde. In anderen Fällen können Datensätze, die Duplikate zu sein scheinen, tatsächlich unterschiedlich sein, wie zum Beispiel bei einem Vater und einem Sohn mit demselben Namen, die im selben Haus leben, aber als getrennte Personen dargestellt werden sollten. Techniken zum Erkennen und Entfernen oder Zusammenführen von Duplikaten können helfen, diese Art von Problemen automatisch zu lösen.
Feature Engineering
Wie bereits erwähnt, umfasst das Feature Engineering Techniken, die von Datenwissenschaftlern eingesetzt werden, um die Daten so zu organisieren, dass das Trainieren von Datenmodellen und die Durchführung von Schlussfolgerungen anhand dieser Modelle effizienter wird. Zu diesen Techniken gehören:
Skalierung oder Normalisierung von Merkmalen. Oft ändern sich mehrere Variablen auf unterschiedlichen Skalen, oder eine ändert sich linear, während eine andere sich exponentiell ändert. Beispielsweise kann das Gehalt in Tausend Euro gemessen werden, während das Alter in zweistelligen Zahlen dargestellt wird. Die Skalierung unterstützt dabei, die Daten so umzuwandeln, dass es für Algorithmen einfacher ist, eine sinnvolle Beziehung zwischen den Variablen herauszufinden.
Datenreduktion. Datenwissenschaftler müssen oft eine Vielzahl von Datenquellen kombinieren, um ein neues KI- oder Analysemodell zu erstellen. Einige der Variablen sind möglicherweise nicht mit einem bestimmten Ergebnis korreliert und können verworfen werden. Andere Variablen könnten relevant sein, aber nur in Bezug auf die Beziehung, wie zum Beispiel das Verhältnis von Schulden zu Krediten im Falle eines Modells, das die Wahrscheinlichkeit einer Kreditrückzahlung vorhersagt. Sie können zu einer einzigen Variable kombiniert werden. Techniken wie die Hauptkomponentenanalyse spielen eine Schlüsselrolle bei der Reduzierung der Anzahl von Dimensionen im Trainingsdatensatz auf eine effizientere Darstellung.
Diskretisierung. Oft ist es sinnvoll, rohe Zahlen in diskrete Intervalle zu gliedern. Beispielsweise kann das Einkommen in fünf Bereiche unterteilt werden, die repräsentativ für Personen sind, die typischerweise eine bestimmte Art von Kredit beantragen. Dadurch lässt sich der Aufwand für das Training eines Modells oder die Durchführung von Schlussfolgerungen reduzieren.
Kodierung von Merkmalen. Ein weiterer Aspekt des Feature Engineerings ist die Organisation unstrukturierter Daten in einem strukturierten Format. Zu den unstrukturierten Datenformaten können Text, Audio und Video gehören. Der Prozess der Entwicklung von Algorithmen zur Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) beginnt beispielsweise in der Regel mit der Verwendung von Datentransformationsalgorithmen wie Word2vec, um Wörter in numerische Vektoren zu übersetzen. Auf diese Weise lässt sich dem Algorithmus leicht vermitteln, dass Wörter wie Post und Paket ähnlich sind, während ein Wort wie Haus etwas völlig anderes ist. In ähnlicher Weise kann ein Algorithmus zur Gesichtserkennung rohe Pixeldaten in Vektoren umcodieren, die die Abstände zwischen Teilen des Gesichts darstellen.
Wie wird Datenvorverarbeitung eingesetzt?
Wie bereits erwähnt, spielt Datenvorverarbeitung in früheren Phasen des maschinellen Lernens und der Entwicklung von KI-Anwendungen eine wichtige Rolle. In einem KI-Kontext wird die Datenvorverarbeitung verwendet, um die Art und Weise zu verbessern, wie Daten bereinigt, umgewandelt und strukturiert werden, um die Genauigkeit eines neuen Modells zu verbessern und gleichzeitig den erforderlichen Rechenaufwand zu verringern.
Eine gute Datenvorverarbeitungspipeline kann wiederverwendbare Komponenten erstellen, die das Testen verschiedener Ideen zur Rationalisierung von Geschäftsprozessen oder zur Verbesserung der Kundenzufriedenheit erleichtern. So kann die Vorverarbeitung beispielsweise die Datenorganisation für eine Empfehlungsmaschine verbessern, indem die zur Kategorisierung der Kunden verwendeten Altersbereiche optimiert werden.

Die Vorverarbeitung kann auch die Erstellung und Änderung von Daten vereinfachen, um genauere und gezieltere Einblicke in die Geschäftsinformationen zu erhalten. Beispielsweise können Kunden unterschiedlicher Größe, Kategorie oder Region ein unterschiedliches Verhalten in verschiedenen Regionen zeigen. Die Vorverarbeitung der Daten in die entsprechenden Formen kann BI-Teams dabei unterstützen, diese Erkenntnisse in BI-Dashboards einzubinden.
Im Kontext des Customer Relationship Management (CRM) ist die Datenvorverarbeitung eine Komponente des Web Mining. Webnutzungsprotokolle können vorverarbeitet werden, um aussagekräftige Datensätze, so genannte Benutzertransaktionen, zu extrahieren, die aus Gruppen von URL-Verweisen bestehen. Benutzersitzungen können nachverfolgt werden, um den Benutzer, die angeforderten Websites und deren Reihenfolge sowie die Dauer der einzelnen Sitzungen zu identifizieren. Sobald diese Daten aus den Rohdaten extrahiert wurden, liefern sie nützlichere Informationen, die zum Beispiel für die Verbraucherforschung, das Marketing oder die Personalisierung verwendet werden können.







