Datenbank
Was ist eine Datenbank (DB)?
Eine Datenbank dient dem Zugriff, der Verwaltung und Aktualisierung von Informationen. In Computerdatenbanken werden in der Regel Zusammenstellungen von Datensätzen oder Dateien gespeichert, die Informationen wie Verkaufstransaktionen, Kundendaten, Finanzdaten und Produktinformationen enthalten. Mit Datenbanken können Unternehmen schnell auf ihre Daten zugreifen, sie verwalten, ändern, aktualisieren, organisieren und wiederfinden.
Datenbanken werden zum Speichern, Verwalten und Abrufen jeglicher Art von Daten verwendet. Sie sammeln Informationen über Personen, Orte oder Dinge. Diese Informationen werden an einem Ort gesammelt, damit sie beobachtet und analysiert werden können. Datenbanken können als eine organisierte Sammlung von Informationen betrachtet werden.
Datenbanken werden normalerweise mit einem Datenbankmanagementsystem (DBMS) verwaltet. In der Datenbank werden die Daten in Tabellen organisiert, die aus Zeilen und Spalten bestehen. Viele Datenbanken verwenden auch die Structured Query Language (SQL) zum Schreiben und Abfragen von Daten. Es gibt jedoch verschiedene Arten von Datenbanken, so dass die verwendete Sprache und ihre Funktionsweise von der Art der Datenbank abhängen.
Wofür werden Datenbanken verwendet?
In Wirtschaft, Verwaltung und Wissenschaft werden Datenbanken für die Speicherung, Analyse und Verwaltung von Daten verwendet. Unternehmen nutzen die in Datenbanken gespeicherten Daten, um fundierte Geschäftsentscheidungen zu treffen. Unternehmen nutzen Datenbanken unter anderem für folgende Zwecke:
- Verbesserung von Geschäftsprozessen. Unternehmen sammeln Daten über Geschäftsprozesse, wie zum Beispiel Verkauf, Auftragsabwicklung und Kundendienst. Sie analysieren diese Daten, um diese Prozesse zu verbessern, ihr Geschäft zu erweitern und den Umsatz zu steigern.
- Überblick über Kunden. In Datenbanken werden häufig Informationen über Personen gespeichert, zum Beispiel über Kunden oder Nutzer. So verwenden beispielsweise Plattformen für soziale Medien Datenbanken, um Nutzerdaten wie Namen, E-Mail-Adressen und Nutzerverhalten zu speichern. Diese Daten werden verwendet, um den Nutzern Inhalte zu empfehlen und das Nutzererlebnis zu verbessern.
- Sichere persönliche Gesundheitsinformationen. Gesundheitsdienstleister verwenden Datenbanken, um persönliche Gesundheitsdaten sicher zu speichern, um die Patientenversorgung zu informieren und zu verbessern.
- Persönliche Daten speichern. Datenbanken können auch zum Speichern persönlicher Daten verwendet werden. So können einzelne Nutzer beispielsweise Medien wie Fotos in einer verwalteten Cloud speichern.
Arten von Datenbanken
Es gibt viele Arten von Datenbanken. Sie werden nach ihrem Inhaltstyp klassifiziert: bibliografisch, Volltext, numerisch und Bilder. In der Datenverarbeitung werden Datenbanken oft nach ihrem organisatorischen Ansatz klassifiziert.
Einige der wichtigsten organisatorischen Datenbanken sind die folgenden.
Relationale Datenbank
Bei diesem tabellarischen Ansatz werden die Daten so definiert, dass sie auf verschiedene Weise reorganisiert und abgerufen werden können. Relationale Datenbanken bestehen aus Tabellen, in denen die Daten in vordefinierte Kategorien eingeordnet werden. Jede Tabelle hat Spalten mit mindestens einer Datenkategorie und Zeilen mit einer bestimmten Dateninstanz für die Kategorien, die in den Spalten definiert sind. Die Informationen über einen bestimmten Kunden in einer relationalen Datenbank sind in Zeilen, Spalten und Tabellen organisiert. Diese sind indiziert, um die Suche mit SQL- oder NoSQL-Abfragen zu erleichtern.
Relationale Datenbanken verwenden SQL in ihren Benutzer- und Programmierschnittstellen (API). Eine neue Datenkategorie kann leicht zu einer relationalen Datenbank hinzugefügt werden, ohne dass die bestehenden Anwendungen geändert werden müssen. Ein relationales Datenbankmanagementsystem (RDBMS) wird zum Speichern, Verwalten, Abfragen und Abrufen von Daten in einer relationalen Datenbank verwendet.
In der Regel bietet das RDBMS den Benutzern die Möglichkeit, den Lese-/Schreibzugriff zu steuern, die Erstellung von Berichten zu spezifizieren und die Verwendung zu analysieren. Einige Datenbanken bieten Atomarität, Konsistenz, Isolation und Dauerhaftigkeit – bekannt als ACID/AKID – um zu garantieren, dass die Daten konsistent und die Transaktionen vollständig sind.
Verteilte Datenbank
Diese Datenbank speichert Datensätze oder Dateien an mehreren physischen Orten. Auch die Datenverarbeitung ist über verschiedene Teile des Netzwerks verteilt und repliziert. Verteilte Datenbanken können homogen sein, das heißt alle physischen Standorte verfügen über dieselbe zugrunde liegende Hardware und führen dieselben Betriebssysteme und Datenbankanwendungen aus. Sie können aber auch heterogen sein. In diesen Fällen können die Hardware, das Betriebssystem und die Datenbankanwendungen an den verschiedenen Standorten unterschiedlich sein.
Cloud-Datenbank
Cloud-Datenbanken werden in einer öffentlichen, privaten oder hybriden Cloud für eine virtualisierte Umgebung erstellt. Die Abrechnung erfolgt nach dem Speicher- und Bandbreitenverbrauch. Außerdem erhalten sie Skalierbarkeit nach Bedarf und hohe Verfügbarkeit. Diese Datenbanken können mit Anwendungen arbeiten, die als Software as a Service bereitgestellt werden. Das As-a-Service-Angebot wird in der Regel als Database as a Service oder DBaaS bezeichnet.
NoSQL
NoSQL-Datenbanken eignen sich gut für den Umgang mit großen verteilten Datensammlungen. Sie können Leistungsprobleme von Big Data besser lösen als relationale Datenbanken. Sie eignen sich auch gut für die Analyse großer unstrukturierter Datensätze und von Daten auf virtuellen Servern in der Cloud. Diese Datenbanken können auch als nicht-relationale Datenbanken bezeichnet werden.
Objektorientierte Datenbank
Objektorientierte Datenbanken enthalten Daten, die mit objektorientierten Programmiersprachen erstellt wurden. Sie konzentrieren sich auf die Organisation von Objekten und nicht von Aktionen und Daten und nicht von Logik. Ein Bilddatensatz zum Beispiel ist ein Datenobjekt und kein alphanumerischer Wert.
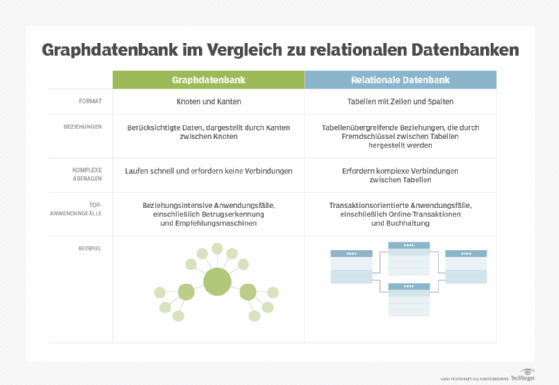
Graphdatenbank
Diese Datenbanken sind eine Art von NoSQL-Datenbank. Sie speichern, bilden ab und fragen Beziehungen ab, indem sie Konzepte aus der Graphentheorie verwenden. Graphdatenbanken bestehen aus Knoten und Kanten. Knoten sind Entitäten, die die Knoten miteinander verbinden. Diese Datenbanken werden häufig zur Analyse von Zusammenhängen verwendet. Graphdatenbanken werden häufig zur Analyse von Daten über Kunden verwendet, die auf Webseiten und in sozialen Medien mit einem Unternehmen interagieren.
Graphdatenbanken verwenden die deklarative Programmiersprache SPARQL und das Protokoll für Analysen. SPARQL kann die gleichen Analysen wie SQL durchführen, kann aber auch für semantische Analysen – oder die Untersuchung von Beziehungen – verwendet werden. Dies macht es nützlich für die Analyse von Datensätzen, die sowohl strukturierte als auch unstrukturierte Daten enthalten. SPARQL ermöglicht die Analyse von Informationen, die in einer relationalen Datenbank gespeichert sind, sowie die Analyse von Freundschaftsbeziehungen, PageRank und kürzesten Pfaden.
Multimodell-Datenbank
Eine Multimodell-Datenbank unterstützt mehrere Datenmodelle, die die Parameter dafür festlegen, wie die Informationen in einer Datenbank organisiert und angeordnet sind. Multimodell-Datenbanken ermöglichen es IT-Teams, verschiedene Anwendungsanforderungen zu erfüllen, ohne verschiedene Datenbanksysteme einsetzen zu müssen. So können Multimodell-Datenbanken beispielsweise Datenmodelle wie relationale, hierarchische, Objekt-, Graph- und NoSQL-Datenbanken verwenden.
Autonome Datenbank
Eine autonome Datenbank ist eine neuere Art von Datenbank, die regelmäßige Datenverwaltungsaufgaben wie Backups, Aktualisierungen, Tuning und Sicherheit automatisiert. Diese Datenbanken sind Cloud-basiert und nutzen maschinelle Lernprozesse für ihre Automatisierung. Autonome Datenbanken erfordern nur ein minimales menschliches Eingreifen, um den täglichen Betrieb zu bewältigen. Dadurch verringert sich der Zeitaufwand für Datenbankadministratoren bei der Verwaltung einer Datenbank.
Data Warehouse
Hierbei handelt es sich um ein Repository von Daten aus den operativen Systemen eines Unternehmens und anderen Quellen. Data Warehouses sind in der Regel für schnelle Abfragen und Analysen konzipiert. In der Regel handelt es sich bei einem Data Warehouse um eine relationale Datenbank, die sich entweder vor Ort im Rechenzentrum oder in der Cloud befindet.
Was sind die Komponenten einer Datenbank?
Die verschiedenen Datenbanktypen unterscheiden sich zwar in Bezug auf Schema, Datenstruktur und die für sie am besten geeigneten Datentypen, aber sie bestehen alle aus den folgenden fünf Grundkomponenten:
- Hardware. Dies ist das physische Gerät, auf dem die Datenbanksoftware läuft. Zur Datenbankhardware gehören Computer, Server und Festplatten.
- Software. Datenbanksoftware oder Anwendungen geben den Benutzern die Kontrolle über die Datenbank. DBMS-Software wird zur Verwaltung und Steuerung von Datenbanken verwendet.
- Daten. Dies sind die Rohdaten, die in der Datenbank gespeichert sind. Datenbankmanager organisieren die Daten, um sie aussagekräftiger zu machen.
- Datenzugriffssprache. Dies ist die Programmiersprache, die die Datenbank steuert. Die Programmiersprache und das DBMS müssen zusammenarbeiten. Eine der gebräuchlichsten Datenbanksprachen ist SQL.
- Prozeduren. Diese Regeln bestimmen, wie die Datenbank arbeitet und wie sie die Daten verarbeitet.
Was sind die Herausforderungen beim Datenbankeinsatz?
Die Einrichtung, der Betrieb und die Wartung einer Datenbank sind mit allgemeinen Herausforderungen verbunden, wie zum Beispiel den folgenden:
- Datensicherheit ist erforderlich, da Daten ein wertvolles Unternehmensgut sind. Der Schutz von Datenspeichern erfordert qualifiziertes Personal für Cybersicherheit, was kostspielig sein kann.
- Die Datenintegrität gewährleistet, dass die Daten vertrauenswürdig sind. Es ist nicht immer einfach, Datenintegrität zu erreichen, da dies bedeutet, dass der Zugang zu Datenbanken auf die Personen beschränkt werden muss, die für die Bearbeitung qualifiziert sind.
- Die Leistung von Datenbanken erfordert regelmäßige Datenbankaktualisierungen und -wartung. Ohne die richtige Unterstützung kann die Datenbankfunktionalität abnehmen, wenn sich die Technologie, die die Datenbank unterstützt, oder die darin enthaltenen Daten ändern.
- Auch die Datenbankintegration kann schwierig sein. Sie kann die Integration von Datenquellen aus verschiedenen Arten von Datenbanken und Strukturen in eine einzige Datenbank oder in Data Lakes und Data Warehouses beinhalten.
- Skalierbarkeit ist bei lokalen Datenbanken schwierig. Es ist eine Herausforderung, die benötigte Kapazität vorherzusagen. Bei Cloud-basierten Datenbanken stellt sich dieses Problem nicht in demselben Maße.
Was ist ein Datenbankmanagementsystem (DBMS)?
Ein DBMS ist eine Software, mit der Benutzer eine Datenbank erstellen und verwalten können. Es unterstützt sie auch, Daten in einer Datenbank zu erstellen, zu lesen, zu aktualisieren und zu löschen, und es unterstützt sie bei Protokollierungs- und Prüfungsfunktionen.
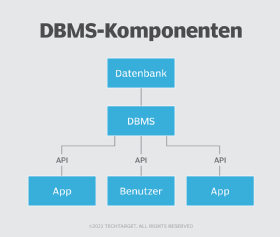
Ein DBMS bietet physische und logische Unabhängigkeit von Daten. Benutzer und Anwendungen müssen weder den physischen noch den logischen Speicherort der Daten kennen. Ein DBMS kann auch den Zugriff auf die Datenbank beschränken und kontrollieren und mehreren Benutzern unterschiedliche Ansichten desselben Datenbankschemas zur Verfügung stellen. Einige Beispiele für DBMS sind Microsoft SQL Server, MySQL und Oracle Database.
Entwicklung von Datenbanken
Datenbanken wurden erstmals in den 1960er Jahren entwickelt. Diese frühen Datenbanken waren Netzwerkmodelle, bei denen jeder Datensatz mit vielen primären und sekundären Datensätzen verbunden ist. Hierarchische Datenbanken gehörten ebenfalls zu den frühen Modellen. Sie haben Baumschemata mit einem Stammverzeichnis von Datensätzen, die mit mehreren Unterverzeichnissen verknüpft sind.
Relationale Datenbanken wurden in den 1970er Jahren entwickelt und wurden im folgenden Jahrzehnt immer beliebter. E.F. Codd entwarf das Konzept der relationalen Datenbank in den 1970er Jahren während seiner Tätigkeit bei IBM. Sie wurde aufgrund ihres logischen Schemas, also der Art und Weise, wie sie organisiert ist, zum Standard für Datenbanksysteme. Die Verwendung eines logischen Schemas trennt die relationale Datenbank von der physischen Speicherung.
Die relationale Datenbank führte in Verbindung mit dem Wachstum des Internets ab Mitte der 1990er Jahre zu einer starken Verbreitung von Datenbanken, auf die sich viele Geschäfts- und Verbraucheranwendungen stützten.
In den 1990er Jahren kamen objektorientierte Datenbanken hinzu. Dieser Datenbanktyp ermöglicht es den Benutzern, Daten mit komplexen Beziehungen schnell abzufragen. Heute verwenden wir SQL, NoSQL, Cloud- und autonome Datenbanken.
Was ist die Zukunft der Datenbanken?
Die Technologie von Datenbanken hat sich seit der Entwicklung von Netzwerk- und hierarchischen Datenbanken in den 1960er Jahren verändert. Die meisten Datenbanken gehören heute zu den SQL-, NoSQL- und Cloud-Varianten. Aber auch selbststeuernde Datenbanken sind mit Diensten wie Oracle Autonomous Database auf dem Vormarsch.
Mit dem Aufkommen autonomer Datenbanken wird auch ein potenzieller Zukunftstrend bei Datenbanken eingeführt. Es handelt sich dabei um die Einbeziehung von künstlicher Intelligenz und maschinellem Lernen zur Verwaltung und Optimierung der Datenbankleistung. Diese Tools sind so konzipiert, dass sie in Datenbanken eingesetzt werden können, um die Notwendigkeit der manuellen Pflege durch Datenbankadministratoren zu minimieren. Sie sind in der Lage, zahlreiche Datenmanagementaufgaben zu übernehmen.
Ein weiterer Trend sind Cloud-native Datenbanken, das heißt Datenbanken, die von Grund auf für den Betrieb in der Cloud entwickelt wurden. Dieser Datenbanktyp ist widerstandsfähiger, auf die verteilte Natur der Cloud abgestimmt und kann die Leistung optimieren und Ressourcen effizienter verwalten.
Datenbanken werden auch eher ein höheres Maß an Datensicherheit aufweisen, da dies für Unternehmen, die ihre Datenbank in die Cloud verlagern, ein immer wichtigerer Faktor wird. Cloud-Datenbanken sind häufig mit Bedrohungen konfrontiert, wie zum Beispiel ungeschützte APIs, Workload-Hijacking, Offenlegung von Daten und andere Angriffe. Viele Cloud-Datenbankdienste verfügen über Sicherheitsfunktionen wie automatische Backups, Datenverschlüsselung, Identitäts- und Zugriffsmanagement und rollenbasierten Zugriff.






