Datenaufbereitung (Data Preparation)

Was ist Datenaufbereitung (Data Preparation)?
Bei der Datenaufbereitung und -vorbereitung (Data Preparation) werden Daten gesammelt, kombiniert, strukturiert und organisiert. Das Ziel dieses Prozesses ist, die Daten in Business-Intelligence-, Analyse- und Visualisierungsanwendungen nutzen zu können. Zu den Komponenten der Datenaufbereitung gehören Datenvorverarbeitung (Data Preprocessing), Datenprofilerstellung (Data Profiling), Datenbereinigung (Cleansing), Datenvalidierung und Datentransformation. Häufig werden bei der Datenaufbereitung auch Daten aus verschiedenen internen Systemen und externen Quellen zusammengeführt.
Datenaufbereitung ist Teil der Arbeit von IT-, BI- und Datenmanagement-Teams. Dies erfolgt in der Regel, wenn sie Datensätze integrieren, um sie in ein Data Warehouse, eine NoSQL-Datenbank oder ein Data Lake Repository zu laden. Daten werden auch aufbereitet, wenn neue Analyseanwendungen mit diesen Datensätzen entwickelt werden sollen. Darüber hinaus verwenden Data Scientists, Data Engineers, Datenanalysten und Geschäftsanwender zunehmend Self-Service-Tools zur Datenaufbereitung, um selbst Daten zu sammeln, aufzubereiten und zu analysieren.
Die Datenaufbereitung wird oft informell als Data Prep (von Data Preparation) bezeichnet. Manche verwenden auch den Begriff Data Wrangling, allerdings nutzen einige Anwender diesen Begriff im engeren, spezifischeren Sinne. Sie beziehen sich damit auf das Bereinigen, Strukturieren und Transformieren von Daten. Diese Verwendung unterscheidet Data Wrangling von der Phase der Datenvorverarbeitung.
Dieser Leitfaden erläutert genauer, was Datenaufbereitung ist. Er zeigt, wie man bei der Vorbereitung der Daten vorgeht und welche Vorteile dies für Unternehmen bietet. Außerdem finden Sie Informationen zu Tools für die Datenaufbereitung und Tool-Anbietern, Best Practices und allgemeinen Herausforderungen bei der Datenaufbereitung.
Warum ist Datenaufbereitung wichtig?
Einer der Hauptzwecke der Datenaufbereitung besteht darin, sicherzustellen, dass die Rohdaten, die für die Verarbeitung und Analyse vorbereitet werden, genau und konsistent sind. Andernfalls sind die Ergebnisse der BI- und Analyseanwendungen nicht valide. Gründe für eine schlechte Datenqualität gibt es viele: Beispielsweise fehlen bei Datensätzen häufig Werte, die Daten sind ungenau oder haben andere Fehler, und getrennte Datensätze liegen in der Regel in unterschiedlichen Formaten vor, die bei der Kombination erst abgeglichen werden müssen. Das Korrigieren von Datenfehlern, das Validieren der Datenqualität und das Konsolidieren von Datensätzen sind wichtige Bestandteile von Projekten zur Datenaufbereitung.
Die Datenaufbereitung umfasst auch das Auffinden relevanter Daten für den behandelten Bereich. Damit soll sichergestellt werden, dass die Analyseanwendungen aussagekräftige Informationen und verwertbare Erkenntnisse für die Entscheidungsfindung liefern. Um die Daten informativer und nützlicher zu machen, werden sie häufig angereichert und optimiert. Dies erfolgt beispielsweise durch das Zusammenführen interner und externer Datensätze, das Erstellen neuer Datenfelder, sowie das Beseitigen von Ausreißerwerten und unausgewogenen Datensätzen, die die Analyseergebnisse verfälschen können.
Darüber hinaus nutzen BI- und Datenmanagement-Teams den Prozess der Datenaufbereitung, um Datensätze für die Analyse durch Geschäftsanwender auszuwählen. Dies trägt dazu bei, die Self-Service-BI-Anwendungen für Geschäftsanalysten, Führungskräfte und Mitarbeiter zu optimieren und zu steuern.
Was sind die Vorteile der Datenaufbereitung?
Datenwissenschaftler beklagen oft, dass sie die meiste Zeit mit dem Sammeln, Bereinigen und Strukturieren von Daten verbringen, anstatt ihrer eigentlichen Aufgabe nachzugehen: Die Daten zu analysieren. Ein großer Vorteil eines effektiven Datenaufbereitungsprozesses besteht in der Tat darin, dass sich Data Scientists und andere Fachleute mehr auf Data Mining und Datenanalyse konzentrieren können – die Bereiche ihrer Arbeit, die einen geschäftlichen Mehrwert schaffen. Beispielsweise kann die Datenaufbereitung schneller erfolgen, und die aufbereiteten Daten können automatisch an die Benutzer für wiederkehrende Analyse-Anwendungen weitergeleitet werden.
Richtig durchgeführt, unterstützt Datenaufbereitung auch bei folgenden Aufgaben:
- Sicherstellen, dass die in Analyse-Anwendungen verwendeten Daten zuverlässige Ergebnisse liefern.
- Identifizieren und Beheben von Datenproblemen, die andernfalls möglicherweise nicht erkannt werden.
- Fundiertere Entscheidungsfindung durch Führungskräfte und operative Mitarbeiter.
- Reduzierung der Kosten für Datenmanagement und -analyse.
- Vermeidung von Doppelarbeit bei der Aufbereitung von Daten für die Verwendung in mehreren Anwendungen.
- Erzielung eines höheren ROI aus BI- und Analyse-Initiativen.
Eine effektive Datenaufbereitung ist besonders in Big-Data-Umgebungen von Vorteil, in denen eine Kombination aus strukturierten, semistrukturierten und unstrukturierten Daten verwendet wird. Diese Daten werden oft in Rohform gespeichert, bis sie für bestimmte Analysezwecke benötigt werden. Zu diesen Verwendungszwecken gehören prädiktive Analysen, maschinelles Lernen (ML) und andere Formen von Advanced Analytics. Gemeinsam ist diesen Anwendungen, dass sie in der Regel die Aufbereitung großer Datenmengen erfordern.
Schritte im Datenaufbereitungsprozess
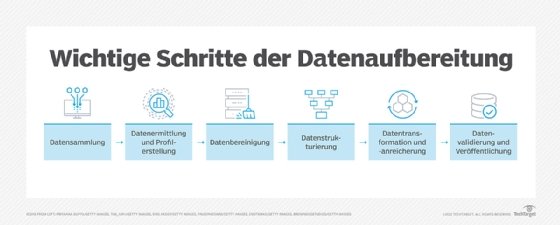
Datenaufbereitung erfolgt in mehreren Schritten. Die von verschiedenen Datenexperten und Softwareanbietern vorgeschlagenen Schritte zur Datenaufbereitung variieren etwas, doch in der Regel umfasst der Prozess folgende Aufgaben:
1. Datensammlung.
Relevante Daten werden aus operativen Systemen, Data Warehouses, Data Lakes und anderen Datenquellen gesammelt. In diesem Schritt sollten alle Mitarbeiter, die Daten sammeln, zum Beispiel Data Scientists, Mitglieder des BI-Teams, andere Datenexperten und Endanwendern, bestätigen, dass diese Daten für die Ziele der geplanten Analyse-Anwendungen geeignet sind.
2. Datenermittlung und Datenprofilerstellung
Der nächste Schritt besteht darin, die gesammelten Daten genauer zu untersuchen. Das Ziel dabei ist, besser zu verstehen, was die Datensätze enthalten, und was getan werden muss, um sie für die beabsichtigten Zwecke vorzubereiten. Zu diesem Zweck werden im Rahmen der Datenprofilerstellung Muster, Beziehungen und andere Attribute in den Daten identifiziert sowie Inkonsistenzen, Anomalien, fehlende Werte und andere Probleme gesucht, damit sie behoben werden können.
3. Datenbereinigung
Als nächstes werden die festgestellten Datenfehler und Probleme korrigiert, um vollständige und genaue Datensätze zu erhalten. Im Rahmen der Bereinigung von Datensätzen werden beispielsweise fehlerhafte Daten entfernt oder korrigiert, fehlende Werte ergänzt und inkonsistente Einträge abgeglichen.
4. Datenstrukturierung
An diesem Punkt müssen die Daten modelliert und strukturiert werden, damit sie den Analyse-Anforderungen entsprechen. Beispielsweise müssen Daten, die in CSV-Dateien (Comma-Separated Values) oder anderen Dateiformaten gespeichert sind, in Tabellen umgewandelt werden, damit sie für BI- und Analyse-Tools zugänglich sind.
5. Datentransformierung und -anreicherung
Die Daten müssen nicht nur strukturiert, sondern meist auch in ein einheitliches und anwendbares Format umgewandelt werden. Die Datentransformation kann zum Beispiel die Erstellung neuer Felder oder Spalten notwendig machen, die Werte aus bestehenden Feldern aggregieren. Bei der Datenanreicherung werden die Datensätze je nach Bedarf durch Maßnahmen wie das Erweitern und Hinzufügen von Daten verbessert und optimiert.
6. Datenvalidierung und Veröffentlichung
Im letzten Schritt werden automatisierte Routinen mit den Daten durchgeführt. Diese überprüfen ihre Konsistenz, Vollständigkeit und Genauigkeit. Die aufbereiteten Daten sollten dann in einem Data Warehouse, einem Data Lake oder einem anderen Repository gespeichert werden. Von dort lassen sie sich entweder direkt von den Mitarbeitern einsetzen, die sie aufbereitet haben, oder von anderen Benutzern, die mit den Daten arbeiten wollen.
Die Datenaufbereitung kann auch in die Datenkuratierung einfließen, bei der gebrauchsfertige Datensätze für BI und Analysen erstellt und überwacht werden. Datenkuratierung umfasst unter anderem die Indizierung, Katalogisierung und Pflege von Datensätzen und den dazugehörigen Metadaten. Auf diese Weise will man den Benutzern das Auffinden und den Zugriff auf die Daten erleichtern. In einigen Unternehmen ist der Datenkurator eine formelle Rolle, die in Zusammenarbeit mit Datenwissenschaftlern, Geschäftsanalysten, anderen Geschäftsanwendern sowie den IT- und Datenmanagementteams ausgeübt wird. In anderen Unternehmen werden die Daten von Datenmanagern oder Datenadministratoren (Data Stewards), Dateningenieuren, Datenbankadministratoren, Datenwissenschaftlern und Geschäftsanwendern selbst kuratiert.
Was sind die Herausforderungen bei der Datenaufbereitung?
Datenaufbereitung ist von Natur aus kompliziert. Datensätze, die aus verschiedenen Quellsystemen zusammengeführt werden, haben mit großer Wahrscheinlichkeit zahlreiche Probleme bei der Datenqualität, -genauigkeit und -konsistenz. Diese gilt es zu lösen. Außerdem müssen die Daten bearbeitet werden, um sie nutzbar zu machen, und irrelevante Daten müssen aussortiert werden.
Wie bereits erwähnt, ist dies ein zeitaufwendiger Prozess: Bei Analyse-Anwendungen wird häufig die 80/20-Regel angewandt, wonach etwa 80 Prozent der Arbeit auf das Sammeln und Aufbereiten von Daten und nur 20 Prozent auf deren Analyse entfallen.
Dies sind die sieben größten Herausforderungen bei der Datenaufbereitung:
- Unzureichende oder nicht vorhandene Datenprofilerstellung. Wenn die Datenprofile nicht korrekt sind, werden Fehler, Anomalien und andere Probleme möglicherweise nicht erkannt, was zu fehlerhaften Analysen führen kann.
- Fehlende oder unvollständige Daten. Datensätze enthalten oft fehlende Werte und andere Formen von unvollständigen Daten; solche Probleme müssen als mögliche Fehler bewertet und gegebenenfalls behoben werden.
- Ungültige Datenwerte. Rechtschreibfehler, Tippfehler und falsche Zahlen sind Beispiele für ungültige Einträge, die häufig in Daten vorkommen und behoben werden müssen, um die Genauigkeit der Analysen zu gewährleisten.
- Standardisierung von Namen und Adressen. Namen und Adressen können aus verschiedenen Systemen stammen, und in der Folge inkonsistent sein und Abweichungen aufweisen; dies kann sich auf die Präsentation von Kunden und anderen geschäftlichen Akteuren auswirken.
- Inkonsistente Daten in Unternehmenssystemen. Andere Inkonsistenzen in Datensätzen, die aus verschiedenen Quellsystemen stammen, sind zum Beispiel unterschiedliche Terminologien und IDs; dies ist ebenfalls ein weit verbreitetes Problem bei der Datenaufbereitung.
- Datenanreicherung. Die Entscheidung darüber, wie ein Datensatz angereichert werden soll, zum Beispiel, was ihm hinzugefügt werden soll, ist eine komplexe Aufgabe, die ein umfassendes Verständnis der geschäftlichen Anforderungen und Analyseziele erfordert.
- Prozesse der Datenaufbereitung aufrechterhalten und erweitern. Die Datenaufbereitung wird oft zu einem wiederkehrenden Prozess, der kontinuierlich gepflegt und verbessert werden muss.

Welche Software gibt es für die Datenaufbereitung?
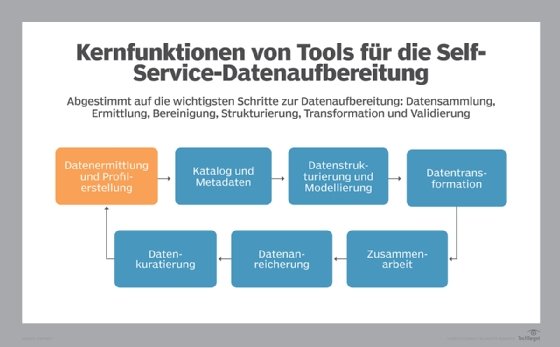
Die Datenaufbereitung kann qualifizierte BI-, Analyse- und Datenmanagement-Experten von hochwertigeren Aufgaben abziehen – insbesondere, da die in Analyse-Anwendungen verwendete Datenmenge weiter wächst. Verschiedene Softwareanbieter haben jedoch Self-Service-Tools eingeführt, die die Datenaufbereitung automatisieren. Diese Werkzeuge ermöglichen es sowohl Datenexperten als auch Geschäftsanwendern, Daten interaktiv auf optimale Weise für die Analyse vorzubereiten.
Die Self-Service-Tools für die Datenaufbereitung lassen Datensätze durch einen Workflow laufen, um die im vorherigen Abschnitt beschriebenen Operationen und Funktionen anzuwenden. Sie verfügen außerdem über grafische Benutzeroberflächen (GUIs), die diese Schritte weiter vereinfachen sollen.
In seiner Analyse zu Datenmanagement-Technologien stuft das Beratungsunternehmen Gartner die Vorteile von Tools zur Datenaufbereitung als hoch für die Benutzer ein. Gleichzeitig diagnostizierten die Analysten aber auch, dass sich diese Werkzeuge noch im frühen Reifestadium befinden. Positiv zu vermerken ist in jedem Fall, dass die Tools die Zeit bis zur Datenanalyse verkürzen und die gemeinsame Nutzung von Daten, die Zusammenarbeit von Anwendern und die Durchführung von Data-Science-Experimenten fördern können.
Allerdings merken die Gartner-Experten auch an, dass einige Tools nicht in der Lage sind, von einzelnen Self-Service-Projekten auf Unternehmensebene zu skalieren. Auch können sie meist nicht Metadaten mit anderen Datenmanagement-Technologien, zum Beispiel Software zur Sicherung der Datenqualität, austauschen. Gartner empfiehlt Unternehmen, in Frage kommende Produkte auch nach diesen Merkmalen zu bewerten. Die Analysten warnen auch davor, Software für die Datenaufbereitung als Ersatz für herkömmliche Technologien zur Datenintegration zu betrachten, insbesondere für ETL-Tools (Extract, Transform, Load).
Mehrere Anbieter, die sich auf die Self-Service-Datenaufbereitung konzentrierten, wurden inzwischen von anderen Unternehmen übernommen; Trifacta, der letzte der bekanntesten Datenaufbereitungsspezialisten, wurde Anfang 2022 vom Analyse- und Datenmanagement-Spezialisten Alteryx gekauft. Alteryx selbst unterstützt die Datenaufbereitung bereits in seiner Software. Zu den anderen bekannten BI-, Analyse- und Datenmanagement-Anbietern, die Tools und Funktionen für die Datenaufbereitung anbieten, gehören:
- Altair
- Boomi
- Datameer
- DataRobot
- IBM
- Informatica
- Microsoft
- Precisely
- SAP
- SAS
- Tableau
- Talend
- Tamr
- Tibco
Trends bei der Datenaufbereitung
Eine effektive Datenaufbereitung ist für Anwendungen des maschinellen Lernens von entscheidender Bedeutung. Jedoch werden Algorithmen des maschinellen Lernens auch selbst zunehmend für die Datenaufbereitung eingesetzt. Gartner stellte in seiner Analyse fest, dass die Automatisierung der Datenaufbereitung häufig als einer der wichtigsten Investitionsbereiche für Daten- und Analyseteams genannt wird. Laut Gartner können Tools zur Datenaufbereitung mit eingebetteten Algorithmen verschiedene Aufgaben automatisieren.
Beispielsweise sind Tools mit erweiterten Funktionen für die Datenaufbereitung in der Lage, automatisch Datenprofile zu erstellen, Fehler zu beheben und Maßnahmen zur Datenbereinigung, -umwandlung und -anreicherung zu empfehlen. Automatisierte Funktionen für die Datenaufbereitung sind auch in den Augmented-Analytics-Technologien enthalten, die heute von vielen BI-Anbietern auf den Markt gebracht werden. Die Automatisierung ist besonders hilfreich für Self-Service-BI-Anwender und Citizen Data Scientists – dies sind Business-Analysten und andere Mitarbeiter, die keine formale Data-Science-Ausbildung haben, aber selbstständig fortgeschrittene Analysen durchführen. Die Automatisierung beschleunigt aber auch die Datenaufbereitung durch erfahrene Data Scientists und Data Engineers.
Auch die Datenaufbereitung über Cloud-Anwendungen rückt immer mehr in den Fokus, da immer mehr Hersteller Cloud-Services für die Datenaufbereitung anbieten. Ein weiterer aktueller Trend ist die Integration von Funktionen zur Datenaufbereitung in DataOps-Prozesse, die die Erstellung von Datenpipelines für BI und Analysen optimieren sollen.
Wie man mit der Datenaufbereitung beginnt
Donald Farmer, Principal bei TreeHive Strategy, nennt folgenden sechs Schritte als Ausgangspunkte für erfolgreiche Initiativen zur Datenaufbereitung:
- Betrachten Sie die Datenaufbereitung als Teil der Datenanalyse. Datenaufbereitung und -analyse sind „zwei Seiten derselben Medaille“, sagt Farmer. Einerseits brauchen Analysen gute Daten, andererseits können Daten nicht richtig aufbereitet werden, ohne zu wissen, für welche Analysezwecke sie benötigt werden.
- Definieren Sie, was Erfolg bei der Datenaufbereitung bedeutet. Die gewünschte Datengenauigkeit und andere Metriken der Datenqualität sollten als Ziele festgelegt und mit den voraussichtlichen Kosten abgeglichen werden. Auf diese Weise lässt sich ein Plan für die Datenaufbereitung erstellen, der für jeden Anwendungsfall geeignet ist.
- Priorisieren Sie die Datenquellen auf der Grundlage der Anwendung. Das Auflösen von Unterschieden in Daten aus mehreren Quellsystemen ist ein wichtiges Element der Datenaufbereitung, das ebenfalls auf dem geplanten Analytics-Anwendungsfall basieren sollte.
- Verwenden Sie die richtigen Tools für die Aufgabe und Ihr Know-how. Self-Service-Tools zur Datenaufbereitung sind nicht die einzige verfügbare Option – je nach Ihren Fähigkeiten und Datenanforderungen können auch andere Tools und Technologien verwendet werden.
- Seien Sie bei der Datenaufbereitung auf Fehler vorbereitet. In den Prozess der Datenaufbereitung müssen Funktionen zur Fehlerbehandlung eingebaut werden, um zu verhindern, dass er bei Problemen schief geht oder ins Stocken gerät.
- Behalten Sie die Kosten der Datenaufbereitung im Auge. Die Kosten für Softwarelizenzen sowie Verarbeitungs- und Speicherressourcen und für die an der Datenaufbereitung beteiligten Mitarbeiter sollten genau beobachtet werden, um sicherzustellen, dass sie nicht aus dem Ruder laufen.






