Fault Tolerance (Fehlertoleranz)

Was ist Fault Tolerance (Fehlertoleranz)?
Fehlertoleranz ist eine entscheidende Eigenschaft moderner Computersysteme, die es ihnen ermöglicht, trotz des Ausfalls einzelner Komponenten ununterbrochen zu funktionieren. Diese Fähigkeit ist nicht nur auf die Hardware beschränkt, sondern erstreckt sich auch auf die Bewältigung von Software- und Logikfehlern. Das übergeordnete Ziel der Fehlertoleranz besteht darin, katastrophale Ausfälle zu verhindern, die durch einen einzelnen Fehlerpunkt (Single Point of Failure, SPOF) verursacht werden könnten.
Fehlertolerante Systeme sind so konzipiert, dass sie selbst bei mehrfachen Ausfällen weiterhin funktionsfähig bleiben. Sie erkennen automatisch Fehler in verschiedenen Komponenten wie CPU, I/O-Subsystem, Memory-Karten, Hauptplatine, Stromversorgung oder Netzwerkkomponenten. Sobald ein Fehler identifiziert wird, tritt sofort eine Ersatzkomponente oder -prozedur in Kraft, ohne den laufenden Betrieb zu beeinträchtigen.
Implementierung und Vergleich mit anderen Konzepten
Die Umsetzung von Fehlertoleranz kann auf verschiedene Arten erfolgen: durch Software, in Hardware eingebettet oder durch eine Kombination beider Ansätze. Bei einer softwarebasierten Implementierung bietet das Betriebssystem Schnittstellen, die es Programmierern ermöglichen, kritische Daten an definierten Punkten innerhalb einer Transaktion zu überprüfen. Hardware-Implementierungen hingegen erfordern kein spezielles Wissen des Programmierers über die fehlertoleranten Fähigkeiten der Maschine.
Auf Hardwareebene wird Fehlertoleranz oft durch Duplexing jeder Komponente erreicht. Dies umfasst beispielsweise die Spiegelung von Festplatten oder die Gruppierung mehrerer Prozessoren, deren Ausgaben auf Korrektheit verglichen werden. Bei Anomalien wird die fehlerhafte Komponente identifiziert und außer Betrieb genommen, während der Computer normal weiterfunktioniert.
Fehlertoleranz und Hochverfügbarkeit im Vergleich
Obwohl eng miteinander verbunden, unterscheiden sich Fehlertoleranz und Hochverfügbarkeit in ihren Ansätzen. Fehlertolerante Umgebungen stellen den Dienst nach einem Ausfall sofort wieder her, während Hochverfügbarkeitsumgebungen eine Betriebsbereitschaft von 99,999 Prozent anstreben. Hochverfügbarkeits-Cluster bestehen aus lose gekoppelten, unabhängigen Servern, die sich gegenseitig überwachen und Fehlerbehebung bieten. Fehlertolerante Cluster hingegen teilen sich eine einzige Kopie des Betriebssystems über mehrere physische Systeme hinweg.
Der Kompromiss bei der Wahl zwischen Fehlertoleranz und hoher Verfügbarkeit sind die Kosten. Systeme mit integrierter Fehlertoleranz verursachen höhere Kosten, da zusätzliche Hardware benötigt wird.
Fehlertoleranz und Graceful Degradation im Vergleich
Während Fehlertoleranz und Graceful Degradation oft synonym verwendet werden, gibt es wichtige Unterschiede. Ein fehlertolerantes System tauscht Ersatzkomponenten aus, um ein hohes Maß an Systemverfügbarkeit und Leistung aufrechtzuerhalten. Graceful Degradation ermöglicht es einem System, den Betrieb fortzusetzen, wenn auch mit reduzierter Leistung.
Data Protection und Fehlertoleranz
Fehlertoleranz basiert stark auf Redundanz, sei es durch Datenreplikation, synchrone Spiegelung von Volumes oder physische Redundanz durch zusätzliche Hardware. Die Kombination von Datensicherung und Redundanz bietet umfassenden Schutz vor Datenverlusten. Bei der Implementierung von Fehlertoleranz sollten Unternehmen die Anforderungen an die Datenverfügbarkeit mit dem entsprechenden Maß an Datensicherheit abstimmen, beispielsweise durch den Einsatz von RAID-Technologien.
Unternehmen, die der Fehlertoleranz Vorrang vor Geschwindigkeit und Leistung einräumen, sind mit RAID 1 oder RAID 10, einer Kombination aus Festplattenspiegelung und Festplatten-Striping, am besten bedient. Wenn Fehlertoleranz und Systemleistung gleichermaßen wichtig sind, könnte ein Unternehmen RAID 10 mit RAID 6 oder Double-Parity-RAIDkombinieren, das zwei Festplattenausfälle toleriert, bevor die Daten verloren gehen. Abgesehen von den höheren Kosten besteht der andere Nachteil darin, dass die Daten langsamer auf den RAID-Satz geschrieben werden.
Abgesehen von der Hardware sollte eine fehlertolerante Architektur mit regelmäßig geplanten Backups kritischer Daten koordiniert werden, zum Beispiel durch eine gespiegelte Kopie an einem zweiten oder alternativen Standort. Die Sicherheit muss in die Planung einbezogen werden, um unbefugten Zugriff zu verhindern, und es müssen Antivirus-Toolsund die neueste Version des Betriebssystems des Computersystems eingesetzt werden.
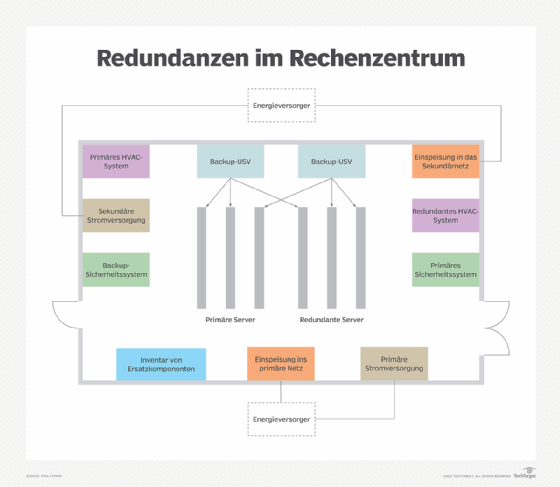
Bedeutung der Fehlertoleranz für verschiedene Branchen
Fehlertoleranz ist in vielen Branchen von entscheidender Bedeutung, insbesondere in solchen, die auf zuverlässige Online-Transaktionsverarbeitungssysteme angewiesen sind. Dazu gehören Flugsteuerungs- und Reservierungssysteme von Fluggesellschaften, aber auch Bereiche wie Vertrieb und Logistik, Elektrizitätswerke, Schwerindustrie, industrielle Kontrollsysteme und Einzelhandel. In diesen Sektoren ist Fehlertoleranz nicht nur eine technische Funktion, sondern eine grundlegende Anforderung für den sicheren und effizienten Betrieb kritischer Systeme.
Erfahren Sie mehr über Disaster Recovery
-
![]()
Quantenfehlerkorrektur: Verfahren und Herausforderungen
Von: Stephen Bigelow
-
![]()
RAID 6 und RAID 10: Warum sich ein Leistungsvergleich lohnt
Von: Brien Posey
-
![]()
Die Funktionsweisen von RAID 1 und RAID 0 im Kurzvergleich
Von: Brien Posey
-
![]()
Auswahl und Konfiguration von Windows Server RAID-Levels
Von: Damon Garn



