
Gajus - Fotolia
DR-Plan: So integrieren Sie Hochverfügbarkeit und Resilienz
Mit Hochverfügbarkeit und Resilienz kann sich eine Firma auf potenzielle Störungen vorberei-tet. Erfahren Sie, wie diese Parameter innerhalb eines Disaster Recoverys funktionieren.

In einer Zeit, in der Ausfallzeiten nahezu inakzeptabel geworden sind, zählen Hochverfügbarkeit (High Availability, HA) und Resilienz zu den wichtigsten Kennzahlen im Bereich der Business Continuity und des Disaster Recoverys (DR).
Beide Konzepte adressieren Unterbrechungen, die durch Systemausfälle, Netzwerkausfälle oder Anwendungsprobleme verursacht werden. In der IT steht hohe Verfügbarkeit für Systeme, die für definierte Zeiträume unterbrechungsfrei operieren. Resilienz hingegen ist die Fähigkeit eines Systems, sich von einer Störung zu erholen und seine Fähigkeiten so anzupassen, dass es künftigen Vorfällen besser begegnen kann.
Obwohl beide Begriffe auf ähnliche Ziele ausgerichtet sind, sind sie nicht gleichbedeutend. Eine umfassende Disaster-Recovery-Strategie sollte beide Komponenten enthalten.
Dieser Artikel beleuchtet die Unterschiede zwischen HA und Resilienz, deren Rolle in einem DR-Plan sowie den ergänzenden Begriff der Fehlertoleranz (Fault Tolerance).
Hochverfübarkeit
Hohe Verfügbarkeit beschreibt die Fähigkeit eines Systems, über einen bestimmten Zeitraum hinweg ohne Unterbrechung betriebsbereit zu bleiben.
IT-Administratoren setzen typischerweise auf Redundanz, um sicherzustellen, dass im Falle eines Ausfalls der primären Systeme Backup-Hardware, -Software und -Speicher zur Verfügung stehen. Oft müssen diese Ressourcen manuell aktiviert werden. HA geht über einfache Redundanz hinaus.
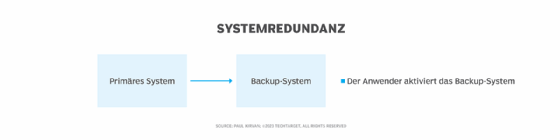
Ein HA-System reduziert Single Points of Failure (SPOF) durch den Einsatz dynamischer Systemüberwachung zur Fehlererkennung sowie automatischer Failover-Mechanismen, die im Störfall sofort auf alternative Systeme umschalten.
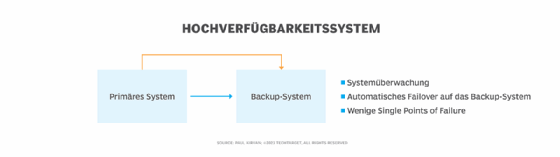
Diese Backup-Systeme können sich im firmeneigenen Rechenzentrum oder an einem anderen Ort befinden – etwa in der Cloud. Die Wiederanlaufzeit nach einem Failover hängt von Faktoren wie der verfügbaren Netzwerkbandbreite und der eingesetzten Technologie ab.
HA-Systeme werden meist so konzipiert, dass sie einen bestimmten Verfügbarkeitsgrad erreichen, oft bezeichnet als prozentuale Verfügbarkeit (Uptime). Ein häufig angestrebter Wert ist die sogenannte Fünf-Neunen-Verfügbarkeit – 99,999 Prozent, was weniger als sechs Minuten Ausfallzeit pro Jahr bedeutet.
Je höher die Verfügbarkeit, desto höher die Kosten – allerdings auch der Nutzen. Monitoring-Technologien, Backup-Infrastruktur und zusätzliche Betriebsmittel verursachen Kosten, die über die einer einfachen Redundanz hinausgehen. Daher ist es ratsam, kritische IT-Komponenten (zum Beispiel Stromversorgung, Netzwerkkomponenten, Server) als Ersatz vorrätig zu halten.
Im Hinblick auf die oft erheblichen Kosten eines Systemausfalls kann sich diese Investition jedoch schnell amortisieren.
Was ist Resilienz?
Business Continuity und Disaster Recovery (BC/DR) fokussieren sich in der Regel auf das Wiederherstellen von Systemen und Prozessen. Resilienz geht einen Schritt weiter: Ein resilientes Unternehmen nutzt Erfahrungen aus früheren Störungen, um seine Strategien und Systeme anzupassen und künftige Zwischenfälle besser zu bewältigen.
Resilienz kann sich auf Notfallpläne, IT-Systeme, Netzwerke, Backup-Infrastruktur, Stromversorgung oder Umweltsysteme beziehen.
Ein Beispiel: Wenn ein kommerzieller Stromausfall zwei Wochen andauert, könnte die bestehende Notstromversorgung unzureichend sein. Eine resilientere Lösung wäre ein größeres Notstromsystem mit geplanter Kraftstoffnachlieferung.
Resilienz bedeutet also nicht nur Wiederherstellung, sondern Anpassung und Weiterentwicklung. Dies ist entscheidend für eine nachhaltige Krisenbewältigung.
Die Rolle von Hochverfügbarkeit und Resilienz beim Disaster Recovery
HA zielt auf Verfügbarkeit und Zuverlässigkeit von Systemen ab, während Resilienz die Lernfähigkeit und Anpassung von Ressourcen zur Bewältigung zukünftiger Ereignisse beschreibt. Beide Komponenten sind zentrale Elemente eines starken DR-Plans, da sie Ausfallzeiten minimieren – das ultimative Ziel moderner Disaster-Recovery-Strategien.
Zwar ist HA ein wichtiger Teil von Resilienz, jedoch nicht mit ihr gleichzusetzen. HA erfordert signifikante technologische Investitionen. Resilienz dagegen kann schrittweise entwickelt werden – abhängig vom gewünschten Niveau und den verfügbaren Budgets.
Manche Unternehmen zögern trotz wachsender Risiken, in DR-Strategien zu investieren. IT- und DR-Verantwortliche müssen daher sorgfältig abwägen, welches Maß an Resilienz notwendig ist – und wie dieses mit dem unternehmerischen Risiko und Budgetrahmen vereinbar ist.
Wenn die Geschäftsführung keine Bereitschaft zeigt, umfangreiche technische Investitionen zu tätigen, kann eine hochverfügbare Infrastruktur unter Umständen nicht realisiert werden, was schwere Folgen im Falle einer größeren Störung nach sich zieht.
Fehlertoleranz (Fault Tolerance)
Fehlertoleranz ist die nächste Stufe nach Hochverfügbarkeit. Während HA und Resilienz den Großteil der Risiken abfangen können, strebt Fault Tolerance an, Ausfälle nahezu vollständig auszuschließen – abgesehen von außergewöhnlichen Ereignissen wie Naturkatastrophen.
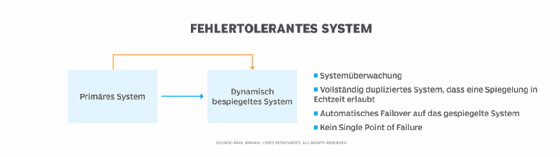
Fehlertolerante Konfigurationen nutzen oft vollständig gespiegelte (mirrored) Systeme, die in Echtzeit synchronisiert werden. Damit gibt es keine Single Points of Failure mehr. Sobald das Monitoring eine Störung erkennt, erfolgt ein nahtloser Wechsel auf das Standby-System – ohne Produktionsunterbrechung. Diese Spiegel-Systeme können lokal oder in der Cloud betrieben werden.
Fehlertolerante Systeme erfordern hochverfügbare Infrastruktur, spezialisierte Software, zusätzliche Hardware und permanente Synchronisation – was die Kosten im Vergleich zu HA nochmals erhöht.
Trotzdem kann diese Strategie für besonders kritische Systeme (zum Beispiel im Gesundheitswesen, bei Banken oder Industrieanlagen) entscheidend sein.
Kurz gefasst: Hochverfügbarkeit und Resilienz im Disaster Recovery
Eine starke Disaster-Recovery-Strategie sollte drei Kernelemente enthalten – Hochverfügbarkeit, Resilienz, Fehlertoleranz, um umfassende Data Protection zu gewährleisten. Jede dieser Kennzahlen bringt ihre eigenen Vorteile mit
Hochverfügbarkeit (High Availability, HA):
- Systeme bleiben über längere Zeiträume unterbrechungsfrei in Betrieb
- Redundante Hardware/Software, automatisches Failover
- Ziel: Minimierung von Ausfallzeiten
- Beispielziel: 99,999 Prozent Verfügbarkeit ( = <6 Min. Ausfallzeit/Jahr)
Resilienz:
- Fähigkeit, sich nach Störungen schnell zu erholen und daraus zu lernen
- Anpassung von Prozessen, Systemen und Infrastruktur
- Ziel: Widerstandsfähigkeit gegenüber zukünftigen Störungen erhöhen
- Beispiel: Nach Stromausfall Investition in stärkere Notstromlösung
Fehlertoleranz (Fault Tolerance):
- Systeme mit vollständiger Echtzeit-Spiegelung
- Nahtloser Betrieb auch bei Ausfällen einzelner Komponenten
- Höchste Verfügbarkeitsstufe – teuer, aber für kritische Systeme essenziell
- Beispiel: Rechenzentren mit aktivem Live-Backup
Wichtig:
- HA und Resilienz sind ergänzende, aber nicht gleichbedeutende Konzepte
- Fehlertoleranz ist eine Erweiterung der HA – mit deutlich höheren Anforderungen
- Eine effektive DR-Strategie kombiniert technische Redundanz mit organisatorischer Lernfähigkeit






