Hochverfügbarkeit (High Availibility, HA)
Was ist Hochverfügbarkeit (High Availability, HA)?
Hochverfügbarkeit, auch als High Availability (HA) bekannt, beschreibt die Fähigkeit eines Systems, über einen ausgedehnten Zeitraum hinweg ohne Unterbrechungen zu funktionieren. Das Ziel der Hochverfügbarkeit besteht darin, ein vereinbartes betriebliches Leistungsniveau aufrechtzuerhalten. In der Informationstechnologie (IT) ist ein weitverbreiteter Verfügbarkeitsstandard die sogenannte Five-Nines-Verfügbarkeit oder Fünf Neunen, was bedeutet, dass das System oder Produkt 99,999 Prozent der Zeit verfügbar ist.
Hochverfügbarkeitssysteme finden Anwendung in Situationen und Branchen, in denen die ununterbrochene Funktionsfähigkeit des Systems von entscheidender Bedeutung ist. Zu den realen Beispielen für Hochverfügbarkeitssysteme gehören militärische Kontrollsysteme, autonome Fahrzeuge sowie Systeme in der Industrie und im Gesundheitswesen. Das Leben von Menschen hängt davon ab, dass diese Systeme jederzeit verfügbar sind und einwandfrei funktionieren. Ein Ausfall des Systems eines autonomen Fahrzeugs während des Betriebs könnte beispielsweise zu einem Unfall führen, der die Insassen, andere Verkehrsteilnehmer, Fußgänger und Eigentum gefährdet.
Hochverfügbare Systeme erfordern eine sorgfältige Konzeption und gründliche Tests vor ihrer Inbetriebnahme. Bei der Planung eines solchen Systems muss sichergestellt werden, dass alle Komponenten den angestrebten Verfügbarkeitsstandard erfüllen. Backup- und Failover-Funktionen spielen eine entscheidende Rolle, um die Erreichung der Verfügbarkeitsziele von HA-Systemen zu gewährleisten. Systementwickler müssen zudem den eingesetzten Datenspeicher- und Zugriffstechnologien besondere Aufmerksamkeit widmen.
Funktionsweise von Hochverfügbarkeit
Da es unmöglich ist, dass Systeme zu 100 Prozent verfügbar sind, streben echte Hochverfügbarkeitssysteme im Allgemeinen fünf Neunen als Standard für die Betriebsleistung an.
Die folgenden drei Prinzipien werden bei der Entwicklung von HA-Systemen angewandt, um eine hohe Verfügbarkeit zu gewährleisten:
- Single Point of Failure (SPoF). Ein Single Point of Failure ist eine Komponente, bei deren Ausfall das gesamte System ausfallen würde. Wenn ein Unternehmen einen Server hat, auf dem eine Anwendung läuft, ist dieser Server ein Single-Point-of-Failure. Sollte dieser Server ausfallen, ist die Anwendung nicht mehr verfügbar.
- Zuverlässiges Crossover. Der Einbau von Redundanz in diese Systeme ist ebenfalls wichtig. Redundanz ermöglicht es, dass eine Backup-Komponente für eine ausgefallene Komponente einspringt. In diesem Fall muss ein zuverlässiges Crossover oder Failover gewährleistet sein, das heißt ein Wechsel von Komponente X zu Komponente Y ohne Datenverlust oder Leistungseinbußen.
- Erkennbarkeit von Ausfällen. Ausfälle müssen sichtbar sein, und im Idealfall verfügen die Systeme über eine eingebaute Automatisierung, um den Ausfall selbständig zu beheben. Es sollte auch eingebaute Mechanismen zur Vermeidung von Fehlern mit gemeinsamer Ursache geben, bei denen zwei oder mehr Systeme oder Komponenten gleichzeitig ausfallen, wahrscheinlich aufgrund derselben Ursache.
Um eine hohe Verfügbarkeit zu gewährleisten, wenn viele Benutzer auf ein System zugreifen, ist ein Lastausgleich (Load Balancing) erforderlich. Beim Lastausgleich werden die Arbeitslasten automatisch auf die Systemressourcen verteilt, beispielsweise indem verschiedene Datenanforderungen an verschiedene Dienste in einer hybriden Cloud-Architektur gesendet werden. Der Load Balancer entscheidet, welche Systemressource am besten in der Lage ist, welche Arbeitslast effizient zu bewältigen. Durch den Einsatz mehrerer Load Balancer wird sichergestellt, dass keine einzelne Ressource überlastet wird.
Die Server in einem HA-System befinden sich in Clustern und sind in einer abgestuften (tiered) Architektur organisiert, um auf Anfragen von Load Balancern zu reagieren. Wenn ein Server im Cluster ausfällt, kann ein replizierter Server in einem anderen Cluster die für den ausgefallenen Server vorgesehene Arbeitslast übernehmen. Diese Art der Redundanz ermöglicht ein Failover, bei dem eine sekundäre Komponente die Aufgabe einer primären Komponente übernimmt, wenn die erste Komponente ausfällt, und zwar mit minimalen Leistungseinbußen.
Je komplexer ein System ist, desto schwieriger ist es, Hochverfügbarkeit zu gewährleisten, da es in einem komplexen System einfach mehr Fehlerquellen gibt.
Die Bedeutung von Hochverfügbarkeit
Systeme, die die meiste Zeit über betriebsbereit sein müssen, betreffen oft die Gesundheit der Menschen, ihr wirtschaftliches Wohlergehen und den Zugang zu Nahrung, Unterkunft und anderen Lebensgrundlagen. Mit anderen Worten, es handelt sich um Systeme oder Komponenten, die schwerwiegende Auswirkungen auf ein Unternehmen oder das Leben der Menschen haben, wenn sie unter ein bestimmtes Niveau der Betriebsleistung fallen.
Wie bereits erwähnt, sind autonome Fahrzeuge klare Kandidaten für HA-Systeme. Wenn beispielsweise der nach vorn gerichtete Sensor eines selbstfahrenden Autos eine Fehlfunktion hat und die Seite eines LKW mit der Straße verwechselt, wird das Auto einen Unfall verursachen. Obwohl das Auto in diesem Szenario funktionstüchtig war, führte der Ausfall einer seiner Komponenten, die nicht die erforderliche Betriebsleistung erbrachte, zu einem wahrscheinlich schweren Unfall.
Elektronische Gesundheitsakten oder Patientenakten (Electronic Health Records, EHR) sind ein weiteres Beispiel dafür, dass Leben von HA-Systemen abhängen. Wenn ein Patient mit starken Schmerzen in der Notaufnahme auftaucht, benötigt der Arzt sofortigen Zugriff auf die Krankenakte des Patienten, um sich ein vollständiges Bild von der Krankengeschichte des Patienten zu machen und die besten Behandlungsentscheidungen zu treffen. Ist der Patient ein Raucher? Gibt es in der Familie eine Vorgeschichte mit Herzkomplikationen? Welche anderen Medikamente nimmt der Patient ein? Die Antworten auf diese Fragen werden sofort benötigt und können nicht durch Systemausfälle verzögert werden.
So wird Hochverfügbarkeit gemessen
Die Verfügbarkeit kann in Bezug auf ein System gemessen werden, das zu 100 Prozent betriebsbereit ist oder nie ausfällt, quasi keine Ausfälle hat. In der Regel wird die prozentuale Verfügbarkeit wie folgt berechnet:
Verfügbarkeit = (Minuten in einem Monat - Minuten der Ausfallzeit) x 100/Minuten in einem Monat
Zur Messung der Verfügbarkeit werden die folgenden drei Metriken verwendet:
- Die mittlere Zeit zwischen zwei Ausfällen (Mean Time Between Failures, MTBF) ist die erwartete Zeit zwischen zwei Ausfällen für ein bestimmtes System.
- Mittlere Ausfallzeit (Mean Downtime, MDT) ist die durchschnittliche Zeit, in der ein System nicht betriebsbereit ist.
- Recovery Time Objective (RTO), auch bekannt als geschätzte Reparaturzeit, ist die Gesamtzeit, die ein geplanter Ausfall oder die Wiederherstellung nach einem ungeplanten Ausfall dauern wird.
- Recovery Time Objective. RPO ist das maximale Ausmaß an Datenverlust, das ein Unternehmen im Falle eines Ausfalls tolerieren kann.
Diese Metriken können für firmeninterne Systeme oder von Dienstleistern verwendet werden, um den Kunden ein bestimmtes Serviceniveau zu versprechen, das in einer Service-Level-Vereinbarung (Service Level Agreement, SLA) festgelegt ist. SLAs sind Verträge, in denen festgelegt wird, welchen Prozentsatz an Verfügbarkeit die Kunden von einem System oder einer Dienstleistung erwarten können.

Verfügbarkeitsmetriken unterliegen der Interpretation, was die Verfügbarkeit des Systems oder Dienstes für den Endbenutzer ausmacht. Selbst wenn Systeme teilweise noch funktionieren, können Benutzer sie aufgrund von Leistungsproblemen für unbrauchbar halten. Trotz dieser Subjektivität werden Verfügbarkeitsmetriken in SLAs konkretisiert, für deren Einhaltung der Dienstanbieter oder das System verantwortlich ist.
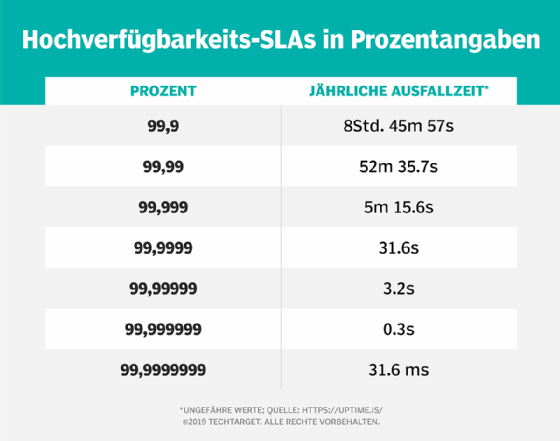
Wenn ein System oder ein SLA eine Verfügbarkeit von 99,999 Prozent vorsieht, kann der Endbenutzer davon ausgehen, dass der Dienst für die folgenden Zeitspannen nicht verfügbar ist:
| Zeitraum |
Zeitraum, in der das System nicht verfügbar ist |
| Täglich |
0,9 Sekunden |
| Wöchentlich |
6 Sekunden |
| Monatlich |
26,3 Sekunden |
| Jährlich |
5 Minuten und 15,6 Sekunden |
Zum Vergleich: Wenn ein Unternehmen den Drei-Neunen-Standard (99,9 Prozent) einhält, kommt es im Jahr zu etwa 8 Stunden und 45 Minuten Systemausfallzeit. Bei einem Standard von zwei Neunen sind die Ausfallzeiten sogar noch dramatischer: 99 Prozent Verfügbarkeit entsprechen etwas mehr als drei Tagen Ausfallzeit pro Jahr.
So erreichen Sie Hochverfügbarkeit
Die sechs Schritte zum Erreichen von Hochverfügbarkeit lauten wie folgt:
- Entwerfen Sie das System im Hinblick auf HA. Das Ziel bei der Entwicklung eines HA-Systems ist es, ein System zu schaffen, das die Leistungskonventionen einhält und gleichzeitig die Kosten und die Komplexität minimiert. Fehlerquellen sollten eliminiert und bei Bedarf Redundanz bereitgestellt werden.
- Definieren Sie die Erfolgsmetriken. Es muss festgelegt werden, wie hoch die Verfügbarkeit des Systems sein muss und mit welchen Kennzahlen sie gemessen werden soll. Dienstanbieter binden ihre Kunden über ein SLA in diesen Prozess ein.
- Bereitstellung der Hardware. Die Hardware sollte widerstandsfähig sein und ein ausgewogenes Verhältnis zwischen Qualität und Kosteneffizienz aufweisen. Hot-Swap-fähige und Hot-Plugging-fähige Hardware ist in HA-Systemen besonders nützlich, da die Hardware beim Austausch oder beim Ein- und Ausstecken von Komponenten nicht abgeschaltet werden muss.
- Testen Sie das Failover-System. Sobald das System in Betrieb ist, sollte das Failover-System überprüft werden, um sicherzustellen, dass es im Falle eines Ausfalls bereit ist, den Betrieb zu übernehmen. Die Anwendungen sollten im Laufe der Zeit getestet und erneut getestet werden, und es sollte ein Testplan aufgestellt werden.
- Überwachen Sie das System. Die Leistung des Systems sollte anhand von Metriken und Beobachtungen verfolgt werden. Jede Abweichung von der Norm muss protokolliert und ausgewertet werden, um festzustellen, wie das System beeinflusst wurde und welche Anpassungen erforderlich sind.
- Analysieren Sie die aus der Überwachung gewonnenen Daten und suchen Sie dann nach Möglichkeiten, das System zu verbessern. Stellen Sie die Verfügbarkeit weiterhin sicher, wenn sich die Bedingungen ändern und das System weiterentwickelt wird.
So hängen Disaster Recovery und Hochverfügbarkeit zusammen
Disaster Recovery (DR) ist ein Teil der Sicherheitsplanung, der sich auf die Wiederherstellung nach einem katastrophalen Ereignis konzentriert, zum Beispiel nach einer Naturkatastrophe, die das physische Rechenzentrum oder eine andere Infrastruktur zerstört. Bei DR geht es darum, einen Plan für den Fall zu haben, dass das System oder das Netzwerk ausfällt, und die Folgen eines System- oder Netzwerkausfalls müssen bewältigt werden. HA-Strategien hingegen befassen sich mit kleineren, lokalisierten Ausfällen oder Fehlern.
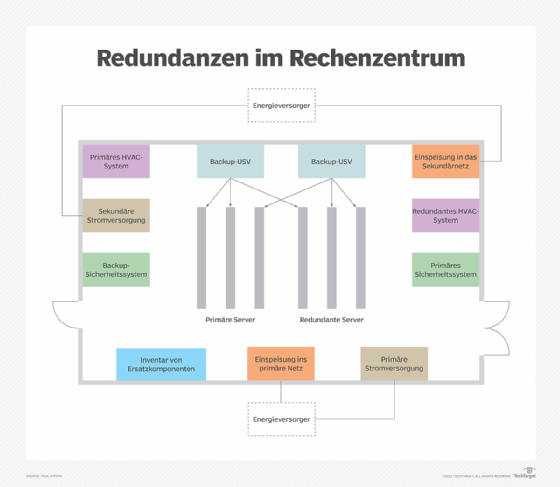
Es gibt viele Überschneidungen zwischen der Infrastruktur und den Strategien, die für DR und HA eingesetzt werden. Für alle kritischen Komponenten von Hochverfügbarkeitssystemen sollten Backups und Failover-Prozesse vorhanden sein, die auch in einem DR-Szenario zum Tragen kommen. Zu diesen Komponenten können Server, Speichersysteme, Netzwerkknoten, Satelliten und ganze Rechenzentren gehören. Backup-Komponenten sollten in die Infrastruktur des Systems integriert werden. Wenn beispielsweise ein Datenbankserver ausfällt, sollte ein Unternehmen in der Lage sein, auf einen Backup-Server auszuweichen.
In einer HA-Umgebung werden Datensicherungen benötigt, um die Verfügbarkeit im Falle von Datenverlusten, -beschädigungen oder Speicherausfällen aufrechtzuerhalten. Ein Rechenzentrum sollte Datensicherungen auf redundanten Servern hosten, um die Ausfallsicherheit der Daten und eine schnelle Wiederherstellung bei Datenverlust zu gewährleisten, und über automatisierte DR-Prozesse verfügen.
So hängen Fehlertoleranz und Hochverfügbarkeit zusammen
Wie die DR trägt auch die Fehlertoleranz zur Gewährleistung einer hohen Verfügbarkeit bei. Fehlertoleranz ist die Fähigkeit eines Systems, Fehler in den Systemfunktionen zu ertragen und zu antizipieren und im Falle eines Fehlers automatisch zu reagieren. Ein fehlertolerantes System erfordert Redundanz, um die Unterbrechung im Falle eines Hardwareausfalls zu minimieren.
Um Redundanz zu erreichen, sollten IT-Organisationen eine N+1, N+2, 2N oder 2N+1 Strategie verfolgen. N steht für die Anzahl der Server, die benötigt werden, um das System am Laufen zu halten. Ein N+1-Modell erfordert alle für den Betrieb des Systems erforderlichen Server plus einen zusätzlichen. Ein 2N-Modell würde doppelt so viele Server erfordern, wie das System normalerweise benötigt. Ein 2N + 1-Ansatz bedeutet doppelt so viele Server wie nötig plus einen weiteren. Diese Strategien stellen sicher, dass geschäftskritische Komponenten mindestens ein Backup erhalten.
Es ist möglich, dass ein System zwar hochverfügbar, aber nicht fehlertolerant ist. Wenn beispielsweise bei einem HA-System ein Problem beim Hosten einer virtuellen Maschine auf einem Server in einem Cluster von Knoten auftritt, das System aber nicht fehlertolerant ist, kann der Hypervisor versuchen, die VM im selben Host-Cluster neu zu starten. Dies wird wahrscheinlich erfolgreich sein, wenn das Problem softwarebasiert ist. Wenn das Problem jedoch mit der Hardware des Clusters zusammenhängt, wird ein Neustart im selben Cluster das Problem nicht beheben, da die VM im selben defekten Cluster gehostet wird.
Ein fehlertoleranter Ansatz würde in der gleichen Situation wahrscheinlich eine N+1-Strategie anwenden und die VM auf einem anderen Server in einem anderen Cluster neu starten. Fehlertoleranz garantiert eher null Ausfallzeiten. Eine DR-Strategie würde noch einen Schritt weiter gehen und sicherstellen, dass im Katastrophenfall eine Kopie des gesamten Systems an einem anderen Ort zur Verfügung steht.
Zuverlässige Methoden für Hochverfügbarkeit
Ein hochverfügbares System sollte in der Lage sein, sich schnell von jeder Art von Fehlerzustand zu erholen, um die Unterbrechungen für den Endbenutzer zu minimieren. Zu den bewährten Praktiken für hohe Verfügbarkeit gehören die folgenden:
- Eliminieren Sie SPoFs oder alle Knoten, die das System beeinträchtigen würden, wenn es nicht mehr funktioniert.
- Stellen Sie sicher, dass alle Systeme und Daten für eine schnelle und einfache Wiederherstellung gesichert sind.
- Nutzen Sie Load Balancing, um den Anwendungs- und Netzwerkverkehr auf Server oder andere Hardware zu verteilen. Ein Beispiel für einen redundanten Load Balancer ist HAProxy.
- Kontinuierliche Überwachung des Zustands der Backend-Datenbankserver.
- Verteilen Sie bei Stromausfällen oder Naturkatastrophen die Ressourcen auf verschiedene geografische Regionen.
- Implementieren Sie ein zuverlässiges Failover. Im Hinblick auf Storage ist ein RAID-Array oder ein Storage Area Network (SAN) gängige Ansätze.
- Richten Sie ein System ein, das Ausfälle sofort erkennt, sobald sie auftreten.
- Entwerfen Sie Systemteile für hohe Verfügbarkeit und testen Sie deren Funktionalität vor der Implementierung.
Hochverfügbarkeit und die Cloud
Wie bereits erwähnt, ist die Hochverfügbarkeit ein subjektives Element. Je nach System ist der Umfang der erforderlichen Betriebszeit unterschiedlich. Beim Cloud Computing ist das Serviceniveau besonders variabel.
Die Anbieter von Cloud-Diensten haben im Allgemeinen eine Verfügbarkeit von mindestens 99,9 Prozent für ihre kostenpflichtigen Dienste versprochen; in letzter Zeit sind sie bei einigen Diensten zu einer Verfügbarkeit von 99,99 Prozent und mehr übergegangen. Es stellt sich jedoch die Frage, welche Anwendungen dieses Verfügbarkeitsniveau benötigen.
Finden Sie heraus, welche Fragen Sie sich zu Cloud-Anwendungen stellen sollten, um zu bestimmen, welches Verfügbarkeitsniveau sie benötigen und ob die gesamte Verfügbarkeit notwendig ist.






