Apache Spark

Was ist Apache Spark?
Apache Spark ist ein Open-Source-Framework für die parallele Verarbeitung großer Datenanalyseanwendungen auf geclusterten Computern. Es kann sowohl Batch- als auch Echtzeit-Analysen und Datenverarbeitungslasten bewältigen.
Spark wurde im Februar 2014 zu einem Top-Level-Projekt der Apache Software Foundation (AFS), und Version 1.0 von Apache Spark wurde im Mai 2014 veröffentlicht. Spark Version 2.0 wurde im Juli 2016 veröffentlicht.
Die Technologie wurde ursprünglich im Jahr 2009 von Forschern der University of California, Berkeley, entwickelt, um die Verarbeitung von Aufträgen in Hadoop-Systemen zu beschleunigen.
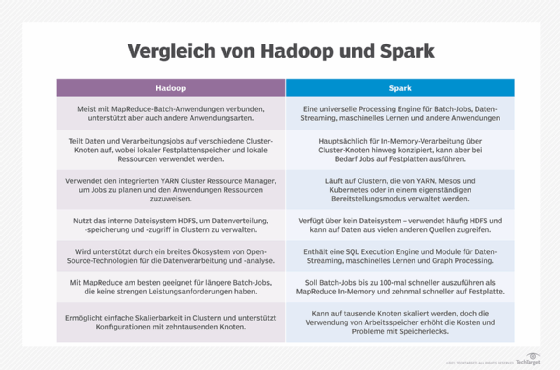
Spark Core, das Herzstück des Projekts, das verteilte Aufgabenübertragungs-, Planungs- und E/A-Funktionen (Input/Output, I/O) bereitstellt, bietet Programmierern eine potenziell schnellere und flexiblere Alternative zu MapReduce, dem Software-Framework, an das frühe Versionen von Hadoop gebunden waren. Die Entwickler von Spark sagen, dass es Aufträge 100 Mal schneller als MapReduce ausführen kann, wenn sie im Speicher verarbeitet werden, und 10 Mal schneller auf der Festplatte.
Wie Apache Spark funktioniert
Apache Spark kann Daten aus einer Vielzahl von Datenspeichern verarbeiten, darunter das Hadoop Distributed File System (HDFS), NoSQL-Datenbanken und relationale Datenspeicher, wie Apache Hive. Spark unterstützt die In-Memory-Verarbeitung, um die Leistung von Big-Data-Analyseanwendungen zu steigern, kann aber auch eine herkömmliche festplattenbasierte Verarbeitung durchführen, wenn die Datensätze zu groß sind, um in den verfügbaren Systemspeicher zu passen.
Die Spark Core-Engine verwendet den elastischen verteilten Datensatz (Resilient Distributed Dataset, RDD) als grundlegenden Datentyp. Der RDD ist so konzipiert, dass ein Großteil der Berechnungskomplexität vor den Benutzern verborgen bleibt. Es aggregiert Daten und verteilt sie auf einen Server-Cluster, wo es sie dann berechnet und entweder in einen anderen Datenspeicher verschiebt oder durch ein Analysemodell weiterleitet. Der Benutzer muss nicht festlegen, wohin bestimmte Dateien gesendet werden oder welche Rechenressourcen zum Speichern oder Abrufen von Dateien verwendet werden.
Darüber hinaus kann Spark mehr als nur die Stapelverarbeitungsanwendungen ausführen, auf die MapReduce beschränkt ist.
Spark-Bibliotheken
Die Spark Core-Engine fungiert zum Teil als API-Schicht (Application Programming Interface) und untermauert eine Reihe von verwandten Tools für die Verwaltung und Analyse von Daten. Neben der Spark Core-Verarbeitungs-Engine enthält die Apache Spark-API-Umgebung einige Code-Bibliotheken zum Verwenden in Datenanalyseanwendungen. Zu diesen Bibliotheken gehören die folgenden:
- Spark SQL – Eine der am häufigsten verwendeten Bibliotheken, Spark SQL ermöglicht Benutzern die Abfrage von Daten, die in unterschiedlichen Anwendungen gespeichert sind, unter Verwendung der gängigen SQL-Sprache.
- Spark Streaming – Diese Bibliothek ermöglicht es Benutzern, Anwendungen zu erstellen, die Daten in Echtzeit analysieren und darstellen.
- MLlib – Eine Bibliothek mit Code für maschinelles Lernen, mit der Benutzer erweiterte statistische Operationen auf Daten in ihrem Spark-Cluster anwenden und Anwendungen um diese Analysen herum erstellen können.
- GraphX – Eine integrierte Bibliothek mit Algorithmen für graphparallele Berechnungen.
Spark-Sprachen
Spark wurde in Scala geschrieben, das als primäre Sprache für die Interaktion mit der Spark Core-Engine fungiert. Spark wird auch mit API-Konnektoren für Java und Python geliefert. Java gilt nicht als optimale Sprache für Data Engineering oder Data Science, weshalb viele Benutzer auf Python zurückgreifen, das einfacher und mehr auf die Datenanalyse ausgerichtet ist.
Es gibt auch ein R-Programmierpaket, das Benutzer herunterladen und in Spark ausführen können. Dies ermöglicht es den Benutzern, die beliebte Desktop-Data-Science-Sprache auf größeren verteilten Datensätzen in Spark auszuführen und damit Anwendungen zu erstellen, die Algorithmen für maschinelles Lernen nutzen.
Apache Spark Anwendungsfälle
Die große Auswahl an Spark-Bibliotheken und die Fähigkeit, Daten aus vielen verschiedenen Arten von Datenspeichern zu berechnen, bedeutet, dass Spark für viele verschiedene Probleme in vielen Branchen geeignet ist. Unternehmen der digitalen Werbung nutzen es, um Datenbanken mit Webaktivitäten zu verwalten und Kampagnen zu entwerfen, die auf bestimmte Verbraucher zugeschnitten sind. Finanzunternehmen nutzen es, um Finanzdaten zu erfassen und Modelle zur Steuerung der Investitionstätigkeit auszuführen. Konsumgüterhersteller nutzen sie, um Kundendaten zu sammeln und Trends zu prognostizieren, um Bestandsentscheidungen zu treffen und neue Marktchancen zu erkennen.
Große Unternehmen, die mit Big-Data-Anwendungen arbeiten, nutzen Spark aufgrund seiner Geschwindigkeit und seiner Fähigkeit, verschiedene Arten von Datenbanken miteinander zu verbinden und verschiedene Arten von Analyseanwendungen auszuführen. Zum Zeitpunkt der Erstellung dieses Dokuments ist Spark die größte Open-Source-Community im Bereich Big Data mit über 1.000 Mitwirkenden aus über 250 Organisationen.






