
Machine-Learning-Modelle mit DataRobot Core entwickeln
Mit DataRobot Core erhalten Data Scientists eine Sammlung von Tools, mit denen sich KI- und Machine-Learning-Lösungen entwickeln und umsetzen lassen.

DataRobot Core ist eine Sammlung von Tools, die Data Scientists dabei unterstützen, KI- und Machine-Learning-Projekte mit wenig Aufwand und Code umzusetzen.
Vor allem für Machine-Learning-Software kann DataRobot Core schnellere Ergebnisse erreichen. Parallel dazu stellt DataRobot die AI Cloud zur Verfügung. Mit dem AI Builder ist es möglich, Modelle zum maschinellen Lernen zu entwickeln. Die Verwendung der Tools ist ohne Programmierkenntnisse möglich. Die Tools von DataRobot lassen sich kostenlos in der Cloud testen, dazu ist lediglich ein Konto beim Anbieter notwendig.
DataRobot Core in der Cloud verwenden
Nach der Anmeldung bei DataRobot stehen 20.000 Credits kostenlos zur Verfügung. Diese können von Entwicklern verwendet werden, um Daten für die Analyse vorzubereiten, Machine-Learning-Umgebungen zu planen oder -Prozesse zu verwalten. Die Konfiguration dazu erfolgt auf der Weboberfläche.
Ein Vorteil bei der Verwendung der Cloud-Plattform von DataRobot besteht darin, dass die Nutzung einheitlich ist. Da keine lokale Installation notwendig ist, können die Tools auf Windows, Linux, macOS, Tablets und Smartphones verwendet werden.
Die Datenquellen lassen sich direkt auf der Webseite auswählen. Hier stehen zum Beispiel Azure SQL, Oracle, PostgreSQL, MySQL, AWS Athena, Google Big Query oder Microsoft SQL Server zur Verfügung. Snowflake, SAP HANA und verschiedene Treiber lassen sich benutzerdefiniert verbinden. Unter Data Connections\Select Data Store unterstützt ein Assistent bei der Auswahl und Einrichtung. Hier werden die Anmeldedaten und die Verbindungsinformationen für die Quelle gesteuert.

Apache Spark und offene API-Schnittstelle
Die Plattform bietet Code-zentrierte Pipelines auf Basis von Apache Spark sowie die Möglichkeit, eigene Anwendungen über die APIs von DataRobot Core anzubinden. Daneben lassen sich externe Bibliotheken verknüpfen, vor allem aus dem Bereich der KI-Entwicklung. Auf der Plattform werden zudem verschiedene Datentypen unterstützt.
Anomalieerkennung ist in DataRobot Core ebenfalls möglich. Dazu kommen Tools für multimodales Clustering, segmentierte Zeitserienmodellierung und Multilabel-Klassifizierungen zum Einsatz. Diese Funktionen erlauben Machine-Learning-Modelle, die komplexe Regeln und Geschäftslogiken mit Post-Process-Vorhersageergebnissen kombinieren.
DataRobot Core in AWS und Microsoft Azure
Eine große Stärke von DataRobot Core liegt darin, dass die Tools über die Cloud funktionieren. Das ermöglicht nicht nur das Anbinden von Datenquellen aus der Cloud, zum Beispiel aus AWS, Microsoft Azure oder SAP HANA (Cloud). Es ist außerdem möglich, weitere Dienste aus der Cloud zu nutzen sowie KI- oder Machine-Learning-Anwendungen bereitzustellen und zu verwalten. Mit der Plattform entwickeln Data Scientists nicht nur Modelle, sondern sie können externe Modelle und Plattformen anbinden und überwachen. Vor allem in IoT-Infrastrukturen ist das eine Option, die flexible und skalierbare Umgebungen erlaubt.
DataRobot setzt hierfür auf Kubernetes, zum Beispiel mit Azure Kubernetes Services (AKS). Dadurch ist es möglich, Machine-Learning-Modelle auf Azure Kubernetes Services zum Beispiel für Scoring-Pipelines mit DataRobots MLOps Portable Prediction Servers (PPS) bereitzustellen.
DataRobot Automated Machine Learning kann hierfür einen dedizierten Prediction-Server einrichten, der eine synchrone REST API für Echtzeitvorhersagen zur Verfügung stellt. DataRobot MLOps PPS ist eine Erweiterung dieser Funktionalität, mit der das Machine-Learning-Modell in einem Container-Image arbeitet.
Die Datenquellen lassen sich in solchen Szenarien über URLs anbinden, zum Beispiel aus Datenspeichern wie Amazon S3. Das funktioniert ebenfalls auf Kubernetes-Clustern mit AKS. Die zu importierenden Daten können direkt auf der Plattform von DataRobot eingelesen werden. Für Testzwecke stellt der Anbieter Beispieldaten zur Verfügung. Dazu muss bei der Datenquelle die URL der Daten eingegeben werden.
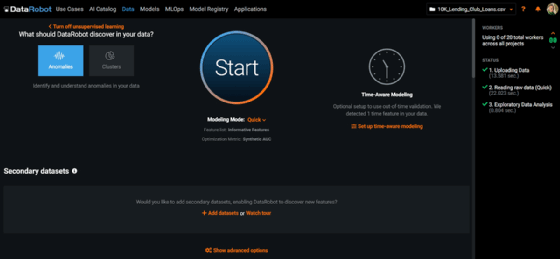
Das Modell selbst lässt sich mit der Schaltfläche Start anstoßen. Hier nutzt DataRobot Core die Daten aus der angebundenen Quelle, zum Beispiel aus Trainingsdaten (CSV-Datei). Ergebnis ist ein MLOps-Package als *.mlpg-Datei. Diese steht unter Predict\Downloads zur Verfügung. Mit Generate & Download erfolgt der Download der Datei. Auf Basis dieser Datei lässt sich wiederum ein Image für den Portable Prediction Server (PPS) erstellen.
Das Image kann mit Docker in die Azure Container Registry geladen und danach als Container über Azure Kubernetes Services genutzt werden. Die Bereitstellung erklärt DataRobot in einem Blogbeitrag.
Über AWS kann im Marketplace eine komplette Umgebung gebucht werden, die aus sechs Knoten und der notwendigen Software von DataRobot besteht. Die Bereitstellung ist in diesem Fall einfach, da die Software-as-a-Service-Lösung im Marketplace lediglich gebucht und aktiviert wird.





