Rekurrentes neuronales Netz (RNN)

Ein rekurrentes neuronales Netz oder rückgekoppeltes neuronales Netz (Recurrent Neural Network, RNN) ist eine Art künstliches neuronales Netz (KNN), das häufig in der Spracherkennung und der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) eingesetzt wird. Rekurrente neuronale Netze erkennen die sequentiellen Merkmale von Daten und verwenden Muster, um das nächste wahrscheinliche Szenario vorherzusagen.
RNNs werden beim Deep Learning und bei der Entwicklung von Modellen verwendet, die die Neuronenaktivität im menschlichen Gehirn simulieren. Sie sind besonders leistungsfähig in Anwendungsfällen, in denen der Kontext für die Vorhersage eines Ergebnisses entscheidend ist. Sie unterscheiden sich auch von anderen Arten künstlicher neuronaler Netze, da sie Rückkopplungsschleifen verwenden, um eine Datenfolge zu verarbeiten, die die endgültige Ausgabe beeinflusst. Diese Rückkopplungsschleifen ermöglichen es, dass Informationen erhalten bleiben. Dieser Effekt wird oft als Gedächtnis beschrieben.
RNN-Anwendungsfälle sind in der Regel mit Sprachmodellen verbunden, bei denen die Kenntnis des nächsten Buchstabens in einem Wort oder des nächsten Wortes in einem Satz von den vorhergehenden Daten abhängt. Ein überzeugendes Experiment beinhaltet ein RNN, das mit den Werken von Shakespeare trainiert wurde, um erfolgreich Shakespeare-ähnliche Prosa zu produzieren. Das Schreiben durch RNNs ist eine Form der Computerkreativität. Diese Simulation menschlicher Kreativität wird durch das Verständnis der künstlichen Intelligenz (KI) für Grammatik und Semantik ermöglicht, das sie aus ihrem Trainingssatz gelernt hat.
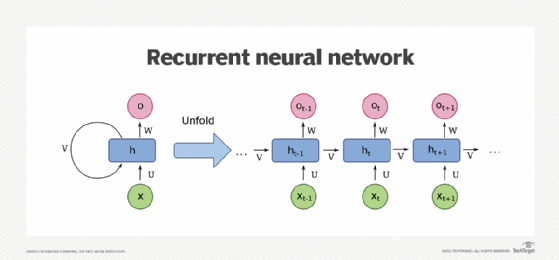
Wie rekurrente neuronale Netze lernen
Künstliche neuronale Netze bestehen aus miteinander verbundenen Datenverarbeitungskomponenten, die lose so konzipiert sind, dass sie wie das menschliche Gehirn funktionieren. Sie bestehen aus Schichten künstlicher Neuronen – Netzwerkknoten –, die in der Lage sind, Eingaben zu verarbeiten und Ausgaben an andere Knoten im Netzwerk weiterzuleiten. Die Knoten sind durch Kanten verbunden, die die Stärke eines Signals und die endgültige Ausgabe des Netzes beeinflussen.
In einigen Fällen verarbeiten künstliche neuronale Netze Informationen in einer einzigen Richtung von der Eingabe zur Ausgabe. Zu diesen Feed Forward neuronalen Netzen gehören faltende neuronale Netzwerk (Convolutional Neural Network, CNN), die Bilderkennungssystemen zugrunde liegen. RNNs hingegen können geschichtet werden, um Informationen in zwei Richtungen zu verarbeiten.
Wie Feed Forward neuronale Netzwerke können RNNs Daten von der ersten Eingabe bis zur letzten Ausgabe verarbeiten. Im Gegensatz zu Feed Forward neuronalen Netzwerken verwenden RNNs während des gesamten Rechenprozesses Rückkopplungsschleifen, wie zum Beispiel Backpropagation Through Time, um Informationen zurück in das Netz zu senden. Auf diese Weise werden die Eingaben miteinander verbunden und RNNs können sequenzielle und zeitliche Daten verarbeiten.
Ein neuronales Netz mit verkürzter Backpropagation Through Time ist ein RNN, bei dem die Anzahl der Zeitschritte in der Eingabesequenz durch eine Verkürzung der Eingabesequenz begrenzt ist. Dies ist nützlich für rekurrente neuronale Netze, die als Sequenz-zu-Sequenz-Modelle verwendet werden, bei denen die Anzahl der Schritte in der Eingangssequenz (oder die Anzahl der Zeitschritte in der Eingangssequenz) größer ist als die Anzahl der Schritte in der Ausgangssequenz.
Bidirektionale rekurrente neuronale Netze
Bidirektionale rekurrente neuronale Netze (BRNN) sind eine weitere Art von RNN, die gleichzeitig die Vorwärts- und Rückwärtsrichtung des Informationsflusses lernen. Dies unterscheidet sich von Standard-RNNs, die Informationen nur in einer Richtung lernen. Der Prozess, bei dem beide Richtungen gleichzeitig gelernt werden, wird als bidirektionaler Informationsfluss bezeichnet.
In einem typischen künstlichen neuronalen Netz werden die Vorwärtsprojektionen verwendet, um die Zukunft vorherzusagen, und die Rückwärtsprojektionen, um die Vergangenheit zu bewerten. Sie werden jedoch nicht zusammen verwendet, wie in einem BRNN.
RNN-Herausforderungen und deren Lösung
Die häufigsten Probleme bei RNNS sind das Verschwinden von Gradienten und Explosionsprobleme. Die Gradienten beziehen sich auf die Fehler, die beim Trainieren des neuronalen Netzes entstehen. Wenn die Gradienten zu explodieren beginnen, wird das neuronale Netz instabil und kann nicht mehr aus den Trainingsdaten lernen.
Einheiten mit langem Kurzzeitgedächtnis
Ein Nachteil von Standard-RNNs ist das Problem des verschwindenden Gradienten, bei dem die Leistung des neuronalen Netzes schwindet, weil es nicht richtig trainiert werden kann. Dies geschieht bei tief geschichteten neuronalen Netzen, die für die Verarbeitung komplexer Daten verwendet werden.
Standard-RNNs, die eine gradientenbasierte Lernmethode verwenden, werden mit zunehmender Größe und Komplexität immer schlechter. Die effektive Abstimmung der Parameter in den ersten Schichten wird zu zeit- und rechenaufwendig.
Eine Lösung für dieses Problem sind sogenannte LSTM-Netze (Long Short-Term Memory), die die Informatiker Sepp Hochreiter und Jürgen Schmidhuber 1997 erfunden haben. RNNs, die mit LSTM-Einheiten aufgebaut sind, kategorisieren Daten in Kurzzeit- und Langzeitspeicherzellen. Auf diese Weise können RNNs herausfinden, welche Daten wichtig sind, gespeichert werden müssen und an die Schleife im Netzwerk zurückgesendet werden sollten. Außerdem können RNNs auf diese Weise herausfinden, welche Daten vergessen werden können.
Gated Recurrent Units
Gated Recurrent Units (GRUs), zu Deutsch etwa geschlossene wiederkehrende Einheiten, sind eine Form von rekurrenten neuronalen Netzwerken, die zur Modellierung sequentieller Daten verwendet werden können. LSTM-Netzwerke können zwar auch zur Modellierung sequentieller Daten verwendet werden, sind aber schwächer als Standard-Feed-Forward-Netzwerke. Durch die gemeinsame Verwendung eines LSTM und einer GRU können Netzwerke die Stärken beider Einheiten ausspielen – die Fähigkeit, langfristige Assoziationen für das LSTM zu lernen, und die Fähigkeit, aus kurzfristigen Mustern für die GRU zu lernen.
Das mehrschichtige Perzeptron und Convolutional Neural Networks
Zu den beiden anderen Klassen künstlicher neuronaler Netze gehören mehrschichtige Perzeptronen (Multilayer Perceptrons, MLP) und faltende neuronale Netzwerk (Convolutional Neural Networks, CNN).
MLPs bestehen aus mehreren Neuronen, die in Schichten angeordnet sind, und werden häufig für Klassifizierung und Regression verwendet. Ein Perzeptron ist ein Algorithmus, der lernen kann, eine binäre Klassifizierungsaufgabe auszuführen. Ein einzelnes Perzeptron kann seine eigene Struktur nicht verändern, daher werden sie oft in Schichten zusammengefasst, wobei eine Schicht lernt, kleinere und spezifischere Merkmale des Datensatzes zu erkennen.
Die Neuronen in verschiedenen Schichten sind miteinander verbunden. So ist beispielsweise der Ausgang des ersten Neurons mit dem Eingang des zweiten Neurons verbunden, das als Filter fungiert. MLPs werden zur Überwachung des Lernprozesses und für Anwendungen wie optische Zeichenerkennung, Spracherkennung und maschinelle Übersetzung eingesetzt.
Convolutional Neural Networks sind eine Familie neuronaler Netze, die in Computer Vision eingesetzt werden. Der Begriff Faltung (Convolutional) bezieht sich auf die Faltung – den Prozess der Kombination des Ergebnisses einer Funktion mit dem Prozess ihrer Berechnung – des Eingangsbildes mit den Filtern im Netz. Die Idee ist, Eigenschaften oder Merkmale aus dem Bild zu extrahieren. Diese Eigenschaften können dann für Anwendungen wie Objekterkennung oder -findung verwendet werden.

CNNs entstehen durch einen Trainingsprozess, der den Hauptunterschied zwischen CNNs und anderen neuronalen Netztypen darstellt. Ein CNN besteht aus mehreren Schichten von Neuronen, und jede Schicht von Neuronen ist für eine bestimmte Aufgabe zuständig. Die erste Schicht von Neuronen kann für die Erkennung allgemeiner Merkmale eines Bildes zuständig sein, wie dessen Inhalt (zum Beispiel ein Hund). Die nächste Schicht von Neuronen könnte spezifischere Merkmale erkennen (zum Beispiel die Rasse des Hundes).







