Large Language Model (LLM)

Was ist Large Language Model (LLM)?
Das Large Language Model (LLM) ist eine Art von Algorithmus der künstlichen Intelligenz (KI), der Deep-Learning-Techniken und massiv große Datensätze verwendet, um neue Inhalte zu verstehen, zusammenzufassen, zu generieren und vorherzusagen. Der Begriff generative KI ist eng mit LLMs verbunden, die in der Tat eine Art von generativer KI sind, die speziell für die Generierung textbasierter Inhalte entwickelt wurde.
Im Laufe der Jahrtausende haben die Menschen gesprochene Sprachen entwickelt, um zu kommunizieren. Sprache ist das Herzstück aller Formen menschlicher und technologischer Kommunikation; sie liefert die Wörter, die Semantik und die Grammatik, die zur Vermittlung von Ideen und Konzepten erforderlich sind. In der Welt der künstlichen Intelligenz erfüllt ein Sprachmodell einen ähnlichen Zweck: Es bietet eine Grundlage für die Kommunikation und die Entwicklung neuer Konzepte.
Die ersten KI-Sprachmodelle haben ihre Wurzeln in den Anfängen der KI. Das ELIZA-Sprachmodell wurde 1966 am MIT vorgestellt und ist eines der frühesten Beispiele für ein KI-Sprachmodell. Alle Sprachmodelle werden zunächst anhand eines Datensatzes trainiert und nutzen dann verschiedene Techniken, um Beziehungen abzuleiten und auf der Grundlage der trainierten Daten neue Inhalte zu generieren. Sprachmodelle werden häufig in Anwendungen für Natural Language Processing (Verarbeitung natürlicher Sprache, NLP) verwendet, bei denen ein Benutzer eine Anfrage in natürlicher Sprache eingibt, um ein Ergebnis zu erhalten.
Ein LLM ist die Weiterentwicklung des Sprachmodellkonzepts (Language Model Concept) in der künstlichen Intelligenz, das die für das Training und die Schlussfolgerungen verwendeten Daten drastisch erweitert. Im Gegenzug werden die Fähigkeiten des KI-Modells massiv erweitert. Es gibt zwar keine allgemein anerkannte Zahl dafür, wie groß der Datensatz für das Training sein muss, aber ein LLM hat normalerweise mindestens eine Milliarde oder mehr Parameter. Parameter sind ein Begriff des maschinellen Lernens für die Variablen, die im Modell vorhanden sind, auf dem es trainiert wurde, und aus denen neue Inhalte abgeleitet werden können.
Moderne LLMs wurden 2017 entwickelt und verwenden neuronale Netze mit Transformatoren, die allgemein als Transformatoren bezeichnet werden. Mit einer großen Anzahl von Parametern und dem Transformatormodell sind LLMs in der Lage, präzise Antworten schnell zu verstehen und zu generieren, wodurch die KI-Technologie in vielen verschiedenen Bereichen breit einsetzbar ist.
Einige LLMs werden als Basismodelle bezeichnet, ein Begriff, der vom Stanford Institute for Human-Centered Artificial Intelligence im Jahr 2021 geprägt wurde. Ein Basismodell ist so groß und aussagekräftig, dass es als Grundlage für weitere Optimierungen und spezifische Anwendungsfälle dient.
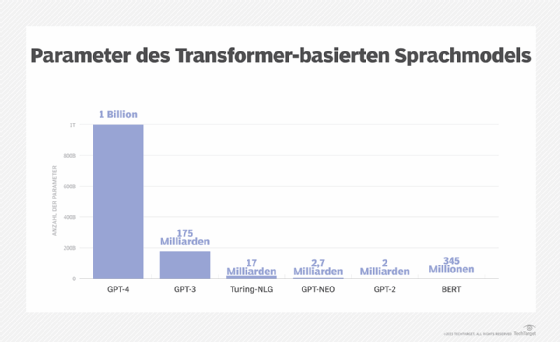
Beispiele für LLMs
Hier ist eine Liste der zehn wichtigsten LLMs auf dem aktuellen Markt, die in alphabetischer Reihenfolge auf der Grundlage von Internetrecherchen aufgeführt sind:
- Bidirectional Encoder Representations from Transformers, allgemein als Bert.
- Claude.
- Cohere.
- Enhanced Representation through Knowledge Integration, oder Ernie.
- Falcon 40B.
- Galactica.
- Generative Pre-trained Transformer 3, allgemein bekannt als GPT-3.
- GPT-3.5.
- GPT-4.
- Sprachmodell für Dialogue-Anwendungen oder Lamda.
Weitere Informationen finden Sie in diesem Artikel, der sich mit den oben genannten LLMs und anderen bekannten Beispielen befasst.
Warum werden LLMs für Unternehmen immer wichtiger?
Mit dem weiteren Wachstum der KI wird ihr Platz in der Geschäftswelt immer dominanter. Dies zeigt sich in der Verwendung von LLMs sowie von Werkzeugen für maschinelles Lernen. Bei der Erstellung und Anwendung von Modellen für maschinelles Lernen rät die Forschung, dass Einfachheit und Konsistenz zu den wichtigsten Zielen gehören sollten. Die Identifizierung der zu lösenden Probleme ist ebenso wichtig wie das Verstehen historischer Daten und die Gewährleistung der Genauigkeit.
Die mit dem maschinellen Lernen verbundenen Vorteile werden häufig in vier Kategorien eingeteilt: Effizienz, Effektivität, Erfahrung und Geschäftsentwicklung. In dem Maße, in dem sich diese Vorteile herauskristallisieren, investieren Unternehmen in diese Technologie.
Wie funktionieren Large Language Models?
LLMs verfolgen einen komplexen Ansatz, der mehrere Komponenten umfasst. Auf der Basisebene muss ein LLM mit einem großen Datenvolumen – manchmal auch als Korpus bezeichnet – trainiert werden, das in der Regel Petabytes groß ist. Das Training kann in mehreren Schritten erfolgen und beginnt in der Regel mit einem unüberwachten Lernansatz. Bei diesem Ansatz wird das Modell mit unstrukturierten Daten und unmarkierten Daten trainiert. Der Vorteil des Trainings mit unmarkierten Daten besteht darin, dass oft sehr viel mehr Daten zur Verfügung stehen. In diesem Stadium beginnt das Modell, Beziehungen zwischen verschiedenen Wörtern und Konzepten abzuleiten.
Der nächste Schritt für einige LLMs ist das Training und die Feinabstimmung mit einer Form des selbstüberwachten Lernens. Hier wurden die Daten bereits gekennzeichnet, was dem Modell hilft, verschiedene Konzepte genauer zu identifizieren.
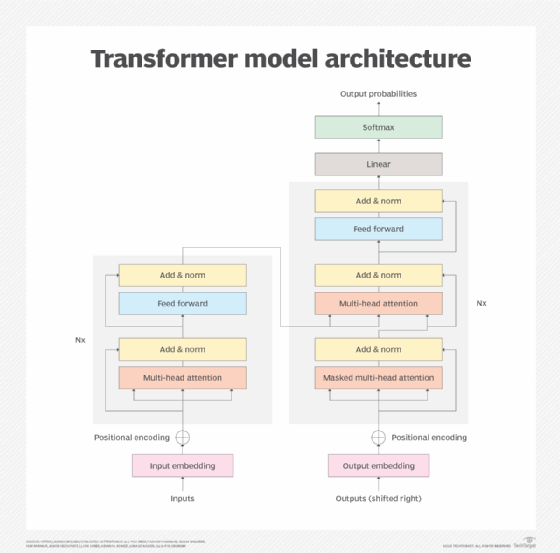
Als Nächstes führt das LLM Deep Learning durch, indem es den Prozess des neuronalen Transformer-Netzwerks durchläuft. Die Transformator-Architektur ermöglicht es dem LLM, die Beziehungen und Verbindungen zwischen Wörtern und Konzepten zu verstehen und zu erkennen, indem es einen Mechanismus der Selbstaufmerksamkeit einsetzt. Dieser Mechanismus ist in der Lage, einem bestimmten Element (Token genannt) eine Punktzahl zuzuweisen, die gemeinhin als Gewicht bezeichnet wird, um die Beziehung zu bestimmen.
Sobald ein LLM trainiert wurde, besteht eine Basis, mit der die KI für praktische Zwecke verwendet werden kann. Durch Abfrage des LLM mit einer Eingabeaufforderung kann die KI-Modellinferenz eine Antwort generieren, bei der es sich um eine Antwort auf eine Frage, einen neu generierten Text, einen zusammengefassten Text oder eine Stimmungsanalyse handeln kann.
Wofür werden Large Language Models verwendet?
LLMs erfreuen sich zunehmender Beliebtheit, da sie für eine Reihe von NLP-Aufgaben eingesetzt werden können, unter anderem für die folgenden
- Texterstellung. Die Fähigkeit, Text zu jedem Thema zu generieren, für das das LLM trainiert wurde, ist ein Hauptanwendungsfall.
- Übersetzung. Bei LLMs, die für mehrere Sprachen trainiert wurden, ist die Fähigkeit, von einer Sprache in eine andere zu übersetzen, ein gängiges Merkmal.
- Inhaltszusammenfassung. Das Zusammenfassen von Textblöcken oder mehreren Seiten ist eine nützliche Funktion von LLMs.
- Umschreiben von Inhalten. Das Umschreiben eines Textabschnitts ist eine weitere Fähigkeit.
- Klassifizierung und Kategorisierung. Ein LLM ist in der Lage, Inhalte zu klassifizieren und zu kategorisieren.
- Stimmungsanalyse. Die meisten LLMs können zur Stimmungsanalyse eingesetzt werden, um den Benutzern zu helfen, die Absicht eines Inhalts oder einer bestimmten Antwort besser zu verstehen.
- Conversational KI und Chatbots. LLMs können eine Konversation mit einem Nutzer auf eine Art und Weise ermöglichen, die typischerweise natürlicher ist als ältere Generationen von KI-Technologien.
Eine der häufigsten Anwendungen für dialogbasierte (Conversational) KI ist ein Chatbot, der in vielen verschiedenen Formen existieren kann, in denen ein Benutzer in einem Frage-und-Antwort-Modell interagiert. Einer der am häufigsten verwendeten LLM-basierten KI-Chatbots ist ChatGPT, der auf dem GPT-3-Modell von OpenAI basiert.
Was sind die Vorteile von Large Language Models?
Es gibt zahlreiche Vorteile, die LLMs für Unternehmen und Nutzer bieten:
- Erweiterbarkeit und Anpassungsfähigkeit. LLMs können als Grundlage für individuelle Anwendungsfälle dienen. Durch zusätzliches Training des LLM kann ein fein abgestimmtes Modell für die spezifischen Bedürfnisse einer Organisation erstellt werden.
- Flexibel. Ein LLM kann für viele verschiedene Aufgaben und Einsätze in verschiedenen Organisationen, Benutzern und Anwendungen verwendet werden.
- Leistung. Moderne LLMs sind in der Regel sehr leistungsfähig und können schnelle Antworten mit geringer Latenzzeit erzeugen.
- Genauigkeit. Je mehr Parameter und je größer die Menge der antrainierten Daten in einem LLM sind, desto genauer ist das Transformer-Modell.
- Einfaches Training. Viele LLMs werden mit unmarkierten Daten trainiert, wodurch der Trainingsprozess beschleunigt wird.
Was sind die Vorteile von großen Sprachmodellen?
Es gibt zahlreiche Vorteile, die LLMs für Organisationen und Nutzer bieten:
- Erweiterbarkeit und Anpassbarkeit. LLMs können als Grundlage für individuelle Anwendungsfälle dienen. Zusätzliches Training auf einem LLM kann ein fein abgestimmtes Modell für die spezifischen Bedürfnisse einer Organisation erstellen.
- Flexibel. Ein LLM kann für viele verschiedene Aufgaben und Einsätze in verschiedenen Organisationen, Benutzern und Anwendungen verwendet werden.
- Leistung. Moderne LLMs sind in der Regel sehr leistungsfähig und können schnelle Antworten mit geringer Latenzzeit erzeugen.
- Genauigkeit. Je mehr Parameter und je größer die Menge der trainierten Daten in einem LLM sind, desto genauer ist das Transformer-Modell.
- Einfaches Training. Viele LLMs werden auf nicht beschrifteten (unlabeled) Daten trainiert, was den Trainingsprozess beschleunigt.
- Effizienz. LLMs können den Mitarbeitern durch die Automatisierung von Routineaufgaben Zeit sparen.
Was sind die Herausforderungen und Grenzen von LLMs?
Die Verwendung von LLMs bietet zwar viele Vorteile, doch gibt es auch einige Herausforderungen und Einschränkungen:
- Entwicklungskosten. Für die Ausführung von LLMs sind in der Regel große Mengen an teurer Grafikprozessor-Hardware und umfangreiche Datensätze erforderlich.
- Betriebliche Kosten. Nach der Schulungs- und Entwicklungsphase können die Kosten für den Betrieb eines LLM für die Gastorganisation sehr hoch sein.
- Vorurteile (Bias). Ein Risiko bei jeder KI, die mit unmarkierten Daten trainiert wird, ist die Voreingenommenheit, da nicht immer klar ist, ob bekannte Vorurteile beseitigt wurden.
- Erklärbarkeit. Die Fähigkeit zu erklären, wie ein LLM ein bestimmtes Ergebnis erzeugen konnte, ist für die Benutzer nicht einfach oder offensichtlich.
- Halluzination. KI-Halluzinationen treten auf, wenn ein LLM eine ungenaue Antwort liefert, die nicht auf Trainingsdaten basiert.
- Komplexität. Mit Milliarden von Parametern sind moderne LLMs außerordentlich komplizierte Technologien, bei denen die Fehlerbehebung besonders komplex sein kann.
- Glitch Token. Böswillig gestaltete Eingabeaufforderungen, die zu Fehlfunktionen eines LLM führen, so genannte Glitch Token, sind Teil eines neuen Trends seit 2022.
Was sind die verschiedenen Arten von LLM?
Es gibt eine Reihe von Begriffen, die die verschiedenen Arten von Large Language Models beschreiben. Zu den gebräuchlichen Typen gehören die folgenden:
- Zero-Shot-Modell. Hierbei handelt es sich um ein großes, verallgemeinertes Modell, das mit einem generischen Datenkorpus trainiert wurde und in der Lage ist, für allgemeine Anwendungsfälle ein ziemlich genaues Ergebnis zu liefern, ohne dass ein zusätzliches Training erforderlich ist. GPT-3 wird oft als ein Zero-Shot-Modell betrachtet.
- Feinabgestimmte oder domänenspezifische Modelle. Zusätzliches Training auf der Grundlage eines Zero-Shot-Modells wie GPT-3 kann zu einem fein abgestimmten, domänenspezifischen Modell führen. Ein Beispiel ist OpenAI Codex, ein domänenspezifisches LLM für die Programmierung auf der Grundlage von GPT-3.
- Sprachrepräsentationsmodell. Ein Beispiel für ein Sprachrepräsentationsmodell ist Bidirectional Encoder Representations from Transformers (BERT), das Deep Learning und Transformatoren nutzt, die sich gut für NLP eignen.
- Multimodales Modell. Ursprünglich wurden LLMs nur auf Text abgestimmt, aber mit dem multimodalen Ansatz ist es möglich, sowohl Text als auch Bilder zu verarbeiten. Ein Beispiel hierfür ist GPT-4.
Die Zukunft der Large Language Models
Die Zukunft der LLMs wird immer noch von den Menschen geschrieben, die die Technologie entwickeln, obwohl es eine Zukunft geben könnte, in der die LLMs auch selbst schreiben. Die nächste Generation von LLMs wird wahrscheinlich keine künstliche allgemeine Intelligenz sein oder in irgendeinem Sinne des Wortes fühlen, aber sie werden sich kontinuierlich verbessern und "intelligenter" werden.
LLMs werden auch in Bezug auf die Geschäftsanwendungen, die sie bearbeiten können, weiter wachsen. Ihre Fähigkeit, Inhalte in verschiedene Kontexte zu übersetzen, wird weiter zunehmen, so dass sie wahrscheinlich von Geschäftsanwendern mit unterschiedlichen technischen Kenntnissen besser genutzt werden können.
LLMs werden weiterhin auf immer größere Datenmengen trainiert werden, und diese Daten werden zunehmend besser auf Genauigkeit und potenzielle Verzerrungen gefiltert werden, zum Teil durch die Hinzufügung von Faktenprüfungsfunktionen. Es ist auch wahrscheinlich, dass die LLMs der Zukunft bessere Arbeit leisten werden als die jetzige Generation, wenn es darum geht, Zuschreibungen vorzunehmen und besser zu erklären, wie ein bestimmtes Ergebnis zustande gekommen ist.
Die Ermöglichung genauerer Informationen durch domänenspezifische LLMs, die für einzelne Branchen oder Funktionen entwickelt wurden, ist eine weitere mögliche Richtung für die Zukunft großer Sprachmodelle. Der erweiterte Einsatz von Techniken wie dem Verstärkungslernen aus menschlichem Feedback, das OpenAI zum Trainieren von ChatGPT verwendet, könnte ebenfalls zur Verbesserung der Genauigkeit von LLMs beitragen. Es gibt auch eine Klasse von LLMs, die auf dem Konzept der Retrieval-Augmented Generation basieren - darunter Googles Realm, eine Abkürzung für Retrieval-Augmented Language Model -, die das Training und die Schlussfolgerung auf einem sehr spezifischen Datenkorpus ermöglichen, ähnlich wie ein Nutzer heute gezielt Inhalte auf einer einzelnen Website suchen kann.
Es wird auch daran gearbeitet, den Gesamtumfang und die für LLMs erforderliche Trainingszeit zu optimieren, einschließlich der Entwicklung des Llama-Modells von Meta. Llama 2, das im Juli 2023 veröffentlicht wurde, hat weniger als die Hälfte der Parameter von GPT-3 und einen Bruchteil der Anzahl von GPT-4, obwohl seine Befürworter behaupten, dass es genauer sein kann.
Auf der anderen Seite könnte die Verwendung großer Sprachmodelle zu neuen Formen der Schatten-IT in Unternehmen führen. CIOs werden Leitplanken für die Nutzung einführen und Schulungen anbieten müssen, um Datenschutzprobleme und andere Probleme zu vermeiden. LLMs könnten auch neue Herausforderungen für die Cybersicherheit schaffen, indem sie Angreifern ermöglichen, überzeugendere und realistischere Phishing-E-Mails oder andere bösartige Mitteilungen zu verfassen.
Nichtsdestotrotz wird die Zukunft von LLMs wahrscheinlich rosig bleiben, da sich die Technologie weiterhin in einer Weise entwickelt, die zur Verbesserung der menschlichen Produktivität beiträgt.





