Data Lakehouse

Ein Data Lakehouse ist eine Datenmanagementarchitektur, die die Vorteile eines herkömmlichen Data Warehouse und eines Data Lake kombiniert. Ziel ist es, den einfachen Zugriff und die Unterstützung für Unternehmensanalysen, die in Data Warehouses zu finden sind, mit der Flexibilität und den relativ geringen Kosten eines Data Lake zu verbinden.
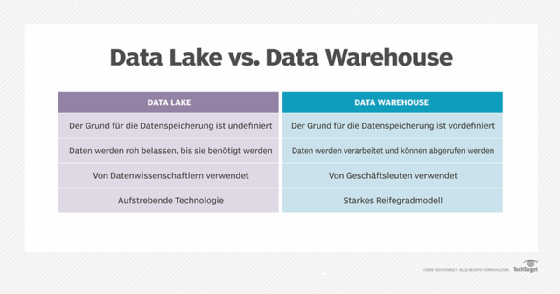
Data Warehouses wurden in den 1980er Jahren als hochleistungsfähige Speicherebene entwickelt, die Business Intelligence (BI) und Analysen unabhängig von der operativen Transaktionsdatenbank unterstützte. Data Warehouses unterstützten auch verschiedene Datenfunktionen, um Hochleistungsabfragen und ACID-Transaktionen (Atomarität, Konsistenz, Isolierung und Dauerhaftigkeit) zur Gewährleistung der Datenintegrität zu ermöglichen.
Data Lakes entwickelten sich in den frühen 2000er Jahren aus Apache Hadoop. Sie bieten eine kostengünstige Speicherebene für unstrukturierte und semistrukturierte Daten, welche die Kosten für die Erfassung großer Datenmengen reduziert. Aufgrund der Art und Weise, wie die Daten verwaltet und geändert werden, haben sie in der Regel Probleme mit Leistung, Datenqualität und Inkonsistenz.
Data Lakes und Data Warehouses erfordern unterschiedliche Prozesse für die Erfassung von Daten aus operativen Systemen und deren Übertragung in die Zielschicht. Die Aufrechterhaltung getrennter Systeme führt zu erheblichen Investitionskosten, laufenden Betriebskosten und einem hohen Verwaltungsaufwand. Daher begannen Unternehmen mit der Entwicklung einer zweistufigen Architektur, bei der die Daten zunächst in einem Data Warehouse erfasst werden. Anschließend werden die Daten durch Extrahieren, Transformieren und Laden oder Extrahieren, Laden und Transformieren (ETL und ELT) in ein strukturiertes SQL-Format umgewandelt, das für das Data Warehouse geeignet ist. Diese mehrstufige Architektur führt jedoch zu Verzögerungen, Komplexität und zusätzlichem Overhead.
Ein Data Lakehouse nutzt mehrere Verbesserungen in den Bereichen Datenarchitekturen, Datenverarbeitung und Metadatenmanagement, um alle Daten auf einer gemeinsamen Datenplattform zu erfassen, die effizient für maschinelles Lernen und BI-Anwendungen genutzt werden kann.
Welche Probleme Data Lakehouses lösen
Data Lakehouses lösen vier Hauptprobleme der traditionellen zweistufigen Architektur, die getrennte Data-Lake- und Data-Warehouse-Ebenen umfasst:
- Die Zuverlässigkeit wird verbessert, da Unternehmen die Brüchigkeit von technischen ETL-Datentransfers zwischen Systemen reduzieren, die aufgrund von Qualitätsproblemen entstehen können.
- Die Datenalterung wird reduziert, da die Daten innerhalb weniger Stunden für Analysen zur Verfügung stehen, während die Übertragung neuer Daten in das Data Warehouse manchmal mehrere Tage dauerte.
- Fortgeschrittene Analysen, die auf herkömmlichen Data Warehouses nicht gut funktionierten, können mit TensorFlow, PyTorch und XGBoost auf Betriebsdaten ausgeführt werden.
- Die Kosten sinken, da Unternehmen die laufenden ETL-Kosten verringern und eine einzige Ebene im Vergleich zu zwei separaten Ebenen nur die Hälfte an Speicherplatz benötigt.
Funktionsweise eines Data Lakehouse
Ein Data Lakehouse löst mehrere zentrale Probleme im Zusammenhang mit der Organisation von Daten, um die Verwendungszwecke von herkömmlichen Data Lakes und Data Warehouses effizient zu unterstützen. Data Lakehouses bieten folgende Funktionen:
Datenmanagement. Ein Data Lakehouse muss die Vorteile der einfachen Aufnahme von Rohdaten mit der Organisation der Daten durch ETL-Prozesse für Hochleistungs-BI kombinieren. Traditionelle Data Lakes organisierten die Daten mit Unterstützung von Parquet- oder Optimized-Row-Columnar-Dateisystemen (ORC). Neuere Open-Source-Technologien wie Delta Lake und Apache Iceberg unterstützen ACID-Transaktionen für diese Big-Data-Workloads.
Unterstützung für künstliche Intelligenz (KI) und maschinelles Lernen. Tools für Machine Learning und Data Science haben traditionell die Dateiformate ORC und Parquet unterstützt. Diese Tools führen auch DataFrames ein, die die Optimierung von Daten für neue Modelle im laufenden Betrieb erleichtern können.
SQL-Tuning. Traditionelle Data Warehouses waren in der Lage, die Datenstrukturen von SQL-Daten für gängige Abfragen fein abzustimmen. Data Lakehouses können das Datenlayout für herkömmliche Data-Warehouse-Dateiformate wie ORC und Parquet mit Tools wie Databricks Delta Engine optimieren.
Zu den Merkmalen eines Data Lakehouse gehören:
- Kostengünstiger Objektspeicher. Ein Data Lakehouse muss in der Lage sein, Daten auf einem kostengünstigen Objektspeicher zu speichern, zum Beispiel Amazon Simple Storage Service (S3), Azure Blob Storage, Google Cloud Storage oder nativ mit ORC oder Parquet.
- Transaktionsbezogene Metadatenschicht. Dies ermöglicht die Anwendung von Datenmanagementfunktionen, die für die Leistung des Data Warehouse wichtig sind, zusätzlich zum kostengünstigen Rohdatenspeicher.
- Fähigkeiten zur Datenoptimierung. Ein Data Lakehouse muss in der Lage sein, die Daten so zu optimieren, dass das Datenformat unverändert bleibt, zum Beispiel durch Optimierung des Datenlayouts, Caching und Indizierung.
- Deklarative DataFrame-API-Unterstützung. Die meisten KI-Tools können mit Unterstützung von DataFrames auf Rohdaten aus Objektspeichern zugreifen. Die deklarative DataFrame-API-Unterstützung bietet die Möglichkeit, die Struktur und Darstellung der Daten als Reaktion auf eine bestimmte Data-Science- oder KI-Arbeitslast im laufenden Betrieb zu optimieren.
Vor- und Nachteile von Data Lakehouses
Der Hauptvorteil eines Data Lakehouse besteht darin, dass es die gesamte Data-Engineering-Architektur vereinfachen kann, indem es eine einzige Staging-Ebene für alle Daten und alle Arten von Anwendungen und Anwendungsfällen bereitstellt. Dies kann die Kosten senken, da die Teams nur eine einzige Datenquelle verwalten müssen.
Der größte Nachteil von Data Lakehouses besteht darin, dass es sich um eine neue Art von Architektur handelt. Es ist nicht klar, ob die Unternehmen die Vorteile einer einheitlichen Plattform, die sich im Laufe der Zeit nur schwer ändern lässt, auch wirklich auskosten können. Außerdem müssen die Data-Engineering-Teams neue Fähigkeiten erwerben, die mit dem Betrieb einer komplexeren Metadatenmanagementschicht verbunden sind, die Daten im laufenden Betrieb organisieren und optimieren kann. Data Scientists müssen neue Fähigkeiten im Zusammenhang mit der Optimierung ihrer deklarativen DataFrame-Abfragen erlernen, um die Vorteile der neuen Architektur nutzen zu können.
Data Lakehouse versus Data Warehouse versus Data Lake
Data Lakehouses unterscheiden sich von Data Warehouses und Data Lakes dadurch, dass bei einem Data Lakehouse alle Daten auf einer Ebene bereitgestellt werden können. Die Daten können dann im laufenden Betrieb für verschiedene Arten von Abfragen sowohl für strukturierte als auch für unstrukturierte Daten optimiert werden.
Bei Data Warehouses müssen alle Daten eine ETL/ELT-Phase durchlaufen, um die Daten zu optimieren, während sie in die Speicherebene geladen werden. Dies führt jedoch zu einer schnelleren Leistung beim Lesen für SQL-Analyseanwendungen wie Business Intelligence.
Mit einem Data Lake können alle Rohdaten in einem einzigen Objektspeicher erfasst und dann beim Lesen strukturiert werden. Dies verbessert die Kosten für die Erfassung mehrerer Arten von Strukturen, also semistrukturierten und unstrukturierten Daten. Allerdings kann dies auch die Leistung von Anwendungen verringern und zu Problemen mit der Datenqualität führen.







