Datenkatalog (Data Catalog)

Ein Datenkatalog ist eine Softwareanwendung, die ein Inventar der Datenbestände eines Unternehmens erstellt, damit Datenexperten und Geschäftsanwender relevante Daten für Analysezwecke finden können. Er hilft auch bei der Datenverwaltung, indem er Verwaltungsrichtlinien und -kontrollen, Datenqualitätsregeln, ein Geschäftsglossar mit allgemeinen Begriffen und andere Informationen enthält, die sicherstellen sollen, dass die Daten richtig verwendet werden.
Datenkataloge beruhen auf Metadaten, die zur Erstellung des Dateninventars verwendet werden. Die zugrundeliegenden Metadaten liefern auch kontextbezogene Informationen über Datenbestände, die den Katalogbenutzern helfen, die in den IT-Systemen verfügbaren Daten zu verstehen und zu entscheiden, ob sie ihren Anforderungen entsprechen.
Die Verwendung von Datenkatalogen nimmt zu, da sich Unternehmen immer mehr auf Datenanalysen stützen, um Geschäftsstrategien und -abläufe voranzutreiben. Kataloge sind heute eine Kernkomponente vieler Datenverwaltungsumgebungen, und das Marktforschungsunternehmen IDC hat prognostiziert, dass der weltweite Umsatz mit Datenkatalogsoftware von 2020 bis 2025 mit einer durchschnittlichen jährlichen Wachstumsrate von 16,8 Prozent steigen wird.
Wie funktionieren Datenkataloge?
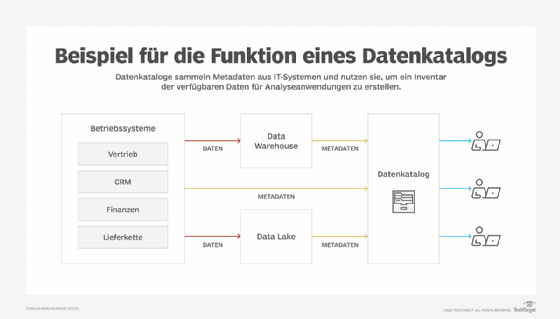
Ein Datenkatalog sammelt Metadaten aus verschiedenen Quellsystemen sowie aus Data Warehouses und Data Lakes, die Business-Intelligence (BI)-, Analyse- und Data-Science-Anwendungen unterstützen. Integrierte Funktionen zur Verwaltung von Metadaten organisieren und reichern die Metadaten an, um sie für die Endbenutzer nutzbar zu machen. Beispielsweise können Dateneinträge mit Tags versehen werden, um weitere Informationen zu ihnen hinzuzufügen, wie etwa Datenklassifizierungseinstellungen, Datenqualitätsbewertungen und Nutzungsmetriken. Zunehmend werden Algorithmen der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML) eingesetzt, um Metadaten automatisch zu erfassen, zu katalogisieren, zu klassifizieren und zu kennzeichnen.
Der Datenbestand in einem Katalog ist durchsuchbar; in der Regel können Benutzer nach Geschäftsbegriffen, technischen Namen, Tags und anderen Schlüsselwörtern oder über natürlich-sprachliche Abfragen (natural language) suchen. Datenkataloge bieten auch automatische Suchempfehlungen, ähnlich wie normale Suchmaschinen. Alternativ können die Benutzer in einem Katalog nach Daten suchen, die ihren Anwendungsanforderungen entsprechen. Insgesamt sind Kataloge so konzipiert, dass sie ein „Daten-Shopping“-Erlebnis vermitteln.
Um den Benutzern das Verständnis der Daten zu erleichtern, enthalten Kataloge Details zur Datenherkunft, zum Beispiel wo die Daten erstellt werden, wie sie durch die IT-Systeme fließen und für verschiedene Zwecke umgewandelt werden. Außerdem bieten sie Funktionen zur Datenkuratierung, mit denen Datenverwaltungs- und Analyseexperten Datensätze für ihre eigenen Anwendungen oder für den Zugriff anderer Benutzer organisieren können. Funktionen zum Hinzufügen von Kommentaren, Rezensionen und Bewertungen zu Dateneinträgen sind ebenfalls häufig integriert, ebenso wie Chat-Funktionen und andere Tools zur Zusammenarbeit.
Arten von Metadaten in Datenkatalogen
In Datenkatalogen werden verschiedene Arten von Metadaten erfasst, um ein breites Spektrum an Informationen über die dort aufgeführten Datenbestände bereitzustellen. Im Folgenden werden die drei wichtigsten Arten von Metadaten beschrieben, die in einem Datenkatalog verwendet werden.
Technische Metadaten. Sie werden manchmal auch als strukturelle Metadaten bezeichnet und liefern Informationen über die technische Struktur der Daten. Technische Metadaten beschreiben zum Beispiel die Schemata, Tabellen, Spalten, Indizes, Dateinamen und andere Objekte in Datenbanken und Data Warehouses. Sie geben auch an, wo sich die Daten in IT-Systemen befinden, und dokumentieren Dinge wie Datentypen, Datenmodelle und Skripte zur automatischen Datenumwandlung.
Operative Metadaten. Sie beschreiben, wie Datenbestände erstellt, aktualisiert, geändert und verwendet werden, wann Daten verarbeitet oder geändert wurden und wer sie aktualisiert oder transformiert hat. Die Metadaten können auch die Namen von Dateneigentümern und Datenverwaltern, Statistiken über die Datennutzung und Details über Datenzugriffsrechte und -beschränkungen enthalten. Sie werden manchmal auch als Prozess-Metadaten bezeichnet, obwohl sie auch als Teilmenge der operativen Metadaten betrachtet werden, die sich auf die Schritte der Datenverarbeitung, -verwaltung und -analyse konzentrieren.
Geschäftliche Metadaten. Sie geben den Daten einen geschäftlichen Kontext und eine Bedeutung, die den Katalogbenutzern helfen, sie zu verstehen. Dazu gehören zum Beispiel interne Datendefinitionen und relevante Geschäftsbegriffe, wie sie in Geschäftsglossaren aufgeführt sind. Auch andere geschäftliche Schlüsselwörter können hinzugefügt werden. Datenklassifizierungen, Geschäftsregeln und Informationen über die Geschäftsbereiche, in denen die Daten erstellt wurden, sowie ihre Eignung für bestimmte Verwendungszwecke sind ebenfalls Beispiele für geschäftliche Metadaten.
Datenkatalogbenutzer und Anwendungsfälle
Ein Datenkatalog wird von verschiedenen Personen in einer Organisation genutzt. Auf der Endnutzerseite sind dies Data Scientists, andere Datenanalysten, Dateningenieure und Mitglieder von BI-Teams sowie Geschäftsanalysten, Führungskräfte und Manager, die Daten analysieren möchten. Datenverwalter und andere Mitglieder von Data-Governance-Teams verwenden Datenkataloge ebenfalls als Teil des Governance-Prozesses. Darüber hinaus werden sie von Verantwortlichen für die Einhaltung gesetzlicher Vorschriften und das Risikomanagement verwendet, um zu verfolgen, wie Datenbestände verwaltet und verwendet werden.
Im Folgenden werden einige häufige Anwendungsfälle für Datenkataloge aufgeführt.
Datenermittlung (Data Discovery). Wie bereits erwähnt, besteht der Hauptzweck eines Datenkatalogs darin, Analyseanwendern zu helfen, die benötigten Daten zu finden. Ohne einen solchen Katalog kann die Datenermittlung ein mühsamer, zeitaufwändiger Prozess sein - einer der Gründe für die Maxime, dass Datenwissenschaftler 80 Prozent ihrer Zeit mit der Suche und Vorbereitung von Daten und nur 20 Prozent mit deren Analyse verbringen. Noch schlimmer ist, dass sie möglicherweise einige relevante Daten gar nicht kennen, was die Genauigkeit der Analysen beeinträchtigen kann. Ein Datenkatalog soll die Datenermittlung rationalisieren und effektiver machen.
Self-Service-Analysen und BI. Die Datenermittlung ist eine Vorstufe zum Analyseprozess. Mit Hilfe eines Datenkatalogs ist es für Datenwissenschaftler und Analysten viel einfacher, maschinelles Lernen, prädiktive Modellierungund andere fortschrittliche Analyseanwendungen durchzuführen, ohne dass sie die Unterstützung der IT- und Datenverwaltungsteams benötigen. Ebenso sind Geschäftsanwender besser in der Lage, selbständig auf Datensätze zuzugreifen und diese für Self-Service-BI-Anwendungen zu analysieren.
Daten-Governance und -Verwaltung. Ein Datenkatalog kann Data-Governance-Managern und Datenverwaltern dabei helfen, sicherzustellen, dass Benutzer die Governance-Richtlinien und -Verfahren einhalten. So können sie beispielsweise Richtlinien in einem Katalog definieren, Data-Governance-Workflows automatisieren und Änderungen an Datensätzen und Benutzerzugriffskontrollen verfolgen. Das Geschäftsglossar trägt ebenfalls zu einer effektiven Data Governance bei, und die integrierten Qualitätsbewertungs- und Überwachungsfunktionen können die damit verbundenen Initiativen zur Verbesserung der Datenqualität unterstützen.
Datenkuratierung. Durch die Verwendung eines Datenkatalogs zur Kuratierung von Datensätzen für die Analyse können Datenkuratoren den Analyseprozess weiter rationalisieren und sicherstellen, dass alle für Anwendungen benötigten Daten enthalten sind. Dies ist besonders hilfreich bei Analyseanwendungen, die wiederholt ausgeführt werden; außerdem können kuratierte Datensätze für andere Zwecke wiederverwendet werden. In einigen Unternehmen ist der Datenkurator eine formelle Funktion. In anderen Unternehmen kann die Kuratierung von verschiedenen Datenexperten übernommen werden, darunter BI-Teams und Datenwissenschaftler, Analysten und Ingenieure.
Vorteile eines Datenkatalogs
Die meisten Unternehmen erstellen einen Unternehmensdatenkatalog, um alle ihre Datenbestände zu inventarisieren. Einige, vor allem große Unternehmen, haben möglicherweise mehrere Datenkataloge für einzelne Abteilungen und Geschäftsbereiche. In beiden Fällen kann ein Datenkatalog folgende Vorteile bieten:
- Genauere Analysen. Ein Datenkatalog erleichtert den Anwendern das Auffinden aller relevanten Daten für Analyseanwendungen und trägt damit zur Verbesserung der Genauigkeit der Ergebnisse bei.
- Bessere Geschäftsentscheidungen. Bessere Analyseergebnisse führen zu einer fundierten Entscheidungsfindung von Führungskräften, was im Idealfall zu besseren Geschäftsstrategien und betrieblichen Entscheidungen führt.
- Produktivitätssteigerung. Ein Datenkatalog verkürzt die Zeit, die Benutzer mit der Suche nach Daten verbringen, und ermöglicht es ihnen, mehr Analysearbeit zu leisten. Außerdem können doppelte Datenumwandlungs- und -aufbereitungsaufgaben durch verschiedene Analysten vermieden werden.
- Hochwertigere und zuverlässigere Daten. Eingebettete Funktionen für Data Governance, Datenqualität und Datensicherheit helfen dabei, vertrauenswürdige Datensätze für Analyseanwender zu erstellen.
- Verbesserte Einhaltung gesetzlicher Vorschriften. Integrierte Datenklassifizierungseinstellungen, Zugriffskontrollen und Governance-Richtlinien können dazu beitragen, die Einhaltung von Datenschutzgesetzen und anderen Vorschriften zu verbessern.
- Verbesserte Analytik und geschäftliche Flexibilität. Ein Datenkatalog ermöglicht es Datenwissenschaftlern und anderen Analysten, schneller auf sich ändernde geschäftliche Anforderungen an Analysedaten zu reagieren.
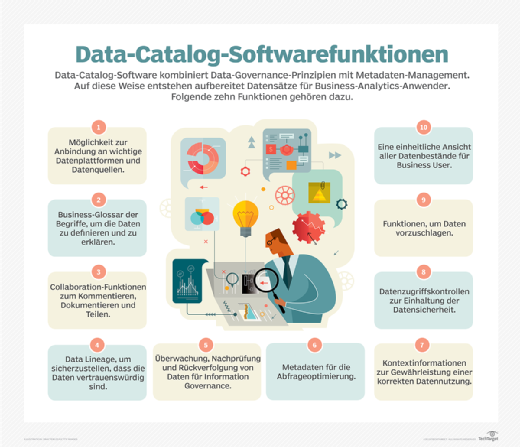
Hauptmerkmale eines Datenkatalogs
Ein Datenkatalog ist zwar in erster Linie ein Inventar von Datenbeständen, bietet aber auch eine breite Palette von Funktionen für Endbenutzer und Datenmanagement- und Governance-Teams. Die folgenden Punkte sind einige gängige Datenkatalogfunktionen:
- Konnektoren zu verschiedenen Datenquellen. Diese ermöglichen es dem Datenkatalog, Metadaten aus operativen Systemen, Data Warehouses, Data Lakes und anderen Repositories zu sammeln.
- Werkzeuge zur Verwaltung von Metadaten. Datenverwaltungsteams und andere Katalogbenutzer können diese Tools verwenden, um Metadaten zu organisieren, zu klassifizieren und anzureichern, nachdem sie in den Katalog aufgenommen worden sind.
- KI und Algorithmen für maschinelles Lernen. Das Sammeln, Katalogisieren und Markieren von Metadaten wird heute häufig durch den Einsatz integrierter KI- und maschineller Lerntechnologien automatisiert.
- Geschäftsglossar. Es enthält interne Definitionen von Geschäftsbegriffen und -konzepten, zum Beispiel was ein Kunde ist, um sie den im Katalog aufgeführten Daten-Assets zuzuordnen.
- Sie nutzen die Metadaten im Katalog, um Datenflüsse, Datentransformationen und andere historische Details über Daten zu dokumentieren und zu visualisieren.
- Um die Suche nach Daten zu erleichtern, können Benutzer den Inhalt des Datenkatalogs anhand von Schlüsselwörtern oder natürlich-sprachlichen Abfragen durchsuchen und erhalten Empfehlungen zu relevanten Daten.
- Werkzeuge für die Zusammenarbeit. Katalogbenutzer können miteinander chatten und Informationen austauschen, gemeinsam an Daten-Workflows arbeiten und Datenbestände kommentieren, überprüfen und bewerten.
- Integrierte Datenverwaltung. Eingebettete Tools unterstützen verschiedene Schritte im Data-Governance-Prozess, einschließlich Data Stewardship, Datenqualitätsmanagement und Datensicherheit.
Datenkatalog-Tools und -Anbieter
Zahlreiche Softwareanbieter offerieren Datenkatalog-Tools an, die den Aufbau und die Verwaltung von Datenkatalogen automatisieren und die oben genannten Funktionen enthalten. Im Folgenden werden einige bekannte Anbieter genannt:
- große IT-Anbieter und Cloud-Provider, wie AWS, Google Cloud, IBM, Microsoft und Oracle
- Software-Anbieter mit einem breiten Produktportfolio, das Datenmanagement- und Governance-Tools umfasst, wie Hitachi Vantara und Quest Software
- Anbieter, die sich auf Datenmanagement und Governance konzentrieren, wie Ataccama, Boomi, Collibra, Informatica und Talend
- Spezialisten für Datenkataloge und Metadatenmanagement, wie Alation, Alex Solutions, Atlan, Data.world, OvalEdge und Zeenea
- Anbieter von BI- und Analysesoftware, die entsprechende Datenkatalog-Tools haben, wie Alteryx, Qlik, Tableau und Tibco
In einem Bericht über aufkommende Datenmanagement-Technologien vom Juli 2022 erklärte das Beratungsunternehmen Gartner, dass sich KI-gesteuerte Datenkatalog-Tools - oder erweiterte Datenkatalogisierungs- und Metadatenmanagement-Lösungen, wie sie jetzt genannt werden - in der „frühen Mainstream“-Reifephase befinden. Sie werden wahrscheinlich erst in zwei bis fünf Jahren vollständig ausgereift sein, fügte Gartner hinzu. Das Unternehmen stufte die Tools jedoch hinsichtlich des potenziellen Nutzens für die Anwenderunternehmen mit „hoch“ ein.
Alternativ gibt es verschiedene Open-Source-Datenkatalog-Tools, die Unternehmen nutzen können. Beispiele sind Amundsen, Apache Atlas, DataHub und Metacat.





