Confluent Current 2023: A journey around the data streaming universe

Data streaming company staged the Current 2023 conference and exhibition this month in the heart of Silicon Valley in San Jose. Keen to explain how its platform has expanded its core functionalities, been more closely aligned and partnered with key AI services and vector database partners and positioned itself for modern cloud-native network applications and services, the Computer Weekly Open Source Insider team was there.
After a customary breakfast of breakfast burritos, attendees headed to the main keynote.
Jay Kreps, co-founder and CEO at Confluent took the main stage and said that – with this only being the second ever staging of Current (the previous event was known as Kafka Summit) – the team wanted to widen and broaden the church.
“The work that I did on Kakfa in the early days was driven by a disconnect. I was working at LinkedIn and all the data was being generated in real-time – but (back in the day) all the most sophisticated data processing was happening in [overnight] batch processing – and this was at odds with the way modern businesses like the one I worked in (and others) were being run,” said Kreps.
But there was a wider evolution that needed to happen here…
Not niche
The Confluent CEO spoke further about the evolution of streaming and explained how he had conversations with colleagues on the subject – where many people thought of streaming as something that was a rather niche application of computer science.
“When we looked at the technologies that were out there at the time, there were tools for processing data in the past (all processing on which would essentially be old) and there were tools that would look at future data (which would really focus on new requests without all the context provided by historical data)… so Kakfa was initially a kind of generalisation idea i.e. take the old data and also be able to provide sophisticated processing on data that is story BUT ALSO be able to work on newly created data as it arrives,” said Kreps.
He uses the term generalisation here not to downgrade streaming into some kind of average-based tool, but to elevate it as what he calls a ‘superset’ of processing that would be fast enough to work on scaled, durable, dependable processing capable of being applied to multiple data streams in transactional systems.
The world of stream processing grew up around these ideas – and when people still thought that batch processing was more efficient Kreps said that he always thought that was a strange idea to propose, especially if you look at the architectural functions of how a data warehouse works, which always involves transports and time.
Welcoming the next speaker, Kreps welcomed Joseph (Joe) Foster, cloud computing programme manager, NASA. Foster said that his job had always been focused on building paths that would allow NASA to migrate to cloud-native services.
With NASA now wining the data streaming company of the year last year, Foster said that NASA teams are now moving to petabyte scale science and also working to get out of the team-specific mission-specific system builds that had typified the past to now embrace cloud-native surfaces and, actually, save US taxpayers a lot of money.
NASA’s own ‘data and reasoning fabric’ is a new initiative that the team also encourage technologists to look up.
Confluent CPO: streaming essentials
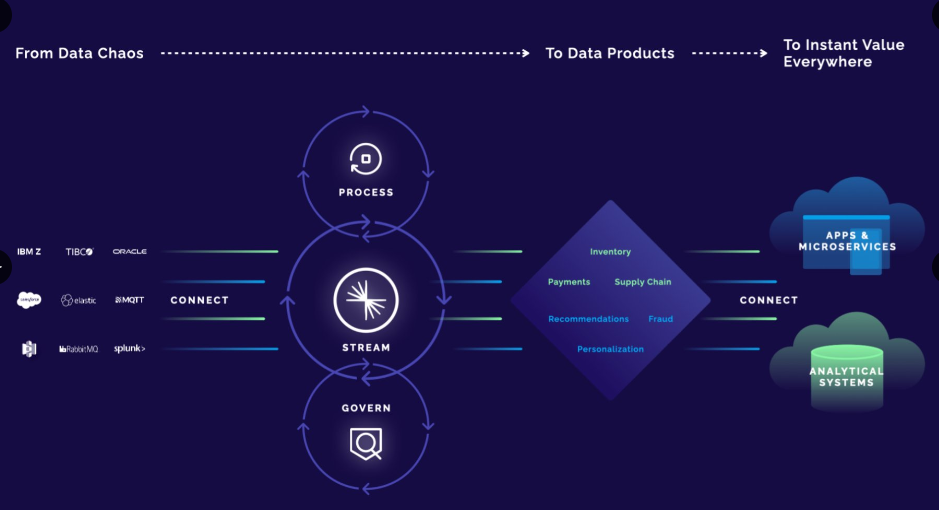
Shaun Clowes, chief product officer at Confluent said that data exists in both the operational estate and analytical estate of any given company. Connecting these two estates used to be done by simply writing a little code – but today things are getting a whole lot more complex with the operational estate in any given business now constantly standing up new applications – with the analytical estate also expanding by creating new data warehouses and demanding new analytical tools, things have become a lot more complex today.
“Data no longer flows in simple streams from the operational estate to the analytical estate, it flows back and forth far more frequently and in both directions like a real central nervous system,” said Clowes. “In order to be able to work with data flows – don’t think about data in terms of its transports and its journey from A to B, it’s more essential to think about what an organisation’s data really is. Once we know that, data actually becomes and [contextually specific] data asset – and today the industry is calling this the creation of ‘data products’.”
These so-called data products are more than the sum of their parts and they represent assets that Clowes says create real business value. These are ‘living data products’ that can be combined and reshaped to create new data services. As an example, we might have data products that use streams for transportation that manage work assignments, we might then mix in other data products that serve weather or vehicle maintenance or overnight hotel information to create a real travel management data product.
The components of a data streaming platform is made up of four cornerstones:
- Stream
- Connect
- Govern
- Process
Confluent works at all of these levels with its platform delivering connectors and data product development tools designed to help fuse together the operational and analytical estates of any given organisation’s data stack.
Stream governance
An additional section on stream governance was delivered that covered: Schema registry – which provides a common language for everyone to work on with a data platform, field level encryption and Confluent Data Portal.#
With open source Kafka and other managed Kafka solutions, developers often run into problems finding and accessing the relevant data streams they need to build real-time applications and pipelines. This fragmented process wastes valuable development cycles, restricts productivity, and slows innovation.
“To address these challenges, Data Portal, an expansion of the Stream Governance suite, leverages Confluent’s Stream Catalog capabilities to simplify the developer experience. With its flexible and self-service interface, Data Portal gives teams a secure way to find and access all the data streams flowing throughout their organization, speeding up the development of real-time applications and products,” notes the company.
With an extended session devoted to Kora – a cloud data service that serves up the Kafka protocol for our thousands of customers and their tens of thousands of clusters.- this day one keynote was speedy, developer and data science-focused and with any real marketingspeak padding (okay, the speakers did elude to ‘business insights’ a few times, but – in fairness – that is what data streaming is supposed to deliver)… so, there’s lots here, almost a whole ‘stream’ of information, right?

Confluent co-founder and CEO Jay Kreps.