Smart roots, Fauna sprouts intelligent routing

Fauna is a distributed document-relational database company, delivered as a cloud API.
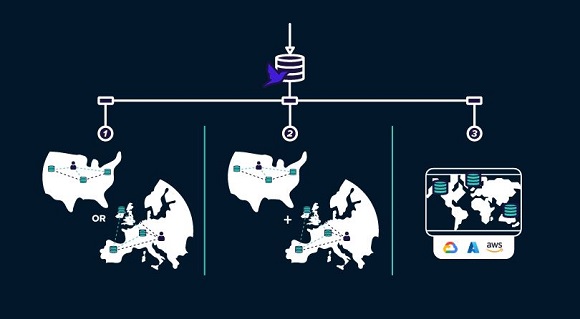
The company has this quarter introduced intelligent routing, a service intended to provide developers with a single endpoint to access any database, anywhere across Fauna’s global footprint.
All applications built on or migrated to Fauna use intelligent routing to scale applications globally while staying compliant with data residency requirements.
This new offering determines the most efficient way to route requests and queries to databases across geographies and cloud providers.
Developers will of course today face challenges navigating data sovereignty, security and consistency, especially as their applications scale across regions.
Typically, addressing each requires manual intervention immediately and over time, adding costs and decreasing productivity. Fauna exists to eliminate this heavy-lifting.
“Thousands of development teams [use] Fauna [for] our document-relational model and low operational overhead,” said Eric Berg, CEO of Fauna. “Intelligent Routing enables us to offer developers a single endpoint to access any database across Fauna’s global footprint. This makes it easy for teams to eliminate any data-related friction as they scale applications across regions and the globe.”
Users report a strongly consistent backend with built in replication and no operational overhead resulting in a cost effective way to offer great performance globally.
Calvin calibration
Fauna’s distributed by default architecture includes a Calvin-based, distributed transaction log to provide consistent, multi-region replication. This means all data is replicated with strong consistency and built in redundancy against regional failures.
NOTE: Calvin is an open architecture, data acquisition & calibration tool.
Each query is executed on an ACID-compliant transaction. Intelligent Routing inspects queries and routes it to the appropriate geography for the target database. The query is then directed to the database that is closest to the user’s region.
The database itself has been battle tested – tens of thousands of developers have created hundreds of thousands of databases, stored hundreds of terabytes of data, and sent billions of requests to the service in production.