Endor Labs: The value of (zooming into) call graphs

This is a guest post for the Computer Weekly Developer Network written by Henrik Plate in his capacity as a security researcher at Endor Labs – a company known for its approach to ‘reachability analysis’, which is designed to give DevSecOps teams the context they need to prioritize open source risk, reduce technical debt and meet compliance objectives related to SBOMs (software bill of materials) & VEX (Vulnerability Exploitability Exchange) requirements.
Plate is an experienced software developer, architect and researcher with a focus on software security and a demonstrated history of authoring scientific papers and patents as well as developing commercial and open-source software solutions.
He previously spent nearly two decades as a researcher and software developer at SAP. His current research focuses on the security of software supply chains, including the detection, assessment and mitigation of dependencies with known vulnerabilities as well as malicious open source components.
Plate writes in full as follows…
Reusing open source software (OSS) is a very good option – developers can avoid reinventing the wheel and focus on distinguishing features.
But as breaches related to Log4Shell or Equifax demonstrate, this practice comes with security risks.
OSS is susceptible to vulnerabilities; the code within an application may be exploitable. This undermines data privacy and system integrity and may lead to dangers like ransomware.
Development organisations have taken steps to monitor OSS dependencies and vulnerabilities, but most applications contain hundreds, even thousands, of OSS components. Meanwhile, the number of disclosed vulnerabilities keeps on growing.
This makes detection and remediation very expensive, especially in reactive mode.
We can do better – call graph analysis goes beyond the granularity of entire components to evaluate actual functionality.
Developers typically use only a fraction of the code in a given dependency; if a vulnerability only affects unused code, it usually can’t be exploited. Our experiments show that 60% or more of reported vulnerabilities are in this category.
Let’s zoom into a call graph to illustrate these benefits. Imagine being a developer of the Java OSS logback-access with the tedious task of assessing whether and how vulnerable OSS functions deep inside dependencies can be invoked.
Birds-eye view
We start from a call graph in its full beauty: Figure A visualises a (relatively small) call graph generated for logback-access 1.4.6.
Its construction started from the functions included in logback-access (slightly bigger nodes highlighted in green). All the other nodes represent functions in the 24 dependencies of logback-access (those with Maven scopes compile and provided, including optional ones) that are directly or indirectly invoked by logback-access. The nodes colored in dark red, for example, belong to the component tomcat-coyote. Overall, the graph contains 14K+ nodes and 60K+ edges, which represent call relationships between functions.
It is important to understand that non-reachable functions have already been excluded, i.e., only functions that can actually be called in the context of logback-access are part of the graph.
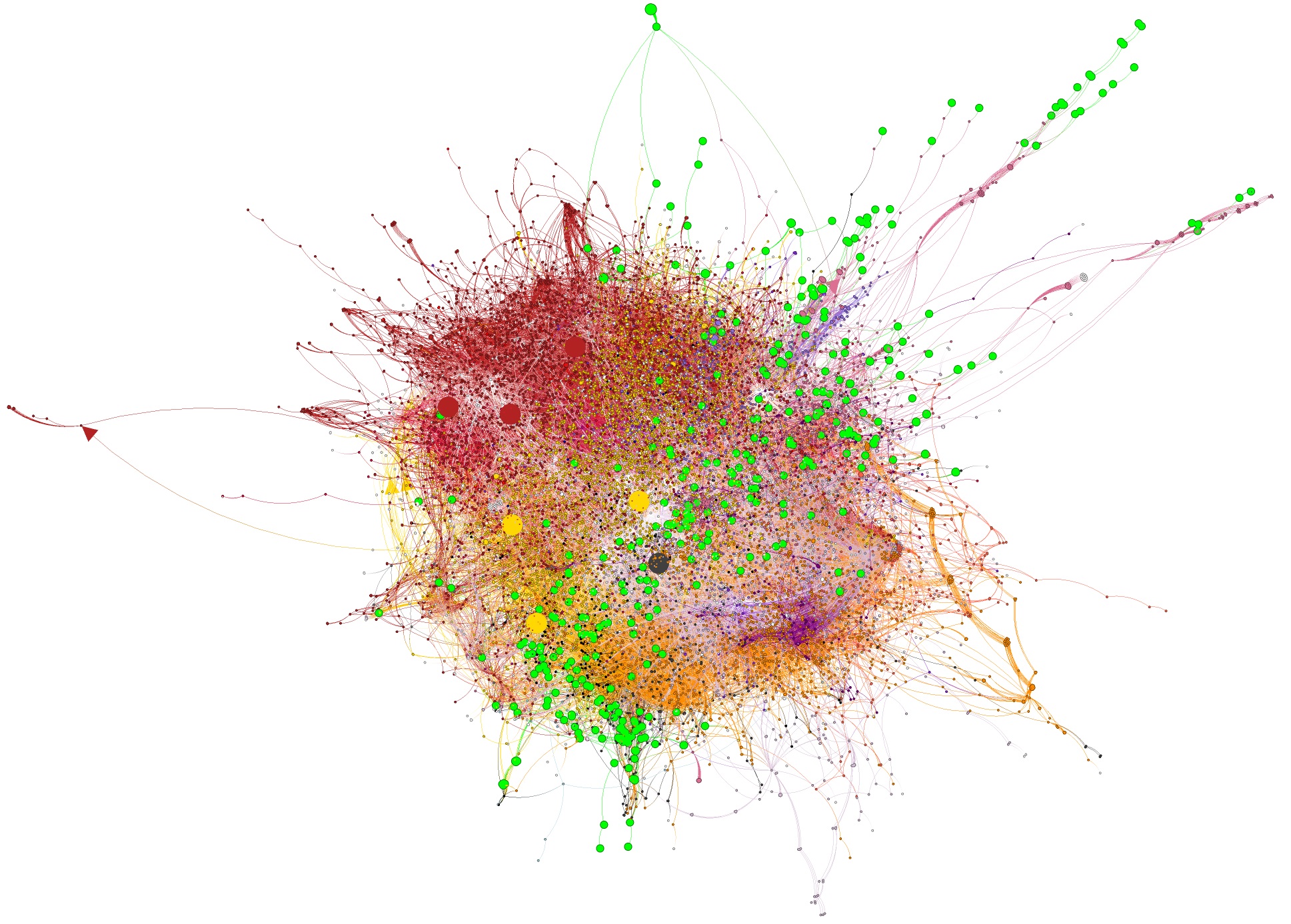
Figure A
Paths to vulnerable functions
The birds-eye is not very useful when assessing vulnerabilities. But all nodes and edges have been annotated with vulnerability information and other metadata to support fine-grained content filters. Sample metadata comprises Java function signatures, Maven artifact identifiers or a CVE identifier and CVSS score for vulnerable functions.
First, we hide all the function invocations (edges) that do not lead to vulnerable functions (Figure B). The resulting graph is more digestible and shows 7 different vulnerable functions in the (optional) dependencies of logback-access 1.4.6, each labeled with (abbreviated) function name and CVE identifier.
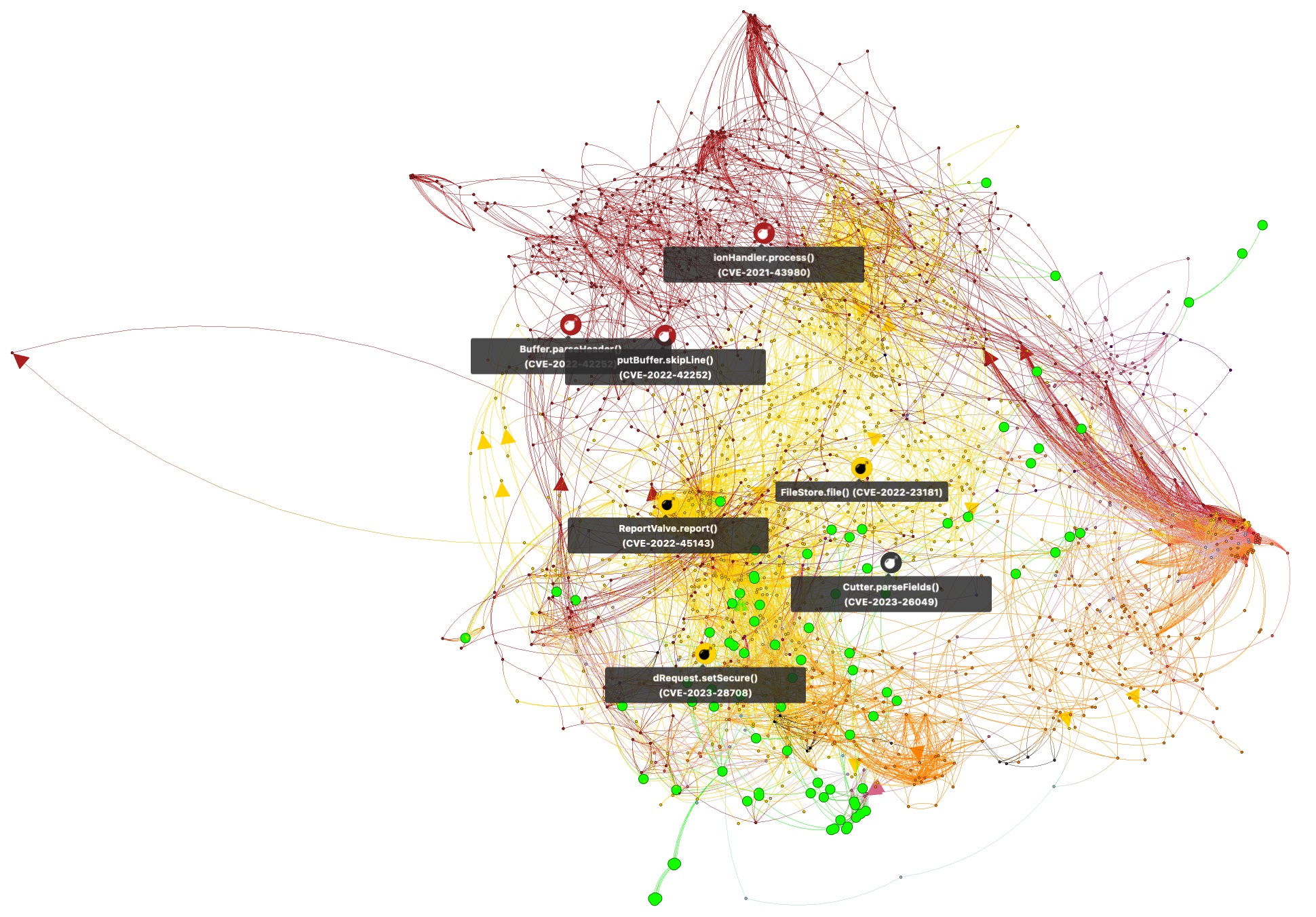
Figure B
Paths to CVE-2023-26049
The function CookieCutter.parseFields() is part of the OSS component jetty-http and affected by vulnerability CVE-2023-26049. To better investigate its invocation, we will filter all nodes and edges not leading to it (Figure C).
This shrinks the call graph to a size allowing logback-access developers to follow individual invocation paths starting from their component (in green). In this example, the path passes from functions of logback-access to functions of logback-core (light red) and jetty-server (orange) until it reaches CookieCutter.parseFields in jetty-http (gray). Hovering over nodes and edges would show additional metadata.
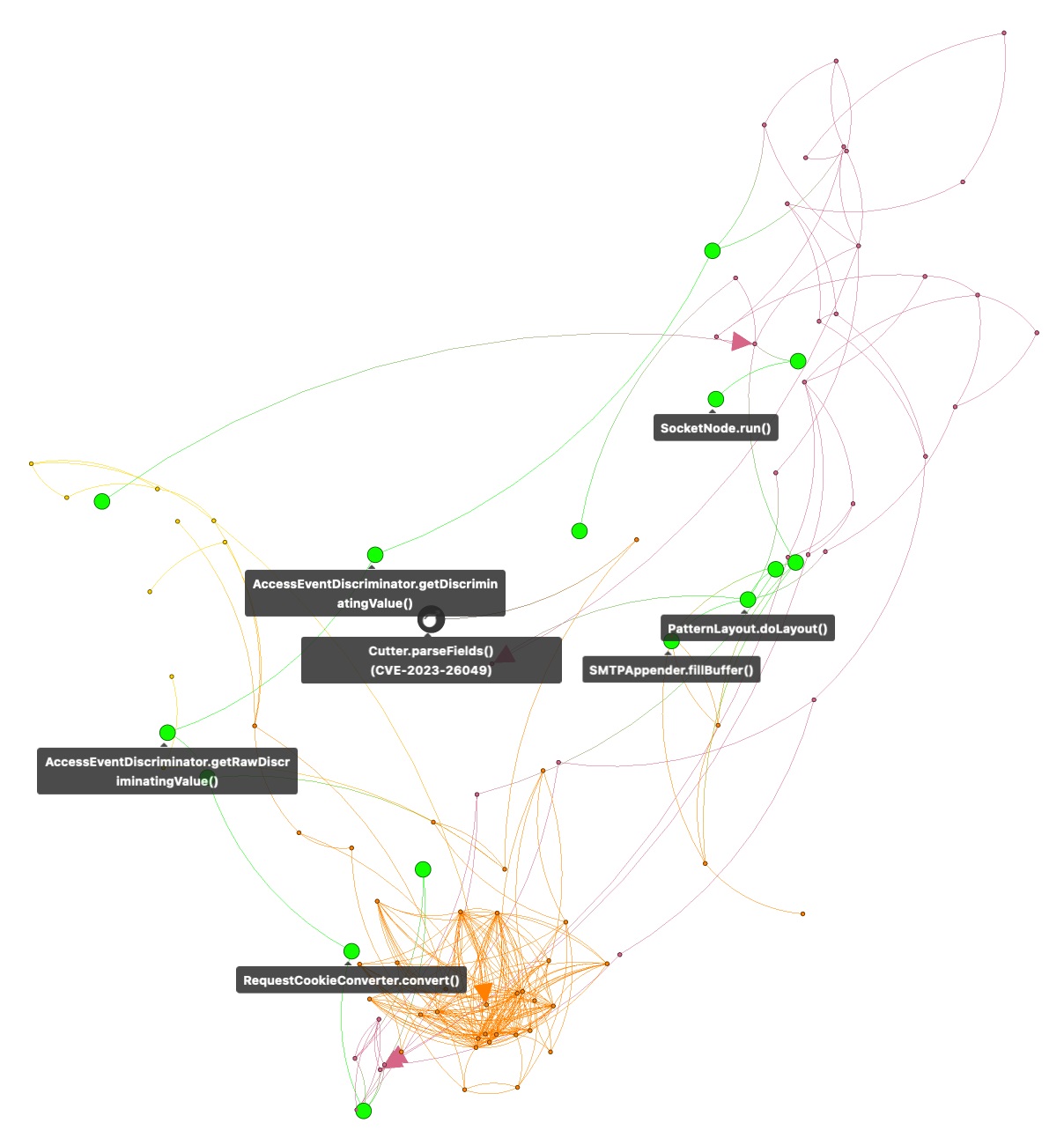
Figure C
Nearby CookieCutter.parseFields
Zooming further into the graph highlights the invocation path even more clearly: Figure D only contains paths with a distance of 4 or less to the vulnerable function. One of the critical paths starts at the logback-access function AccessEvent.getCookie and goes through Request.getCookies and Cookies.getCookies until it reaches CookieCutter.parseFields in component jetty-http.
We could stop here and conclude that call graphs reveal how a vulnerable function is invoked in the context of an application, no matter how deeply it is buried. This is important evidence that a given vulnerability really matters in the context of the application.
But looking at vulnerabilities at this level of detail also supports the actual mitigation, which typically comprises updating the dependency to a fixed version.
Since the call graph contains the vulnerable function signature, i.e. its name, parameters and return types, we can check whether this function also exists as-is in the fixed version. If not, an update could lead to breaking changes that manifest in compile or runtime errors. But suppose the update is not possible? The graph provides information to help develop a local, application-level fix.
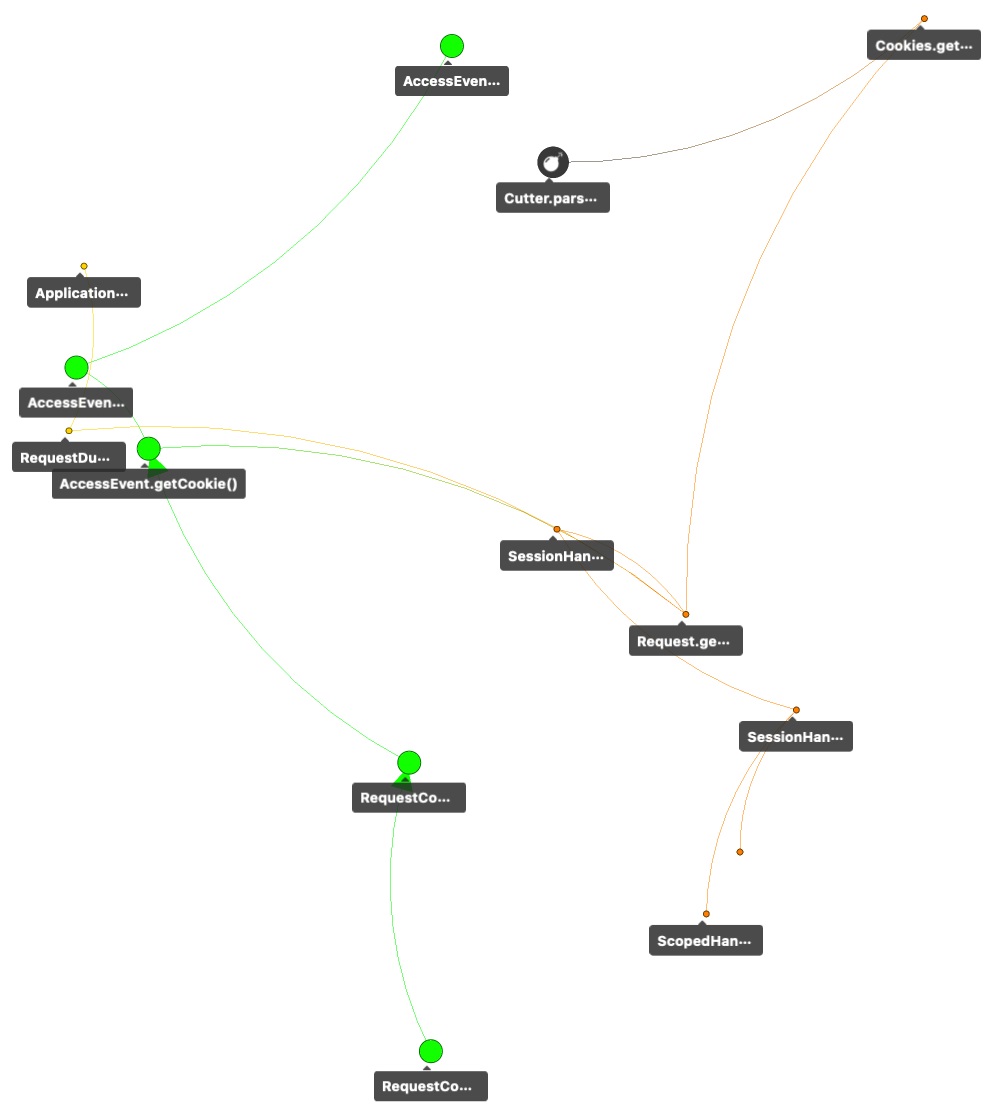
Figure D
Conclusion
Call graph analysis is useful for vulnerability assessment and mitigation. Voluminous call graphs with tens of thousands of nodes and edges allow digging deep into individual functions and function invocations for the purpose of understanding whether and how a given vulnerable function can be invoked and how such invocation can be fixed.
Such code-based analysis is crucial to overcoming the deficiencies of current approaches to OSS risk management and SCA, which are mostly based on package metadata and therefore prone to false-positives and cannot effectively support mitigation.