Dynatrace threads OpenPipeline into analytics & automation platform

Dynatrace used its annual user convention in Las Vegas this week to launch OpenPipeline, a new core technology designed to provide a single pipeline to manage petabyte-scale data ingestion into the Dynatrace platform.
The aim is to fuel secure and cost-effective analytics, AI and automation.
As the firm now bids to solidify its position as ‘the leading’ unified observability and security company, this technology enables full control of data at ingest. Dynatrace claims it will evaluate data streams ‘five to ten times faster than legacy technologies’ (in its own words) and help boost security, ease management burdens and maximise the value of data.
How does it speed up the engines for data ingestion by a factor of five? According to Bernd Greifeneder, CTO at Dynatrace, the company has worked to develop a handful of technologies serving this functionality requirement, Primarily he mentions a patent pending real-time stream processing technology that has been developed in-house… and other related enhancements will work in line and alongside this.
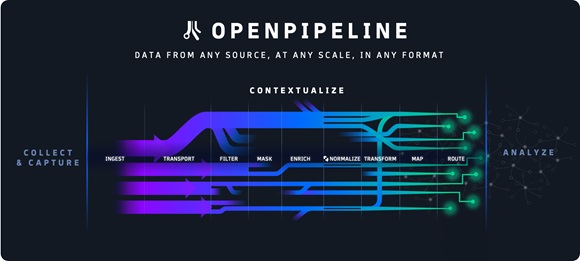
In simple terms, the Dynatrace OpenPipeline is built to give business, development, security and operations teams visibility into and control of the data they are ingesting into the Dynatrace platform while preserving the context of the data and the cloud ecosystems where they originate.
Because it evaluates data streams so much faster, it promises to enable users to manage the increasing volume and variety of data emanating from their hybrid and multi-cloud environments.
It is also positioned as a means of empowering more teams with access to the Dynatrace platform’s AI-powered answers and automations without requiring additional tools.
According to magical analyst house Gartner, “Modern workloads generate increasing volumes – as much as hundreds of terabytes and even petabytes each day – of telemetry originating from a variety of sources. This threatens to overwhelm the operators responsible for availability, performance and security. The cost and complexity associated with managing this data can be more than US$10 million per year in large enterprises.”
Modern cloud complexity
Creating a unified pipeline to manage data is challenging due to the complexity of modern cloud architectures. This complexity and the proliferation of monitoring and analytics tools within organisations can strain budgets.
At the same time, organisations need to comply with security and privacy standards, such as GDPR and HIPAA, in relation to their data pipelines, analytics and automations. Despite these challenges, stakeholders across organisations are seeking more data-driven insights and automation to make better decisions, improve productivity and reduce costs. Therefore, they require clear visibility and control over their data while managing costs and maximising the value of their existing data analytics and automation solutions.
“OpenPipeline is a powerful addition to the Dynatrace platform,” said CTO Greifeneder. “It enriches, converges, and contextualizes heterogeneous observability, security, and business data, providing unified analytics for these data and the services they represent. As with the Grail data lakehouse, we architected OpenPipeline for petabyte-scale analytics. It works with Dynatrace’s Davis hypermodal AI to extract meaningful insights from data, fueling robust analytics and trustworthy automation. Based on our internal testing, we believe OpenPipeline powered by Davis AI will allow our customers to evaluate data streams five to ten times faster than legacy technologies. We also believe that converging and contextualizing data within Dynatrace makes regulatory compliance and audits easier while empowering more teams within organizations to gain immediate visibility into the performance and security of their digital services.”
Greifeneder says that based on his team’s internal testing, they believe that converging and contextualising data within Dynatrace makes regulatory compliance and audits easier while empowering more teams within organisations to gain immediate visibility into the performance and security of their digital services.”
Core functions & connections
Dynatrace OpenPipeline works with other core Dynatrace platform technologies, including the Grail data lakehouse, Smartscape topology and Davis hyper-modal AI to deliver functions including the following:
Petabyte scale data analytics: Using patent-pending stream processing algorithms to achieve significantly increased data throughputs at petabyte scale.
Unified data ingest: Enables teams to ingest and route observability, security and business events data–including dedicated Quality of Service (QoS) for business events – from any source and in any format, such as Dynatrace OneAgent, Dynatrace APIs and OpenTelemetry, with customisable retention times for individual use cases.
Real-time data analytics on ingest: Allows teams to convert unstructured data into structured and usable formats at the point of ingest—for example, transforming raw data into time series or metrics data and creating business events from log lines.
Full data context: Enriches and retains the context of heterogeneous data points – including metrics, traces, logs, user behaviour, business events, vulnerabilities, threats, lifecycle events and many others – reflecting the diverse parts of the cloud ecosystem where they originated.
Controls for data privacy and security: Gives users control over which data they analyse, store, or exclude from analytics and includes fully customisable security and privacy controls, such as automatic and role-based PII masking, to help meet customers’ specific needs and regulatory requirements
Cost-effective data management: Helps teams avoid ingesting duplicate data and reduces storage needs by transforming data into usable formats—for example, from XML to JSON – and enabling teams to remove unnecessary fields without losing any insights, context or analytics flexibility.
Dynatrace OpenPipeline is available this year and will start with support for logs, metrics and business events – support for additional data types will follow.