Computational storage: NGD Systems / SNIA - Icebergs at the Edge

Software runs on data and data is often regarded as the new oil. So it makes sense to put data as close to where it is being processed as possible, in order to reduce latency for performance-hungry processing tasks.
Some architectures call for big chunks of memory-like storage located near the compute function, while, conversely, in some cases, it makes more sense to move the compute nearer to the bulk storage.
In this series of articles we explore the architectural decisions driving modern data processing… and, specifically, we look at computational storage
The Storage Network Industry Association (SNIA) defines computational storage as follows:
“Computational storage is defined as architectures that provide Computational Storage Functions (CSF) coupled to storage, offloading host processing or reducing data movement. These architectures enable improvements in application performance and/or infrastructure efficiency through the integration of compute resources (outside of the traditional compute & memory architecture) either directly with storage or between the host and the storage. The goal of these architectures is to enable parallel computation and/or to alleviate constraints on existing compute, memory, storage and I/O.”
The below commentary is written by Scott Shadley in his role as VP of marketing at rugged high-capcity computational storage specialist company NGD Systems and in his capacity as director on the SNIA board of directors.
Shadley writes as follows…
Data is being generated in scale and size and location like never before. With the terms Exabytes and Zettabytes replacing Terabytes in terms of scale, the new issue is how to manage these massive icebergs of raw data being generated nowhere near the actual place where the high-powered computing resources exist.
Icebergs at the Edge
This is the new issue with Edge Computing, so how do we in the industry manage that data? Many have thought to simply move the compute, CPUs, memory and storage, in existing footprints to the Edge. This becomes a challenge however, as physical space, power and scale become challenging.
So, new innovations are required.
When these innovations take hold and become a new standard, there is a point in that transition period where it shifts from education to implementation. Computational Storage is one of those innovations and there are many ways that happens.
I have the unique position today to speak on behalf of a few different hats as it relates to Computational Storage. This new innovative technology is becoming a very aggressive part of the traditional Von Neumann architecture. As you can see from the many potential solutions that are (or will be) coming to market, which I will highlight below.
But before we get there, we should take the effort to understand the change.
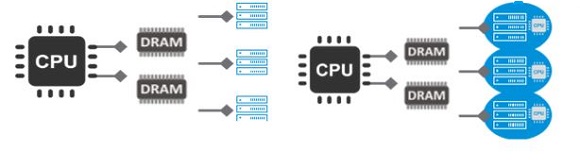
1-to-many vs. 1-to-1
As you can see on the left, Von Neumann has 1-to-many situation that creates strain on the system. The industry has introduced GPGPUs (General Purpose Graphics Processing Units) and other data movement and processing support, but it still acts as a 1 to many. The best way to solve that situation is create a 1-to-1 relationship as much as possible. That creates a truly scalable process and effort.

Shadley: We can conquer data icebergs with right gear.
Now, we all know that a CPU or GPGPU cannot be placed inside a storage device, but it certainly can contain processing power to manage local data in certain workloads.
So with my NGD Systems hat on, I can say we have helped solve this issue by adding Arm-based CPUs into our traditional NVMe SSD ASIC that was designed and developed specifically for this purpose.
Other companies have done FPGA-based or FPGA-enabled solutions, but these still have a technology and cost increase. So the implementations are varied today and at NGD Systems, the ASIC-based NVMe SSD, now called a Computational Storage Drive (CSD), is a seamless way to enable the innovation and change.
Computational Storage Technical Work Group
As part of the SNIA organisation, the companies involved all agreed that to ensure the innovation success, a group of like-minded people and companies need to come together to make the technology easy to deploy, regardless of the actual product. That is why NGD Systems joined and led the Computational Storage Technical Work Group (CS TWG) and further decided to help evolve the organisation as a member of the Board of Directors.
Overall, Computational Storage Device (CSx) solutions are available today from a number of companies. NGD Systems, Scaleflux, Samsung/Xilinx/Eideticom (joint product) and others. But the point is they are available, they are being deployed and they offer a new way to manage localised data in a more effective and efficient manner.
This solves problems for storage architects, system admins and even aoftware architects. Some products are ‘plug-n-play’ others require kernel changes. But at the end of the day, all these products solve one major problem. Data movement of mass scall data.
Computational Storage, an inevitability
Moving from every bit going from Edge to Cloud to compute and allowing for Compute at the Edge reduces burdens on all aspects of the systems. Less hardware is needed at the Edge. Fewer network pipes get clogged with ‘raw data’ and better and more efficient use of the cloud computing power.
Computational Storage is going to happen. Many companies have aligned on that, Western Digital, Samsung, Dell, Lenovo, HPE, VMware and many more.
Not all products solve all problems, not all problems at the Edge or datacenter can be solved. But there is enough need, enough want (whether known or not) to drive the adoption in the next year or two. Stay tuned as we see this market and model evolve and become something of significant value in the very near future.