AWS DevOps Guru: the mahatma's machine learning mantra

If Jamie Oliver (other celebrity chefs are available) launched a service named Tastiest Ever Chef, you might not think it that unusual… but it’s a brand naming convention that we don’t often find used in IT circles.
That established norm hasn’t put Amazon Web Services, Inc. (AWS) off.
AWS used its re:Invent virtual event this week to announce Amazon DevOps Guru.
He/she/they are not an actual person, there is no all-powerful mystical mahatma who delivers teachings as the ‘learned one’ for all DevOps needs.
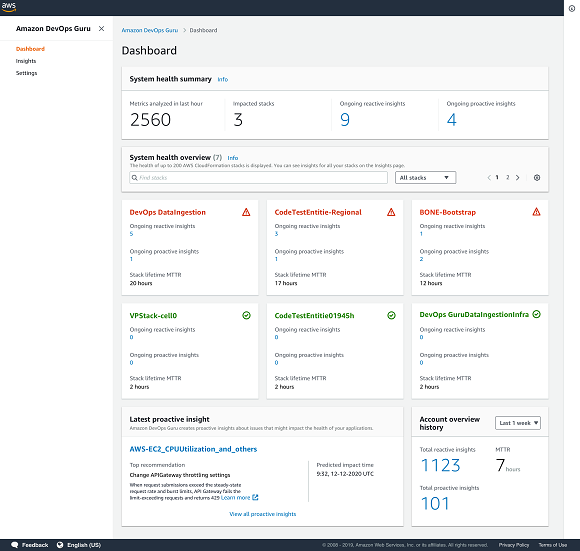
Instead, this is a managed operations service that uses machine learning for developers to improve application availability by automatically detecting operational issues and recommending specific actions for remediation.
What kind of application data does it ingest?
Data like application metrics, logs, events and traces for identifying behaviours that deviate from normal operating patterns.
What’s an abnormal anomalous cloud?
But what constitutes abnormal for a cloud DevOps person?
Well, that would be things like under-provisioned compute capacity, database I/O over-utilisation, memory leaks and anomalous application behavior such as increased latency, error rates, resource constraints etc. Application downtime events are also caused by faulty code or config changes, unbalanced container clusters, or resource exhaustion (e.g. CPU, memory, disk, etc.), which are all bad news.
The guru itself, sorry AWS DevOps Guru, then indulges in a herbal tobacco hookah, reads from the book of scriptures, lights some incense and grabs a messaging channel (in this case, it’s Amazon (SNS) Simple Notification Service) to alerts developers with issue details (e.g. resources involved, issue timeline, related events, etc.
The guru welcomes all creatures and so have formed partner integrations with the likes of Atlassian Opsgenie and PagerDuty to help DevOps teams understand the potential impact and likely causes of the issue with specific recommendations for remediation.
AWS argues that as microservice architectures grow, applications have become increasingly distributed, so developers need more automated practices to maintain application availability and reduce the time and effort spent detecting, debugging and resolving operational issues.
Using existing tools, AWS says that developers often have difficulty triangulating the root cause of an operational issue from graphs and alarms — and even when they are able to find the root cause, they are often left without a means to fix it.
“Customers have asked us to continue adding services around areas where we can apply our own expertise on how to improve application availability and learn from the years of operational experience that we have acquired running Amazon.com,” said Swami Sivasubramanian, vice president, Amazon Machine Learning at AWS. “With Amazon DevOps Guru, we have taken our experience and built specialised machine learning models that help customers detect, troubleshoot, and prevent operational issues while providing intelligent recommendations when issues do arise.”
With the AWS Management Console, users can enable Amazon DevOps Guru to begin analysing account and application activity within minutes to provide operational insights.
Amazon DevOps Guru gives customers a single-console experience to visualize their operational data by summarizing relevant data across multiple sources (e.g. AWS CloudTrail, Amazon CloudWatch, AWS Config, AWS CloudFormation, AWS X-Ray) and reduces the need to switch between multiple tools.
The core message here is that Amazon DevOps Guru provides customers the automated benefits of machine learning for their operational data so that developers can more easily improve application availability and reliability.