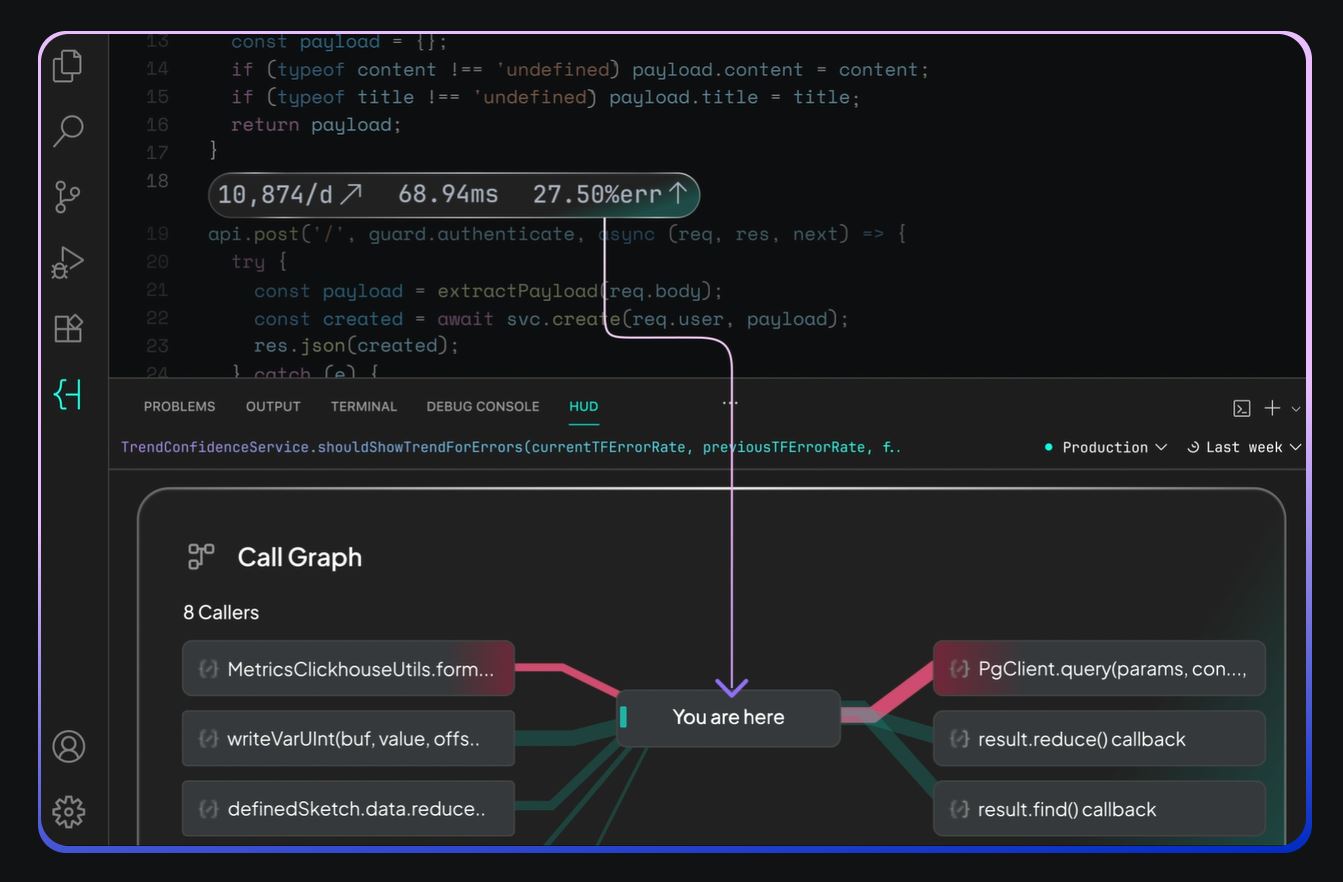
Hud details post-deployment live production analytics

Software application development, architectural planning procedures and deployment-time analysis (as well as post-deployment live production analytics) all need observability and insight.
In short, software teams almost need a video game-style on-screen alerting system – also known as a Heads Up Display, or HUD – in order to get insight into live service and function-level data from live production systems.
Logically named Hud for that exact reason, Hud (the company) is on a mission to bridge the gap between code and live production reality with its Runtime Code Sensor, which already serves millions of services across massive production environments.
Service & function-level data
Hud automatically captures live service and function-level data from production- providing the missing context for AI to detect and fix issues and to build production-safe code.
The company suggests that enterprises today face mounting pressure to adopt AI development tools; they struggle to bridge the gap between AI’s promises and code that performs reliably in production at scale.
“Every software team building at scale faces the same fundamental challenge: building high-quality products that work well in the real world,” said Roee Adler, CEO and founder of Hud. “In the new era of AI-accelerated development, not knowing how code behaves in production becomes an even bigger part of that challenge. Our Runtime Code Sensor transforms the feedback loop between development and production, ensuring immediate validation and optimisation of software code – whether human-written or AI-generated.”
Hud’s Runtime Code Sensor delivers production awareness and the company claims that this validates its claim to have “moved beyond reactive monitoring approaches” with a lightweight software sensor that continuously captures live function-level behaviour.
That function-level behaviour includes performance metrics, errors, execution flows and dependencies, without requiring logs, traces, or manual instrumentation.
Engineers & agents, together
The Computer Weekly Developer Network blog caught up with Hud CEO Adler in person this week to ask him more about where observability tools, in his view, go next.
“Traditional observability tools were built for a different era – they require you to decide what to log, where to trace and figure out the balance between how much you’re willing to pay and the sampling rate you can live with. When thinking about what AI coding agents need – ubiquitous information about how code behaves in production, whichever piece of code they’re currently reasoning over, that model breaks down because you simply can’t put logs everywhere all the time, due to three reasons,” said Adler.
His three reasons why the old ways are broken are first, it slows production down; second, it’s prohibitively expensive at scale and third – models aren’t built to sift through terabytes of logs to find what they need. If data isn’t available to the model right then and there – it won’t be used. In the age of AI coding agents, these limitations become critical blockers.

Hud CEO Adler: Runtime Code Sensor runs alongside code, automatically understanding how every function behaves in production.
“Hud was built from first principles as a Runtime Code Sensor that runs alongside your code, automatically understanding how every function behaves in production – no decisions required, no configuration needed, installed in one minute. Most of the time it stays fairly quiet, sending only a lightweight stream of aggregated statistical data. But when something goes wrong – an error, latency spike, or unexpected behaviour – it captures deep forensic context straight from production and gives AI everything it needs to understand and fix the issue,” said Adler.
Logs & traces: complementary, not central
But he’s not a naysayer i.e. he believes logs and traces aren’t going anywhere. They are valuable tools for research and deep understanding when a developer suspects certain areas or flows. But with the advent of code-generating AI, the Hud team believe they will become complementary rather than central.
CWDN: Hud focuses on performance metrics, errors, execution flows and dependencies. Can its analysis help developers to think about how their dependencies and other architectural constructs may have been misaligned (or at least built inefficiently) at initial build time?
Adler: There are two aspects to this question: when you initially write the code, vs when you make changes to an existing system. We focus on true runtime behaviour and leave static code analysis to other tools that are great at it. We believe models are great at understanding how code can be better in theory – before it hits the real world and has to deal with dependencies, infrastructure, and systems that fail in creative and surprising ways.
So when code is initially written in a greenfield environment, Hud becomes helpful at running locally, then in testing and CI and mostly in production. The essence is that until the code actually runs against its real world dependencies, you can’t really tell how it’s going to behave – and you’re at risk of optimising yourself to oblivion without actual signals to what works and what doesn’t.
On the other hand, when making changes to existing codebases, Hud becomes a powerful tool at the “hands” of the model, to be able to reason not only over the code, but also on the reality context of the code.
Not observability, as we know it
He says that his team views its platform as a new runtime layer between production and agentic code generation. This isn’t observability as we know it – it’s a whole new paradigm.
“Traditional APMs, loggers, error trackers, production debuggers and profilers each see a narrow slice of reality and typically tell you that something is wrong, then leave it to you to stitch together why it happened. They all send lots of data from the edge to the back-end, hoping someone will make sense of it. They were never designed for agentic code generation. We run with the code so that we never miss an invocation… and when an error, latency spike or outlier occurs, it gathers the deep forensic context needed to understand the root cause – inputs, code flow, 3rd-party parameters, pod metrics etc. and makes that directly consumable by both engineers and AI coding agents. So instead of sifting through data in disparate systems and trying to connect it to tell a story – we deliver that story straight from production,” detailed Adler, as part of a technical briefing.
Many teams are already experimenting with AI coding agents – Capgemini Research found that 60% of organisations are running generative AI pilots. But many of them struggle to scale them to production. They hit what we Adler calls the ‘AI trust gap’ when code reaches complex production environments – they’re not yet comfortable letting agents touch critical paths without knowing how the code behaves in production.
“The real revolution is happening where large engineering teams are trying to adopt agentic code generation… and where AI-native newcomers are hitting production pains for the first time. That’s the biggest problem AI has in code generation – and the coolest place to innovate,” concluded Adler.