
michelangelus - Fotolia
Inmon or Kimball: Which approach is suitable for your data warehouse?
Inmon versus Kimball is one of the biggest data modelling debates among data warehouse architects. Here is some help to select your own approach
When it comes to designing a data warehouse for your business, the two most commonly discussed methods are the approaches introduced by Bill Inmon and Ralph Kimball. Debates on which one is better and more effective have lasted for years. But a clear-cut answer has never been arrived upon, as both philosophies have their own advantages and differentiating factors, and enterprises continue to use either of these.
In a nutshell, here are the two approaches: in Bill Inmon’s enterprise data warehouse approach (the top-down design), a normalised data model is designed first, then the dimensional data marts, which contain data required for specific business processes or specific departments, are created from the data warehouse. In Ralph Kimball’s dimensional design approach (the bottom-up design), the data marts facilitating reports and analysis are created first; these are then combined together to create a broad data warehouse.
To begin with, let us have a quick look at both the approaches.
Inmon’s top-down approach
Inmon defines a data warehouse as a centralised repository for the entire enterprise. A data warehouse stores the “atomic” data at the lowest level of detail. Dimensional data marts are created only after the complete data warehouse has been created. Thus, the data warehouse is at the centre of the corporate information factory (CIF), which provides a logical framework for delivering business intelligence.
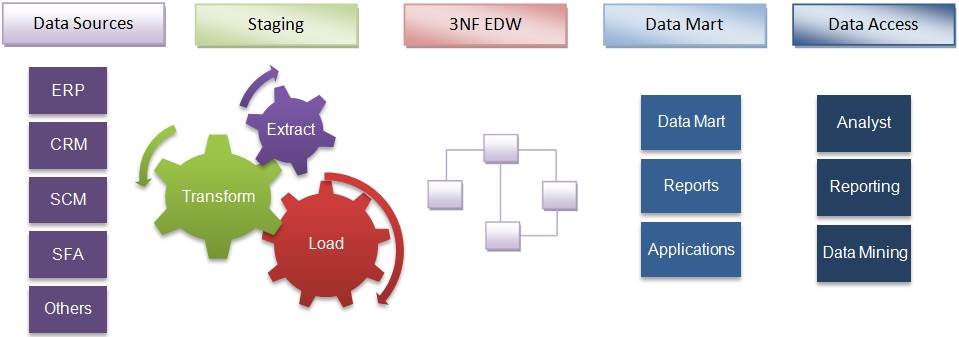
Inmon defines the data warehouse in the following terms:
- Subject-oriented: The data in the data warehouse is organised so that all the data elements relating to the same real-world event or object are linked together.
- Time-variant: The changes to the data in the database are tracked and recorded so that reports can be produced showing changes over time.
- Non-volatile: Data in the data warehouse is never overwritten or deleted. Once committed, the data is static, read-only and retained for future reporting.
- Integrated: The database contains data from most or all of an organisation’s operational applications, and that this data is made consistent.
Kimball’s bottom-up approach
Keeping in mind the most important business aspects or departments, data marts are created first. These provide a thin view into the organisational data and, as and when required, these can be combined into a larger data warehouse. Kimball defines data warehouse as “a copy of transaction data specifically structured for query and analysis”.
Kimball’s data warehousing architecture is also known as data warehouse bus (BUS). Dimensional modelling focuses on ease of end-user accessibility and provides a high level of performance to the data warehouse.
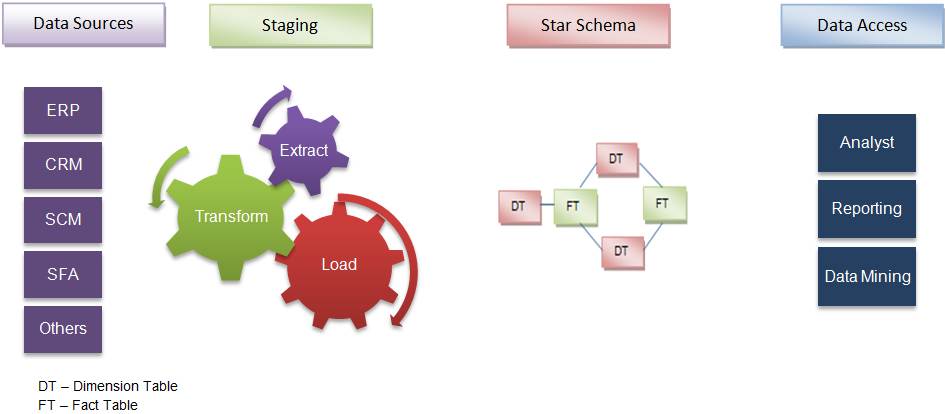
Inmon and Kimball compared
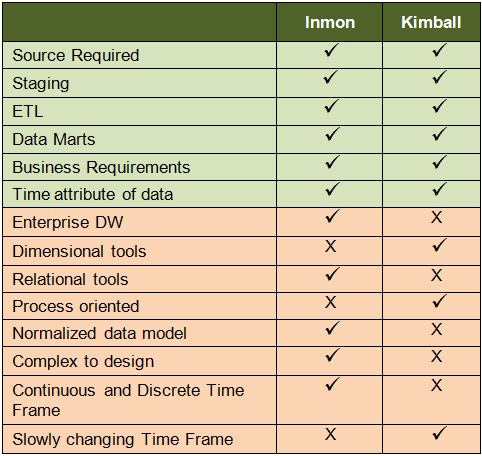
Pros and cons of both approaches
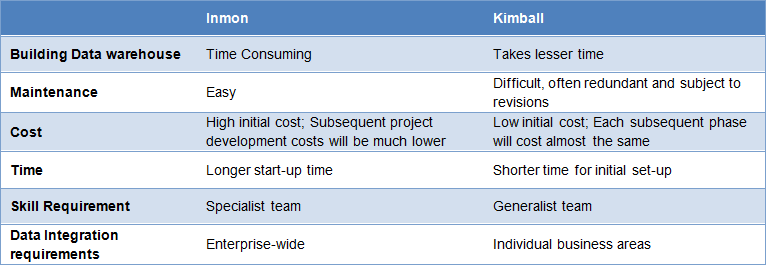
How to decide?
As we have already seen, the approach to designing a data warehouse depends on the business objectives of an organisation, nature of business, time and cost involved, and the level of dependencies between various functions. Inmon’s approach is suitable for stable businesses that can afford the time taken for design and the cost involved. Also, with every changing business condition, they do not change the design; instead, they accommodate these into the existing model. However, if local optimisation is good enough and the focus is on a quick win, it is advisable to go for Kimball’s approach. Keeping this in mind, let the Inmon versus Kimball fight happen over a few sectors/functions.
- Insurance: It is vital to get the overall picture with respect to individual clients, groups, history of claims, mortality rate tendencies, demography, profitability of each plan and agents, and so on. All aspects are interrelated and therefore suited for the Inmon approach.
- Marketing: This is a specialised division that does not call for enterprise warehouse. Only data marts are required, so Kimball’s approach is suitable.
- CRM in banks: The focus is on parameters such as products sold, up-sell and cross-sell at a customer level. It is not necessary to get an overall picture of the business. For example, there is no need to link a customer’s details to the treasury department dealing with forex transactions and regulations. Because the scope is limited, you can go for Kimball’s method. However, if the entire processes and divisions in the bank are to be linked, the obvious choice isInmon’s design versus Kimball’s.
- Manufacturing: Multiple functions are involved here, irrespective of the budget involved. Therefore, where there is a systemic dependency, as in this case, an enterprise model is required, so Inmon’s method is ideal.
While designing a data warehouse, first you have to look at your business objectives – short-term and long-term. See where the functional links are and what stands alone. Analyse data sources for quantity and quality. Finally, evaluate your resource level, timeframe and wallet. This helps you to arrive at which method to adopt – Inmon’s or Kimball’s or a combination of both.
 About the author: Sansu George is a business analyst at Abiba Systems, a specialist telecommunication business intelligence and analytics firm based in Bangalore, India. Currently she works on solutions pertaining to enterprise performance analysis, customer segmentation, campaign management and churn prediction, specifically for telecom operators.
About the author: Sansu George is a business analyst at Abiba Systems, a specialist telecommunication business intelligence and analytics firm based in Bangalore, India. Currently she works on solutions pertaining to enterprise performance analysis, customer segmentation, campaign management and churn prediction, specifically for telecom operators.






