Whiteboard it – the power of graph databases
Graph databases map relationships between entities in a network. They won’t replace conventional relational databases, but for harnessing the value of interconnectedness they mark a breakthrough
Douglas Adams once wrote of a Holistic Detective Agency. The central character in this story, Dirk Gently, was able to solve cases with his understanding of the fundamental interconnectedness of everything.g
There has certainly been a huge growth of interest in leveraging value from this concept of interconnectedness.
For instance, Mark Zuckerberg built Facebook into one of the most prominent technology companies in the world by understanding that the relationships connecting people are just as important as the people themselves.
Relational databases and relationship problems
Relational databases are great for storing and retrieving data that fits nicely into a tabular format.
Although they can express relationships by joining the tables, this is a simple mechanism – for example, specific orders belonging to specific customers and specific orders comprising specific products.
Things get more complicated when we have a multitude of relationships, each with complex properties associated with them – more complex than merely “a one-to-many relationship exists between A and B”.
Consider storing and analysing data on children’s diets – we’ll want to record not only the fact that little Johnny likes turkey-twizzlers, but also quantify that relationship with the strength of his preference.
We’ll need to track food allergies too, along with the severity of the allergy, and the date the allergy was diagnosed. Certain foods may also be excluded for religious reasons, parental beliefs – and so it goes on.
This kind of data, with many rich relationships between child and food, is not easily stored in a relational database.
It can be done – given enough junction tables and additional columns to record the properties of each relationship – but the results are not pretty.
And the awkwardness doesn’t end with the design – writing queries becomes increasingly difficult as more and more joins need to be prescribed.
Additionally, the more joins the engine is required to perform, the worse performance becomes. Sadly, joins and junction tables are just not sophisticated enough to fully express the multitude and richness of relationships found in some data.
More on graph databases
- What is a graph database?
- Graph database vs. relational database
- Facebook search app boosts graph database architecture to the fore
Enter the graph database
Graph databases are built on the branch of mathematics known as graph theory, the foundations for which were laid in the 18th century by the mathematician Leonhard Euler. When Euler conclusively proved the infamous Seven Bridges of Königsberg problem was unsolvable, graph theory was born.
Graph data is comprised of vertices and edges – to us mortals, that translates to “things” and “relationships between things”.
Unsurprisingly the “things” can be assigned properties – year of manufacture, shoe size, cubic capacity.
Crucially though, the relationships can also be assigned properties in exactly the same way, making them every bit as queryable as the things they connect.
In a graph database, relationships are not relegated to clumsy junction tables. They are first-class citizens of the database.
Complex data in a whiteboard-friendly format
So, one very good reason for using a graph database is its ease of storing and retrieving varied data connected by rich relationships.
Another is that if asked to draw a diagram of relationships on a whiteboard, most people would produce something like this:
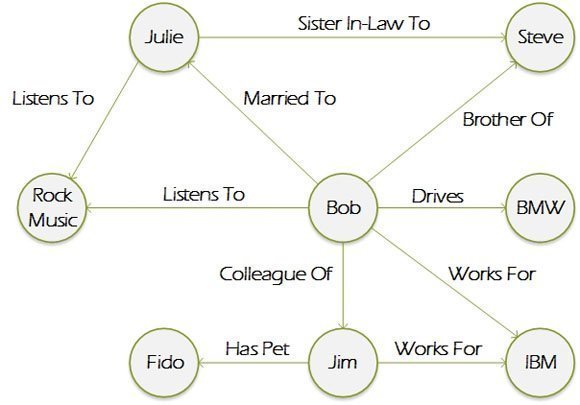
A graph database can easily be constructed from this sketch. No re-engineering is required. No need to coerce it into an alternative non-intuitive conceptual representation consisting of tabular structures, keys and junction tables.
The graph database can then be populated with properties and values.
If Jim was once struck by lightning, we can add a “Date of last lightning strike” property and value to Jim.
We don’t need to reserve space and then populate it with a "null" value for when Bob or Julie or Steve was last stuck by lightning – the flexible schema easily accommodates these diverse properties.
Everyone – from user, through business-analyst, to DBA – can sit around the whiteboard in agreement as to what the graph looks like.
User, logical and physical models unified into one common language – that’s a very powerful concept.
Not planning on starting up the next Facebook?
Graph database examples often cite social networks, which is hardly surprising since we humans have many complex and varied relationships with one another.
However, you don’t need to be planning the next Facebook before you can gain benefit from graph databases. Other use scenarios include:
- Recommendations – “Customers who bought what you did also bought this product too”;
- Distribution\travel – Finding the best (fastest or cheapest) route between two places;
- Network\telephony – Isolating the problem domain when customers report issues.
The mantra of the graph database evangelist is: “If you can whiteboard it, you can graph it!”
Test drive a graph database today
Research firm Gartner believes more organisations will experiment with graph databases in the future.
You can start your own graph adventure by downloading the excellent open source graph database Neo4j. There is a wealth of quick-start guides, videos and documentation available to help you get going.
Various query languages exist for graph databases, but anyone with a SQL background will find Neo4j’s Cypher relatively straightforward.
It is a declarative language like SQL, with some familiar syntax, such as “WHERE” and “ORDER BY”.
Neo4j even supports ACID transactions in the same way a relational database does.
Relational databases and graph databases sit side by side
Graph databases will never replace conventional relational databases, but for harnessing the value of the fundamental interconnectedness of everything, a graph database is well worth considering.
 Andy Hogg is a freelance consultant specialising in Microsoft SQL Server and associated technologies.
Andy Hogg is a freelance consultant specialising in Microsoft SQL Server and associated technologies.







