
nobeastsofierce - Fotolia
Unaligned I/O: A storage performance killer
As the stack piles higher – with virtual servers, their virtual disks and guest operating systems – the scope for unaligned or misaligned I/O to affect performance increases

Until the widespread adoption of NAND flash, persistent storage was generally based on mechanical devices.
We had punched tape and cards (both of which have pretty much disappeared), then tape and spinning disk media, including hard drives and optical. All of these devices have physical characteristics that affect the performance of how data reads and writes.
But, as server virtualisation abstracts the virtual machine’s (VM) logical disks from the underlying physical storage, an issue that starts to arise is that of misaligned or unaligned input/output (I/O).
Unaligned I/O results in I/O performance degradation and is a result of misalignment of the logical blocks in the multiple layers of abstraction between the virtual machine’s storage and the external presentation of the storage from a shared storage array.
To see why this problem has arisen we need to look at how storage is mapped to virtual machine guests from the external array.
Typically, storage area network (SAN) or network file system (NFS)-based storage will internally read and write data in fixed blocks or chunks, from sizes of 4K upwards.
On top of this we create, for example, VMFS (VMware vSphere) and VHD (Microsoft Hyper-V) file layouts.
Both of these file systems operate slightly differently – Hyper-V uses the New Technology File System (NTFS) – but for the benefits of our example the relevant characteristics are the same. With VMFS-5 the allocation size is 1MB, with the size of I/O based on the guest itself.
Above that we have the VM guest and the file system within the operating system (OS), for example Microsoft Windows and NTFS which have a fixed, predefined cluster size. This arrangement is represented in Figure 1, which shows each layer aligned on LBA (logical block address) boundaries (starting from LBA=0). An I/O read or write to any block of VM guest data results in only one I/O at the storage layer.
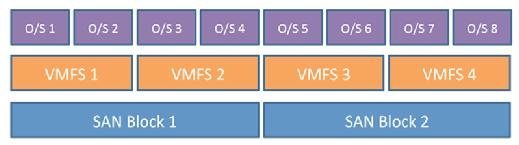
Now look at the scenario where we have misalignment of I/O at the VM guest level in Figure 2. Writing to block O/S 2 results in two I/Os to the VMFS (but in this case only one to the underlying storage), while I/O to O/S 4 results in two to the hypervisor and two to the underlying storage.
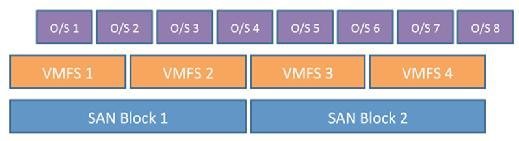
Similar problems would also be seen if the VMFS was also misaligned.
At first glance, the alignment problem may not seem like a lot of overhead for the storage. After all, if a file is written in large blocks then one additional I/O among tens or hundreds may not be a problem.
But, with server virtualisation, the distribution of data across the VMFS results in highly random I/O, so the extra overhead of I/Os to manage the misaligned data could be quite significant. Part of the reason for this is in the way the storage is written to the external storage array.
That’s because a partial update to a block of data on the SAN could generate multiple additional reads to get data from physical disk, make the partial updates and write the data back to disk again, compared with simply updating the entire block because the whole block is changing.
Why does unaligned I/O matter?
So what are the effects of misaligned I/O?
The most obvious is on storage performance. Although the impact will be variable – and dependent on the storage platform, the number of guests and the amount of misalignment – the additional I/O load could be an additional 10-20%. In latency-dependent environments – such as with hard disk drive (HDD)-based arrays – this impact could be noticeable to VM guests, especially where there are lots of small-sized I/O requests.
The second possible area of impact is that of space optimisation on the storage array, both from a thin provisioning and data deduplication perspective.
Where the VM OS and storage are misaligned, data allocations at the guest layer could cause additional storage to be physically reserved for the guest, as the logical allocation runs into the next logical allocation block in the unit size allocated to thin provisioning. This overhead is likely to be small, however.
The other area that could have an issue is in data deduplication.
If multiple operating systems are out of alignment, and if the deduplication process is based on fixed size blocks, the potential savings from deduplication of similar data as seen by the storage array may not be fully realised. Simply shifting the LBA start point by one byte will defeat deduplication algorithms that expect data to have boundaries consistent with the underlying storage platform.
Resolving unaligned I/O
Thankfully, today’s modern operating systems have largely fixed the alignment issue at the guest level.
Windows 2008 onwards, for example, aligns to a 1MB boundary for the boot drive, rather than the previous offset of 63 sectors (of 512 bytes) or 31.5kB, which was done to match physical disk geometry.
Most, if not all of the Linux-based operating systems, also align correctly. Remember that these changes apply to new installations, but upgrades in place may not necessarily correct the problem.
At the hypervisor level, VMware’s ESXi 5.0 onwards allocates to a 1MB boundary for both VMFS3 and VMFS5 partitions. But, any partitions created with earlier releases of VMFS/ESXi will still be aligned to 64KB, even if they are subsequently upgraded to VMFS5. These data stores (and their partitions) will need to be deleted and recreated to fix the alignment problem.
To see whether the problem exists, there are tools that can look at the host, hypervisor and the storage.
NetApp’s Data Ontap, for example, detects and reports on the amount of misaligned I/O detected on each logical unit number (LUN). Windows alignment can be checked with multiple tools, including Diskpart, Windows Management Instrumentation Command-Line (WMIC) and fsutil. Linux systems can be checked with the fdisk utility.
For the hypervisor, VMware’s vSphere provides the partedutil command that can be run from the ESXi command line. For Microsoft Hyper-V, alignment will be dependent on the underlying NTFS partition configuration that can be checked with standard Windows commands.
One final thought. The problems described in this article are manifested more with latency sensitive storage systems. As we move to flash systems and server-based caching, the overhead of misalignment may be much less noticeable and so not worth going back to correct.
Read more about storage performance
- We run the rule over storage performance metrics – latency, throughput and IOPS – that are key to optimising virtual machines.
- Storage array makers’ spec sheets can be difficult to translate and sometimes prove misleading – the trick is to dig out the devil in the detail.







