Alletra MP hardware changes see HPE orient arrays towards AI
HPE doubles controller nodes, boosts capacity with denser drives, cuts caches and builds in 100Gbps links to bring denser, faster storage aimed at all parts of the AI/ML pipeline
In a push towards artificial intelligence (AI) workloads, HPE has upgraded its Alletra MP storage arrays to connect double the number of servers and provide 4x the capacity in the same rackspace.
A year after initial launch, Alletra MP now has four control nodes per chassis instead of two, each with an AMD Epyc CPU with eight, 16 or 32 cores. Its 2U data nodes have now also become 1U, with 10 SSDs of 61.44TB for a maximum capacity of 1.2PB in 2U. Previously, Alletra MP data nodes contained 20 SSDs of 7.68TB or 15.36TB (making up to 300TB per node).
That increase in node numbers means Alletra MP can now connect to 2x the number of servers and give them 4x the capacity for the same datacentre rackspace, and a similar energy usage, according to HPE.
“We call this new generation Alletra MP for AI,” said Olivier Tant, HPE Alletra MP NAS expert.
“That’s because we think it’s perfectly suited to replace storage solutions based on GPFS or BtrFS, which are complex to deploy, but which are often used for AI workloads. We also believe our arrays are more efficient than those from DDN in HPC or Isilon in media workloads.”
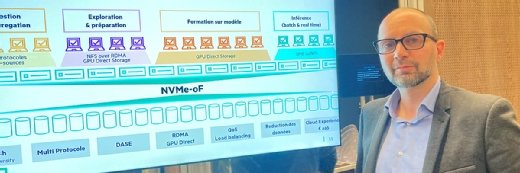
The SAN block access version works like the NAS file access version with 100Gbps ROCE switches that allow any controller node to access any data node.
“The huge advantage of our solution over the competition is that all nodes in the cluster talk to each other,” said Tant. “In other words, our competitors are limited to, for example, 16 storage nodes of which three will be used by redundant data for erasure coding. That’s 15% to 20% of capacity. We can deploy a cluster of 140 nodes of which three are used for redundancy via erasure coding. We only lose about 2% of capacity, and that’s a real economic advantage.”
The secret recipe: 100Gbps ROCE switches between nodes
“Our solution is also better performing, which is because, paradoxically, because we don’t use cache at controller level,” said Michel Parent, HPE Alletra MP NAS expert. “With NVMe/ROCE connectivity of 100Gbps across all elements in the array, cache becomes counter-productive.
“Cache doesn’t accelerate anything, and in fact slows down the array with incessant copy and verification operations,” he added. According to Parent, no other storage array on the market uses NVMe/ROCE at speeds as high as 100Gbps per port.
Hosts use Ethernet or Infiniband (compatible with Nvidia GPUDirect) to access the controller node closest to them. During writes, that node carries out erasure coding and shards the required data to other SSD nodes. From the point of view of network hosts, all controller nodes expose the same file volumes and block LUNs.
In NAS mode – in which Alletra MP uses Vast Data’s file access system – there is cache made up of fast flash SCM from Kioxia. This buffer serves as a workspace to deduplicate and compress file data.
“Our system of data reduction is one of the best performing, according to different benchmarks,” said Tant. “All duplicates in the data are eliminated. Then an algorithm finds blocks most resemble each other and compresses them, and it’s very efficient.”
Read more on storage and AI
- GTC 2024: Storage suppliers queue up to ride the Nvidia AI wave. Storage supplier announcements at Nvdia conference centre on infrastructure integration, tackling the GPU I/O bottleneck and AI hallucinations by running Nvidia NeMo and NIM microservices.
- Podcast: What is the impact of AI on storage and compliance? Start now looking at artificial intelligence compliance. That’s the advice of Mathieu Gorge of Vigitrust, who says AI governance is still immature but firms should recognise the limits and still act.
The only parts of files that are shared between several nodes are those that result from erasure coding. By preference, a file will be re-read from the SSD that contains the whole thing.
More precisely, during a read, the controller passes the request to the first SSD node chosen by the most available switch. Every data node holds the index of all the cluster’s contents. If the node doesn’t hold the data to be read, it sends the controller’s requirements to the node that does.
In the SAN version, the mechanism is similar except that it works by block rather than at file level.
With such an architecture, which is based more on the speed of the switches than the controllers, it becomes simple to switch from one node to another if one doesn’t respond quickly enough on its Ethernet port.
One array for several types of storage
NVMe SSDs are quickest at rebuilding a file from blocks of data, because every 100Gbps link in Alletra MP is as fast as or faster than the network connection between the array and the application server. In competitors’ arrays that don’t use switches between the controller and dedicated SSD nodes, it’s usual to try to optimise for particular use cases.
“I’m convinced of the economic advantage of Alletra MP over its competitors,” said Tant. “In an AI project, an enterprise normally has to put in place a data pipeline. That means a very performant storage array in writes collect the output from these workloads. Then you copy its contents to a storage array that’s got read performance to train the model for machine learning. Then you store the resulting model in a hybrid array to use it.”
“With Alletra MP you only have one array that’s as rapid for writes as it is for ML and for utilisation of the model,” he said.
Read more on AI and storage
-
![]()
New HPE node enriches data in real time for AI pipelines
By: Kathleen Casey
-
![]()
HPE storage battles hard and smart in challenging market
By: Antony Adshead
-
![]()
Storage metadata services for AI apps trending at Nvidia GTC
By: Tim McCarthy
-
![]()
Object storage, VM offerings emerge for HPE GreenLake
By: Tim McCarthy



