
sdecoret - stock.adobe.com
Globaler Datenzugriff und -verwaltung: Das bietet Hammerspace
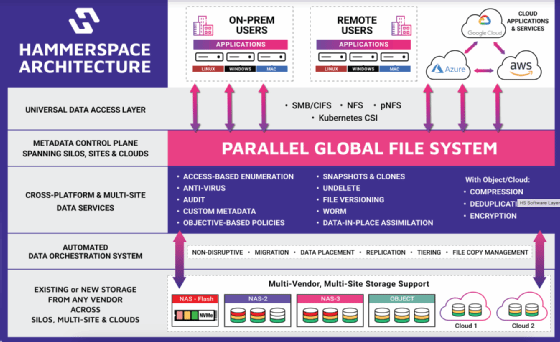
Hammerspace hilft dabei, Daten global sichtbar zu machen und sie je nach Bedarf zwischen den Standorten zu aggregieren, wobei die Workflows über Kundenrichtlinien festgelegt werden.

Hammerspace will Datennutzern einen echten globalen Datenzugriff ohne Datensilos oder Einschränkungen durch Data Gravity ermöglichen. Dafür werden im ersten Schritt nur die Metadaten an verschiedene Standorte repliziert. Die Daten selbst werden nur bei Bedarf zur Gänze am anderen Standort geladen. Metadaten und Daten selbst sind voneinander separiert. Dies soll vor allem die Datenorchestrierung erleichtern, da Anwender mittels der Metadaten immer wissen, wo sich all ihre Daten befinden. Das Unternehmen verspricht schnelleres, granulares und transparentes Datenmanagement.
Dem Anwender wird so die Möglichkeit gegeben, die Daten des Unternehmens zu sehen und sie von einem Ort aus zu verwalten, unabhängig davon, auf welchem On-Premise- oder Cloud-Speicher sie gespeichert sind. Diese Daten werden – wie erwähnt – nur bei Bedarf oder gemäß den Vorgaben von richtlinienbasierten Tools in ihrer Gesamtheit verschoben. Durch die granulare Sichtbarkeit der daten kann der Admin entscheiden, was mit den Daten geschehen soll. So kann der IT-Verantwortliche zum Beispiel festlegen, dass die Daten nach einer bestimmten Zeit verschoben und für die Verarbeitung durch eine bestimmte Anwendung bereitgestellt werden. So lassen sich der mögliche Migrationsbedarf absehen und besser planen.
Die Basis der softwaredefinierten Lösung ist ein globales paralleles File System mit einem einzigen Namespace, das gemischte I/Os und jegliche Workload unterstützt. Zudem kann der Admin GPUs direkt ansprechen, einen Cloud Burstumsetzen oder die Kapazität linear nahezu unbegrenzt skalieren. Die Software verfügt über ein universelles POSIX-Dateisystem und ist in Linux integriert. Hammerspace nutzt eine NAS-Architektur, die Standard-Datenservices gewährleistet und bestehende Infrastrukturen nutzen kann, wie beispielsweise Ethernet oder Infiniband. Damit soll die Lösung dem RAS-Konzept (Reliability, Availability, Serviceability) dienen. Für die Data Orchestration ermöglicht der Anbieter, Metadaten von vielen Quellen an multiple Ziele zu senden, unabhängig vom Rechenzentrumsspeicher, der Region oder des Cloud Service Providers. Die Daten werden unterbrechungsfrei verschoben. Durch seine Struktur stellt die Software globale Data Governance bereit, die sich simpler gestalten lassen soll, da Datenkopien per se nicht notwendig sind.
Flaschenhälse beim Datenzugriff eliminieren
Jede Speicherarchitektur hat unterschiedliche Merkmale und auch verschiedene Einschränkungen, die Anwender verstehen müssen, um die für sie geeignete Speicherumgebung auszuwählen. Bei einem Direct Attached Storage ist beispielsweise der RAID-Controller der Flaschenhals und fügt eine zusätzliche serielle Datenübertragung hinzu. Dies lässt sich durch den Einsatz von NVMe-Technologie umgehen, da sie den Controller überflüssig macht. Mit GPU Direct lässt sich auch die Host-CPU und das Memory umgehen, so dass der Datenzugriff optimal erfolgen kann. Bei verteiltem Storage sieht das ein wenig komplexer aus.
In einer Network-Attached-Storage-Architektur ist der Host für das Storage-Backend (CPU und Memory) einer von neun Flaschenhälsen im Stack, ebenso das Dateiserver-Frontend. NSFv4.2 mit eSSDs kann sechs von neun Schritten bei der Datenübertragung eliminieren. Dadurch lassen sich geringere Latenzzeiten, weniger Stromverbrauch und Write Amplification sowie eine höhere Zugriffsdichte erreichen. Hammerspace verfolgt diesen Ansatz und nimmt die Metadaten aus dem Datenpfad zum Storage heraus. Die Lese- und Schreib-I/Os der Clients werden direkt an die Storage-Volumes transferiert. Hierfür unterstützt die Lösung TCP und RDMA und separiert die Datenplatzierung von den Storage-Volumes im Backend. Die Metadaten liegen hochverfügbar auf einer Metadata Service Node (Anvil mit NFSv4.2 Flex Files), der DSX Store des Hersteller transportiert die Daten via NVMe, SCSI oder ATA an das Storage.
Zu den Storage-Funktionen des DSX gehören:
- Bereitstellung als Bare Metal, virtuell oder Container
- Parallele, linear skalierbare Performance
- Unterstützt jeden Blockspeicher (DAS: SSD, NVMe, HDD oder NAS: SAN, iSCSI, EBS)
- Unterstützt geteilte Snapshots und File-Klone
- Schreib-I/Os können auf multiple DSX-Nodes gespiegelt werden
- Nutzung von Gruppen an DSX-Nodes mit Erasure Coding
Eine DSX-Node kann auch als Mover zu Cloud-Umgebungen eingesetzt werden. Diese Nodes sind stateless und lassen sich nach dem Scale-Out-Prinzip erweitern. Datentransfer kann vollautomatisch geplant werden. Für den File-Transfer kommt NFSv3 zum Einsatz. Azure Blob, S3 und andere Objektspeicher werden über HTTPS angesprochen. Der Mover ermöglicht globale Deduplizierung, Kompression und Verschlüsselung.
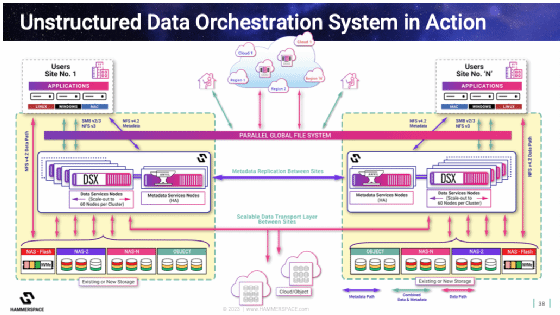
Anwender, die noch Legacy-Clients einsetzen, können eine DSX-Node mit Portalfunktionen einsetzen, das zwischen den Clients und dem DSX Store sitzt. Es verfügt über virtuelle IPs mit Failover, verwendet NFSv3, SMB und S3 sowie ein globales File Locking. Methoden für das Caching sind write-back und write-through, welches für Metadaten und Lesezugriffe genutzt wird.
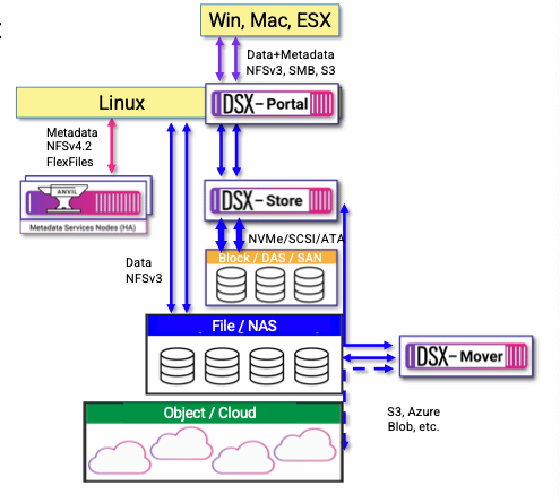
Nicht zuletzt lassen sich mit einer DSX-Node auch containerisierte Microservices umsetzen. Dies soll Bereitstellungsflexibiltät, offerieren sowie Netzwerk-Hops vermeiden und volle NVMe-Leistung garantieren. Der Hersteller sieht unter anderem Anwendungsszenarien im High Performance Computing und in der Orchestrierung unstrukturierter Daten.
Zu weiteren Funktionseigenschaften gehören, die folgenden, die der Anbieter zudem als Unterscheidungsmerkmal zu anderen Wettbewerbern sieht:
- Data-in-Place-Assimilation
- Schnell einsatzbereit (in weniger als einem Tag)
- Ein einziges Dateisystem kann bis zu 16 und mehr Rechenzentren umfassen
- Statt Datenkopien werden Instanzen erstellt, was unkontrollierten Datenwildwuchs verhindert
- Daten werden quasi mit push und pull an andere Standorte transportiert
- Data Tiering erfolgt zwischen verschiedenen Speichersystemen
- Daten lassen sich in multiplen Objekt-Buckets speichern (in bis zu 100 Buckets)
- Transparente Live-Datenmobilität
- Anpassbare Metadaten (Datei-granulare Datenservices)
- Lässt sich mit ISV-Lösungen für die Orchestrierung von File-Daten integrieren
- Software-defined und Hardware-agnostische Lösung
- Keine proprietären Clients notwendig
- Dateiversionierung
- Löschvorgänge rückgängig machen
Hammerspace sieht sich als alternative zu Public-Cloud-Angeboten, die bezüglich der Datentransfers oder -verschiebens kostspielig sein können. In den meisten Fällen fällt zusätzlicher Migrations- und Managementaufwand an. Der Hersteller adressiert hier das Problem der Data Gravity, die den unkomplizierten und schnellen Transport von Daten von einem Standort an einen anderen erschweren kann.
Auch Einsatzmöglichkeiten in KI-Umgebungen
Immer mehr Unternehmen setzen KI-Technologien ein oder planen dies zu tun. Dabei ist eine der größten Herausforderungen, verteilte, unstrukturierte Datensätze für die KI-Strategien zu nutzen und gleichzeitig hohe Leistung und Skalierbarkeit zu bieten. Dafür offeriert Hammerspace eine dedizierte Referenzarchitektur, die es ermöglicht, Datensätze aus jedem bestehenden Speichersilo zu laden und neue Datensätze oder Datenquellen mit einem Klick hinzuzufügen. Unabhängig davon, wo sich das KI-Modell befindet, ob lokal bei den Daten oder in einer entfernten Cloudoder einem SaaS-Tool, mit der Lösung sind die Daten zugänglich, analysierbar, verarbeitbar und bei Bedarf verschiebbar.
Die Lösung unterstützt verschiedene KI-Modelle, beispielsweise Databricks und Snowflake. Laut Herstellerangaben kann die KI-Architektur große Compute-Farmen unterstützen, mit mehr als 60.000 GPUs in einem einzigen Cluster. Oft ist es wünschenswert, mehrere GPU-Cluster zu nutzen, um die Rechenressourcen bei Bedarf zur Verfügung zu haben, ohne dass ein ständiger Overhead durch die Aufrechterhaltung der maximalen Kapazität entsteht. Hier soll die Software entsprechende Flexibilität durch Anpassungsfähigkeit und Burst zu entfernten GPU-Clustern gewährleisten.
Darüber hinaus sollen KI-Umgebungen von den allgemeinen Vorteilen der Hammerspace-Lösung profitieren, wie hohe Skalierbarkeit, Parallelisierung, schnellen Zugriff auf verteilte Daten und Datenorchestrierung. Hammerspace gehört zu einer Gruppe von Produkten, die darauf abzielen, globalen Dateizugriff und Zusammenarbeit mit Zugriff auf die neueste Version von Dateien von jedem Ort aus zu ermöglichen. Zu den Wettbewerbern gehören Ctera, Nasuni, Panzura und Peer Software.





