
Getty Images/iStockphoto
Object Storage für KI: Große Datenmengen besser speichern
Beim Einsatz von KI stellt sich die Frage, welches Storage-System am besten geeignet ist. Object Storage kann eine gute Lösung sein. Der Beitrag zeigt, was wichtig ist.

Object Storage ist ein Ansatz zum Speichern von Daten als Objekte im Gegensatz zu herkömmlichen Methoden wie Dateisystemen oder blockbasierten Speicherungen. Jedes Objekt enthält die Daten selbst, Metadaten und einen global eindeutigen Identifier. Dieser Ansatz ist insbesondere für die Skalierung auf große Mengen geeignet, da die Daten über verschiedene Geräte und Standorte verteilt werden können.
Vorteile von Object Storage für KI
Bei der Durchführung von KI-Projekten fallen oft riesige Mengen an Daten an. Diese Daten müssen gespeichert, verwaltet und analysiert werden. Hier bietet Object Storage erhebliche Vorteile:
- Da Object Storage horizontal skaliert wird, können große Datenmengen ohne Leistungseinbußen gespeichert und abgerufen werden.
- Die Daten sind über mehrere Standorte und Geräte verteilt, was für eine hohe Verfügbarkeit und Fehlertoleranzsorgt.
- Die Fähigkeit, Metadaten direkt mit den Daten zu speichern, ermöglicht eine bessere Datenanalyse und Datenverwaltung.
Integration von Object Storage in KI-Prozesse
Object Storage lässt sich nahtlos in KI-Prozesse integrieren. Datenpipeline-Tools und Frameworks für maschinelles Lernen (ML) können direkt auf die in Object Storage gespeicherten Daten zugreifen. Das eliminiert den Bedarf an kostspieligen und zeitaufwändigen Datenmigrationen.
Durch die Nutzung von Object Storage können Unternehmen erhebliche Kosteneinsparungen erzielen. Anstatt teure, hochleistungsfähige Speicherlösungen zu kaufen, können sie kostengünstigere, objektbasierte Speicher nutzen. Das reduziert die Total Cost of Ownership und ermöglicht es Unternehmen, mehr Ressourcen in ihre KI-Projekte zu investieren.
Darauf müssen Unternehmen beim Einsatz von Object Storage achten
Wenn Unternehmen Object Storage für KI-Anwendungen in Betracht ziehen, sollten sie eine Reihe von Faktoren berücksichtigen. Zu den wichtigsten gehört die Skalierbarkeit, um den wachsenden Datenanforderungen gerecht zu werden. Die Speicherlösung sollte auch eine hohe Datenverfügbarkeit und -integrität gewährleisten, um den kontinuierlichen Datenfluss für KI-Prozesse zu sichern. Außerdem ist die Unterstützung von Multi-Cloud-Umgebungen vorteilhaft, um Flexibilität und Redundanz zu gewährleisten. Die Interoperabilität mit gängigen KI-Frameworks und -Tools kann den Integrationsaufwand erheblich reduzieren. Einige bekannte Object-Storage-Lösungen, die in KI-Umgebungen häufig eingesetzt werden, sind Amazon S3, Google Cloud Storage und IBM Cloud Object Storage.
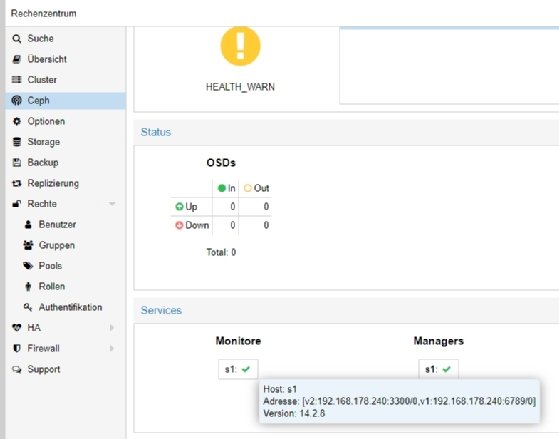
Open-Source-Storage-Lösungen für Object Storage haben in den letzten Jahren an Bedeutung gewonnen, da sie Unternehmen die Flexibilität bieten, Speicherlösungen an ihre spezifischen Anforderungen anzupassen, ohne an proprietäre Technologien gebunden zu sein. Eines der bekanntesten Open-Source-Object-Storage-Systeme ist Ceph.
Ceph bietet nicht nur Object Storage, sondern auch block- und dateibasierte Speicherung in einem einheitlichen System. Ein weiteres beliebtes Produkt ist MinIO, das für seine hohe Leistung und einfache Skalierbarkeit bekannt ist. Open-Source-Storage-Lösungen bieten eine Reihe von Vorteilen, darunter Kosteneffizienz, Transparenz und Anpassungsfähigkeit, da der Quellcode zugänglich und modifizierbar ist und eine aktive Community-Unterstützung, die bei Problemen und Weiterentwicklungen hilft. Darüber hinaus ermöglichen sie Unternehmen, Speicherlösungen unabhängig von kommerziellen Anbietern zu entwickeln und zu betreiben, wodurch potenzielle Vendor Lock-insvermieden werden.
Object Storage ist nicht immer ideal für den Einsatz mit KI
Obwohl Object Storage viele Vorteile für KI-Anwendungen bietet, gibt es Szenarien, in denen der Ansatz weniger geeignet ist. Beim Einsatz von Anwendungen, die eine sehr geringe Latenz erfordern oder bei denen Daten häufig aktualisiert werden müssen, kann Object Storage suboptimal sein, da der Zugriff auf Daten in objektbasierten Speichern manchmal weniger reaktionsfreudig ist als bei blockbasierten Lösungen.
Object Storage ist nicht ideal für relationale Datenbankanwendungen oder Anwendungen, die intensiven Random-Access auf kleinere Datenmengen benötigen. In solchen Fällen können blockbasierte Speicherlösungen oder hoch-performante Dateisysteme besser geeignet sein. Alternativen zu Object Storage sind unter anderem traditionelle SAN-Systeme, NASoder spezielle Dateisysteme wie Hadoop HDFS, die speziell für Big-Data-Anwendungen und KI entwickelt wurden.
Die Beschleunigung von Object Storage ist also entscheidend, um eine optimale Leistung für KI-Anwendungen zu gewährleisten. Hierbei kann das Einsetzen von Caching-Mechanismen den Datenzugriff beschleunigen, indem häufig abgerufene Daten vorgehalten werden. Lösungen wie Redis bieten sich hier als Open Source In-Memory-Datenstruktur-Speicher an, der als Cache genutzt werden kann. Ebenfalls hilfreich ist die Verwendung von Datenkomprimierung. Lösungen wie LZ4 ermöglichen eine schnelle Komprimierung und Dekomprimierung und können die Menge der zu übertragenden Daten reduzieren. Zudem kann das Verteilen von Daten über mehrere Speicherorte mit Tools wie Rook, einem Open Source Cloud-Native Storage-Orchestrator, optimiert werden, um Redundanz zu gewährleisten und den parallelen Datenzugriff zu beschleunigen.
Schließlich ist es von Vorteil, den Object Storage direkt an die KI-Verarbeitungseinheit, wie GPUs, anzubinden, um den Datenzugriff zu optimieren. Hierfür können Lösungen wie NVIDIA Triton Inference Server hilfreich sein, die den direkten Datenfluss zwischen Storage und GPU gewährleisten. Durch die Kombination dieser Maßnahmen und Open-Source-Tools können Unternehmen ihre Object-Storage-Lösungen so optimieren, dass sie den hohen Anforderungen von KI-Workloads gerecht werden, wenn ansonsten die Leistung nicht ausreichen würde.
Optimierungsmöglichkeiten für den Object Storage beachten
Für Profis, die sich intensiv mit Object Storage im Kontext von KI beschäftigen, sind tiefgreifende Optimierungsmöglichkeiten von besonderer Relevanz. Erstens, die Datenlokalisierung: Es ist entscheidend, dass Daten in der physischen Nähe zu den KI-Verarbeitungseinheiten, zum Beispiel GPUs, gespeichert werden, um Netzwerklatenz zu minimieren. Das ist besonders wichtig in Umgebungen mit NVMe-over-Fabrics, die es ermöglichen, direkten Memory-Access über Netzwerke hinweg zu nutzen.
Durch den Einsatz von benutzerdefinierten Metadaten und Tagging können Datenintelligenz und Datenmanagement erheblich verbessert werden. Tools wie das RADOS Gateway in Ceph bieten erweiterte Metadaten-Funktionen, die für KI-Anwendungen nützlich sein können. Während viele Object-Storage-Systeme eine eventuelle Konsistenz bieten, kann es in einigen KI-Szenarien notwendig sein, stärkere Konsistenzmodelle zu implementieren, insbesondere wenn Datenaktualität kritisch ist.
Schließlich ist die Integration von erweiterten Sicherheitsprotokollen, wie Data-at-Rest- und Data-in-Transit-Verschlüsselung, essentiell, um sicherzustellen, dass KI-Daten sowohl beim Speichern als auch bei der Übertragung geschützt sind. Ein tiefes Verständnis dieser Aspekte und deren Implementierung kann den Unterschied in der Effizienz und Effektivität von KI-Anwendungen, die Object Storage nutzen, ausmachen.






