
phimprapha - stock.adobe.com
Veeam Backup & Replication: Instant Recovery und CDP nutzen
CDP und Instant Recovery sind zwei leistungsstarke Funktionen, mit denen sich die Cyberresilienz verstärken lässt. Wir erklären am Beispiel von Veeam, wie sich dies umsetzen lässt.

Backup und Recovery sowie Disaster Recovery (DR) sind längst nicht mehr nur eine Pflichtdisziplin der IT, sondern ein entscheidender Faktor für Cyberresilienz und Business Continuity. Ransomware-Angriffe, Ausfälle kritischer Systeme oder fehlerhafte Updates zeigen, wie schnell moderne IT-Landschaften unter Druck geraten können. Unternehmen benötigen heute Wiederherstellungsoptionen, die flexibel, schnell und granular sind. Hierfür lassen sich Cloud-Umgebungen wie Microsoft Azure sich als skalierbare DR-Ziele perfekt einbinden.
Mit Continuous Data Protection (CDP) und Instant Recovery to Azure bietet Veeam zwei Technologien, die Cloud Service Provider (CSPs) wie auch interne IT-Teams unterstützen, Ausfälle zu minimieren, Wiederherstellungszeiten drastisch zu verkürzen und gleichzeitig Forensik- oder Testumgebungen bereitzustellen. Besonders wertvoll: Beide Technologien lassen sich kombinieren und bieten damit ein Widerstandsfähigkeitsniveau, das klassische Backup-Modelle allein kaum erreichen.
Wir erklären, wie CDP und Instant Recovery funktionieren, welche technischen Schritte anfallen und wie Unternehmen sie sinnvoll einsetzen. Darüber hinaus nutzen wir das Beispiel der Veeam Backup & Replication Platform, wie sich diese Technologien umsetzen lassen.
Veeam Backup & Replication 13
Die Veeam Backup & Replication Platform wurde bereits 2008 auf den Markt gebracht und wurde seitdem kontinuierlich weiterentwickelt und schließlich in Veeam Data Platform umbenannt. Ende 2025 stellet der Anbieter nun die 13. Generation der Lösung vor. Mit der neuen Version legt der Hersteller den Fokus ganz auf Cyberresilienz, integrierte Sicherheit und intelligente Automatisierung für hybride und Multi-Cloud-Umgebungen. Dies soll durch erweiterte Backup- und Recovery-Prozesse gestützt werden. Die Plattform adressiert explizit Ransomware-Szenarien, forensische Auswertungen und die Absicherung moderner Workloads von On-Premises bis Public Cloud.
Kernthemen der Version 13
Veeam erweiterte die Plattform um neue Funktionen zur Erkennung und Abwehr von Bedrohungen, beschleunigten Wiederherstellungsprozessen sowie tiefergehenden forensischen Einblicken in kompromittierte oder verdächtige Workloads. Parallel dazu stärkt die Lösung die Unterstützung für Cloud-native Dienste und hybride Szenarien, etwa durch erweiterten Objektspeicher-Support und Backup für Identitätsdienste wie Entra ID.
Security und Ransomware-Schutz
Ein Schwerpunkt liegt auf Security-by-Design mit erweiterten Malware- und Anomalie-Erkennungsfunktionen, die Backups und Workloads aktiv auf verdächtige Aktivitäten prüfen; hier spielt insbesondere der integrierte Veeam Recon Scanner 3.0 in der Premium-Edition eine zentrale Rolle. Ergänzt wird dies durch tiefere Integrationen in etablierte Security- und IT-Ops-Plattformen wie CrowdStrike, Palo Alto Networks, Splunk und ServiceNow, um Erkennung, Investigation und Response stärker zu verzahnen.
Intelligente Automatisierung und KI
Mit neuen KI-gestützten Funktionen im Rahmen von Veeam Intelligence beziehungsweise dem Veeam Intelligence Mode nutzt die Plattform Telemetriedaten und Backup-Metadaten, um Admins automatisiert Analysen, Empfehlungen und optimierte Workflows bereitzustellen. Ziel ist es, Reporting, Fehleranalyse und Recovery-Entscheidungen stärker zu automatisieren und so Betriebsteams zu entlasten.
Plattform- und API-Neuerungen
Die neue Universal Hypervisor Integration API schafft eine einheitliche Integrationsschicht für unterschiedliche Hypervisoren und erleichtert damit sowohl die Abdeckung weiterer Plattformen als auch Migrationsszenarien. Zudem treiben ein modernisiertes Web-UI, Linux-basierte Software-Appliances und erweiterte Hochverfügbarkeitsoptionen innerhalb der Veeam Data Platform v13 die Konsolidierung und Standardisierung der Backup-Umgebung voran.
Die Funktionen Continuous Data Protection (CDP) und Instant Recovery sind nicht neu, wurden aber stetig optimiert. Sie sind Kernkomponenten für zuverlässige Datensicherungen und erfolgreiche und zügige Wiederherstellungen, was wiederum genauso wichtig für eine solide Cyberresilienz wichtig ist wie die Neuerungen in der Plattform.
Continuous Data Protection: Minimale RPOs für kritische Workloads
Bei klassischen Datensicherungen entstehen zwangsläufig Recovery Point Objectives (RPOs) im Stunden- oder Minutenbereich – je nach Backup-Fenster. In einer Welt, in der wenige Sekunden Datenverlust teuer werden können, reicht das oft nicht mehr aus.
Continuous Data Protection schließt diese Lücke: Statt periodischer Sicherungen werden Änderungen kontinuierlich auf Blockebene übertragen. Dadurch entsteht ein Zeitstrahl an Wiederherstellungspunkten, die extrem fein granuliert sind.
Gerade bei schnelllebigen oder geschäftskritischen Systemen – Datenbanken, Transaktionsserver, ERP – kann dieser Ansatz den Unterschied ausmachen zwischen einem kurzen Eingriff und einem stundenlangen Wiederanlauf.
Eine CDP-Richtlinie einrichten
Mit Veeam erfolgt die Konfiguration einer CDP-Policy direkt im Bereich Disaster Recovery Infrastructure → CDP Replicas. Der Wizard führt technisch klar und nachvollziehbar durch die einzelnen Schritte:
- Auswahl der Quell-VM: Administratoren wählen die zu schützenden VMware-Workloads aus. Die Integration erfolgt eng mit vSphere. Der Anbieter nutzt vSphere APIs for I/O Filtering (VAIO), um Änderungen unmittelbar zu erfassen.
- Ziel-Host, Resource Pools und Datastores definieren: Die Replikate werden auf einem alternativen Cluster abgelegt, idealerweise an einem zweiten Standort oder in einer separaten Umgebung, die unabhängig vom produktiven System läuft.
- RPO-Fenster und Retention-Zeit festlegen: CDP-Policies lassen sich in Veeam sehr granular steuern. Admins definieren, in welchem Intervall Änderungen übertragen werden und wie lange Short-Term- beziehungsweise Long-Term-Retention-Punkte vorgehalten werden. So entsteht eine feine Timeline mit Wiederherstellungspunkten im Sekundenbereich für aktuelle Incidents sowie weiter zurückreichenden Restore-Punkten, etwa um unentdeckte Ransomware-Aktivitäten sauber zu umgehen.
- Aktivierung: Nach der Aktivierung des CDP erscheinen die Replika-VMs unter CDP Replicas. Sie werden laufend aktualisiert, ohne dass die Produktion merklich belastet wird.
Neben dem vSphere-basierten CDP mit VAIO-Treiber erweitert Veeam die Funktion mit Universal CDP um einen agentenbasierten Ansatz: Windows- und Linux-Systeme – physisch oder auf verschiedenen Hypervisoren – lassen sich so kontinuierlich auf eine vSphere-Zielumgebung replizieren, ohne auf Hypervisor-Snapshots angewiesen zu sein. Perspektivisch soll Universal CDP auch Ziele in Hyperscaler-Umgebungen wie AWS oder Azure unterstützen, um Recovery-SLAs in hybriden Szenarien weiter zu verbessern.
Failover-Prozess: Nahtloser Übergang im Notfall
Kommt es zu einem Ausfall, kann ein Failover direkt über den Veeam-Dialog angestoßen werden:
- Auswahl eines präzisen Wiederherstellungspunktes
- Start der Replikat-VM
- Weiterbetrieb in der DR-Umgebung mit minimaler Unterbrechung
Gerade in Kombination mit granularen Retention-Punkten wird Auffälliges (zum Beispiel erste Ransomware-Aktivitäten) schnell erkannt und rückgängig gemacht, ein Vorteil, der klassischen Backup-basierten Strategien oft fehlt.
Nach einem Failover können Unternehmen entscheiden, ob die Zielseite dauerhaft produktiv bleiben oder ob nach der Fehlerbehebung ein Failback zur ursprünglichen Umgebung erfolgen soll. Veeam synchronisiert dabei die seit dem Failover angefallenen Änderungen zurück und räumt die temporären Ressourcen auf, sodass der Schutzstatus mit minimalem Zusatzaufwand wiederhergestellt wird.
Planen Sie für CDP-Policies immer mehrere Rollback-Punkte ein. Gerade bei unentdeckten Angriffen schützt nicht der neueste, sondern der sauberste Wiederherstellungspunkt.
Instant Recovery: Workloads in Azure innerhalb weniger Minuten starten
Das Grundprinzip eines Instant Recovery ist, dass man nicht alles an einen anderen Standort kopiert werden muss, sondern virtuelle Maschinen (VMs) für die Wiederherstellung schnell aufgesetzt, gestartet und für Workloads bereitgestellt werden können. Während CDP den Datenverlust minimiert, löst Instant Recovery ein zweites Kernproblem: die Wiederherstellungszeit. Statt lange auf einen vollständigen Restore zu warten, startet die VM direkt aus einem Backup heraus.
Das bedeutet, dass Anwender nicht auf die vollständige Datenübertragungen warten müssen, selbst große VMs sich in Kürze starten lassen und im Hintergrund parallel eine Migration in Azure erfolgt.
Laut Herstellerangaben war es mit der Plattform möglich, ein 32-TByte-großes System in nur 11 Minuten zu starten.
Voraussetzungen für die Wiederherstellung in Azure
Instant Recovery funktioniert, wenn Sicherungen in folgenden Zielen gespeichert sind:
- Azure Blob Storage
- Veeam Data Cloud Vault (gemanagter, gehärteter Object Storage)
Gerade das Vault bietet Vorteile hinsichtlich Sicherheit und Fehlkonfigurationsschutz. Er fungiert als zuverlässiges Ziel für Unternehmen, die Backups in die Cloud auslagern möchten, ohne selbst Storage-Sicherheitsrichtlinien verwalten zu müssen. Zudem entfallen schwer kalkulierbare Einzelposten wie Egress- und API-Kosten, da das Vault als Pauschalangebot pro Terabyte abgerechnet wird.
Aufbau der Architektur: Was im Hintergrund passiert
Ein zentrales Element im Prozess ist die Helper Appliance. Da Backups in einem Object Storage nicht wie klassische Datenträger angesprochen werden können, dient diese Komponente als Übersetzer:
- Sie mountet die Backup-Daten.
- Stellt die Disks als iSCSI-Targets bereit.
- Ermöglicht einen Netzwerk-Boot (zum Beispiel über IPXE).
- Passt Metadaten wie Boot-Modus, Partitionsschema oder Treiber an.
Damit wird sichergestellt, dass die wiederhergestellte VM auch in der Azure-Hardwareumgebung korrekt startet. Besonders interessant ist diese Funktion für heterogene Szenarien, beispielsweise die Migration einer vSphere-VM nach Azure.
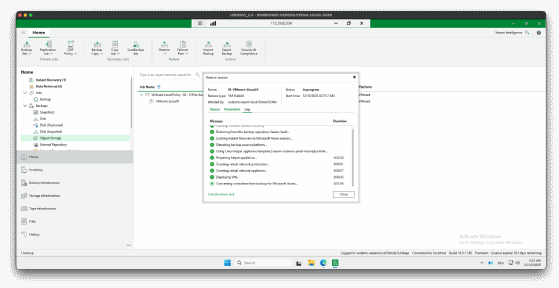
Schrittfolge im Wiederherstellungsassistenten
Der Wizard der Plattform ist übersichtlich und intuitiv und führt strukturiert durch alle nötigen Schritte. Für das Instant Recovery sehen diese Schritte so aus:
- Backup und Restore Point auswählen
- Azure-Abonnement wählen (Subscription), was wichtig für die Zugriffrechte ist
- Festlegen der Ressourcengruppe
- Festlegen des VNet/Subnets
- Bestimmen der Security Group
- Optional lässt sich eine Public IP auswählen
- VM-Größe bestimmen (zum Beispiel kleine SKU für Tests, große SKU für Produktion)
- Helper Appliance bereitstellen
- Start der VM direkt aus dem Backup
- Migration in Azure Managed Disks im Hintergrund
Für Cyber-Recovery-Szenarien empfiehlt es sich, ein isoliertes Netzwerk oder Fenced Network auszuwählen. So können kompromittierte Systeme gefahrlos analysiert werden, um sicherzustellen, dass sie kein Risiko bei der Wiederherstellung darstellen.
Migration to Production: Der finale Schritt
Beim abschließenden Switchover von der Instant-Recovery-Session auf produktive Azure Managed Disks ist eine kurze Unterbrechung erforderlich, da die laufende VM angehalten und der Rest der Datenkopie abgeschlossen werden muss. Anders als beim Instant Recovery zu vSphere, wo der Übergang nahtlos erfolgen kann, planen Admins den Zeitpunkt in Azure typischerweise in Wartungsfenster oder außerhalb der Geschäftszeiten ein.
Das Ergebnis des Switchover ist eine produktive, in Azure laufende VM mit nativen Managed Disks.
Instant Recovery to Azure ist darauf ausgelegt, mehrere virtuelle Maschinen parallel hochzufahren und eignet sich damit auch für umfangreichere DR- oder Cyber-Recovery-Szenarien. In größeren Umgebungen lässt sich dieser Ansatz mit Veeam Recovery Orchestrator kombinieren, um Startreihenfolgen, Netzwerkanbindungen und Tests automatisiert zu planen und zu dokumentieren.
Wichtige Einsatzszenarien
Es gibt verschiedene Szenarien, in denen sich diese Funktion zum Vorteil eines Unternehmens oder nutzen lassen. Dazu gehören unter anderem
- Cyber Recovery und Forensik: Durch das Starten einer kompromittierten VM in einer isolierten Cloud-Umgebung lassen sich Ursachen analysieren, ohne die Produktion zu gefährden.
- Disaster Recovery: Kritische Workloads laufen im Fehlerfall schnell in Azure an, während CDP Datenverlust auf ein Minimum reduziert.
- Test- und Entwicklungsumgebungen: Backups lassen sich problemlos für funktionale Tests, Lasttests oder Patch-Analysen nutzen, ohne das Live-System zu beeinflussen.
- Flexible Workload-Mobilität: Workloads können je nach Bedarf zwischen On-Premises vSphere und Microsoft Azure verlagert werden – ein wertvoller Vorteil in Hybrid-Cloud-Szenarien.
Starke Resilienz mit CDP und Instant Recovery
Die Kombination aus Continuous Data Protection und Instant Recovery, sei es wie in unserem Beispiel zu Azure oder zu anderen lokalen oder Cloud-Ressourcen, bietet einen modernen, leistungsstarken Ansatz für IT-Resilienz. Unternehmen erhalten damit sowohl minimale RPOs als auch extrem verkürzte RTOs. Besonders in Zeiten wachsender Cyberbedrohungen ist diese Kombination ein effektives Mittel, um geschäftskritische Systeme schnell wieder ans Laufen zu bringen – sei es am eigenen Standort oder in der Public Cloud.
Wer seine DR-Strategie modernisieren möchte, sollte CDP und Instant Recovery nicht als Alternativen sehen, sondern als komplementäre Technologien. CDP schützt vor Datenverlust, Instant Recovery vor langen Wiederanlaufzeiten – zusammen ergeben sie eine belastbare, zukunftssichere Recovery-Architektur.






