Vektordatenbank

Was ist eine Vektordatenbank?
Eine Vektordatenbank ist eine Datenbanktechnologie, die zum Speichern, Verwalten und Durchsuchen von Vektoreinbettungen verwendet wird, das heißt von numerischen Darstellungen unstrukturierter Daten, die auch einfach als Vektoren bezeichnet werden. Vektordatenbanken waren lange Zeit eine Nischentechnologie, werden aber heute immer häufiger zur Unterstützung von Anwendungen im Bereich der künstlichen Intelligenz (KI) und des maschinellen Lernens eingesetzt, darunter auch generative KI (GenAI).
Anstatt unstrukturierte Datenobjekte als Text-, Bild- oder Video- und Audiodateien zu speichern, werden sie in einer Vektordatenbank als eine Reihe von Zahlen gespeichert, die in einem mehrdimensionalen Raum dargestellt werden. Die Grundidee hinter der Verwendung hochdimensionaler Vektoren besteht darin, dass die zugewiesenen Zahlen die semantische Bedeutung verschiedener Datenpunkte präziser darstellen können als herkömmliche textbasierte Metadaten zur Beschreibung der Daten.
Vektordatenbanken sind so optimiert, dass Benutzer oder Anwendungen relevante Daten mithilfe von Vektorsuchtechniken, die Datenpunkte anhand ihrer Ähnlichkeit oder ihrer Nähe zueinander abgleichen, effektiv finden und abrufen können. Daher wird die Suchfunktion auch als Vektorähnlichkeitssuche bezeichnet.
Es gibt mehrere Formen von Vektordatenbanktechnologien. Dazu gehören speziell entwickelte Vektordatenbanken, die nur die Vektorspeicherung unterstützen und manchmal als native Vektordatenbanken bezeichnet werden. Auch in Multi-Modell-Datenbanken, die für die Verwendung mit verschiedenen Datenmodellen ausgelegt sind, werden Vektoren und die Vektorsuche immer häufiger unterstützt.
Warum sind Vektordatenbanken wichtig?
Vektordatenbanken wurden erstmals in den frühen 2000er Jahren als eigenständige Produktkategorie entwickelt, doch das Interesse an ihnen steigt mit der zunehmenden Verbreitung von KI- und maschinellen Lerntechnologien. Sie sind aus folgenden Gründen für Organisationen wichtig:
- Semantische Suche und Ähnlichkeitsabgleich. Bei einer herkömmlichen Datenbank werden Suchvorgänge oft als Keyword-Match-Funktion ausgeführt. Vektordatenbanken ermöglichen es Benutzern, Daten basierend auf ihrer Bedeutung und ihrem Kontext zu suchen und abzugleichen. Dies ermöglicht hochpräzise Verknüpfungen, die zur Unterstützung mehrerer Anwendungsfälle genutzt werden können, die von anderen Datenbankarten nicht gut bedient werden.
- Unterstützung multimodaler Anwendungen. Im Gegensatz zum mühsamen Umgang mit verschiedenen Datentypen speichert und ruft eine Vektordatenbank Daten über mehrere Modi hinweg auf die gleiche Weise ab. Text, Bilder, Video, Audio und mehr werden alle als Vektoren im gleichen mehrdimensionalen Einbettungsraum dargestellt, der manchmal auch als Vektorraum bezeichnet wird. Dies ermöglicht multimodale Anwendungen, wie zum Beispiel die Multimedia-Suche und das Abrufen von Daten über verschiedene Datentypen hinweg.
- Verbesserung generativer KI-Anwendungen. Der vielleicht wichtigste Grund, warum Vektordatenbanken heute wichtiger sind als früher, ist das rasante Wachstum der Large Language Models (LLMs), die ChatGPT, Gemini, Microsoft Copilot und andere GenAI-Tools antreiben. Die Datenbanken sind eine Schlüsselkomponente in verschiedenen GenAI-Anwendungen. Beispielsweise kann eine Vektordatenbank als Wissensspeicher für aktualisierte Informationen dienen, auf die ein LLM zugreifen kann, um die Genauigkeit der GenAI-Antworten zu verbessern. Dieser Ansatz wird als Retrieval-augmented Generation (RAG) bezeichnet.
Was sind Vektoreinbettungen?
Vektoreinbettungen sind der Datentyp, der in einer Vektordatenbank gespeichert wird. Die numerischen Darstellungen in einer Vektoreinbettung sollen die Bedeutung eines Datenpunkts und seine Beziehung zu anderen Datenentitäten erfassen, zum Beispiel die Wörter in einem Satz oder verschiedene Phrasen.
Eine Vektoreinbettung wandelt Datenpunkte in ein Zahlenfeld über mehrere Dimensionen um. Jede Dimension steht für ein bestimmtes Merkmal oder Attribut, das einen Aspekt der Bedeutung oder des Kontexts der Daten erfasst. Ähnlichkeitsmetriken werden dann verwendet, um Datenpunkte in einem Einbettungsraum zu positionieren, wenn in einer Vektordatenbank gesucht wird. Datenpunkte mit ähnlichen Attributen werden näher beieinander platziert als solche, die sich stärker voneinander unterscheiden.
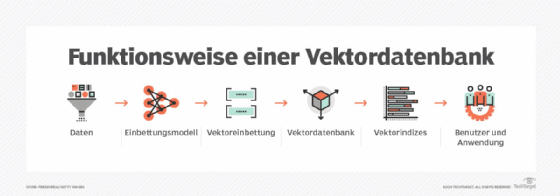
Wie funktionieren Vektordatenbanken?
Vektordatenbanken bieten Mechanismen, mit denen Benutzer Vektoreinbettungen aufnehmen, speichern und verwalten und dann Suchvorgänge in den Einbettungen ausführen können, um ähnliche oder relevante Daten zu finden. Hier ist eine schrittweise Erklärung der Funktionsweise der Datenbanken:
- Datenerfassung und Vektorisierung. Der erste Schritt besteht darin, die Rohdaten zu erfassen und in Vektoreinbettungen umzuwandeln. Letzteres geschieht, indem die Daten in ein Einbettungsmodell eingespeist werden, eine Art neuronales Netz, das maschinelles Lernen und Deep-Learning-Algorithmen verwendet, um die Vektoreinbettungen zu generieren. Nach dem Training auf einem Datensatz analysiert ein Einbettungsmodell diesen, um die Muster und Beziehungen zu identifizieren, die die Grundlage für die numerischen Darstellungen in den Einbettungen bilden.
- Vektorspeicherung. Die Vektoreinbettungen oder Vektoren werden im Datenbanksystem in einem optimierten Format gespeichert, um die geplanten Anwendungen zu unterstützen.
- Vektorindexierung. Um eine effiziente Vektorsuche zu unterstützen, werden die gespeicherten Einbettungen mithilfe einer Vielzahl von Techniken indexiert, die es der Datenbank ermöglichen, bei einer Suche schnell Vektoren zu finden, die dem Abfragevektor ähnlich sind. Zu den gängigen Indexierungsansätzen gehören Hierarchical Navigable Small World (HNSW) Graphen, die Vektoren basierend auf ihrer Nähe zueinander in mehrschichtigen Graphstrukturen organisieren; Produktquantisierung (Product Quantization, PQ), die hochdimensionale Vektoren komprimiert, um den Speicherbedarf zu reduzieren und die Suchleistung zu steigern; und ortsabhängiges Hashing (Locality-sensitive Hashing, LSH), eine Technik, die Hash-Funktionen verwendet, um ähnliche Vektoren in Gruppen zusammenzufassen.
- Vektorsuche. Wenn ein Benutzer oder eine Anwendung eine Datenbankabfrage für eine Ähnlichkeitssuche sendet, wird diese in eine Vektordarstellung umgewandelt. In vielen Fällen wird ein ANN-Algorithmus (Approximate Nearest Neighbor) verwendet, um Datenpunkte zu finden, die dem Abfragevektor nahekommen, was eine gewisse Genauigkeit gegen eine schnelle Suchleistung aufwiegt. HNSW-, PQ- und LSH-Indizierung unterstützen alle ANN-Suchen. Für genauere und präzisere Suchergebnisse unterstützen einige Vektordatenbanken auch die Verwendung von KNN-Algorithmen (K-Nearest-Neighbor), um eine bestimmte Anzahl von Vektoren zu finden, die dem Abfragevektor am nächsten sind. Sowohl bei ANN- als auch bei KNN-Algorithmen basiert die Ähnlichkeit zwischen Vektoren auf einer Distanzmetrik, wie zum Beispiel Kosinus-Ähnlichkeit, euklidischer Abstand oder Punktprodukt.
- Datenabruf. Nach Abschluss der Suche ruft die Vektordatenbank die darin gespeicherten Originaldaten ab, die mit den von der Ähnlichkeitssuche zurückgegebenen Vektoren verknüpft sind. Dieser Schritt kann auch Nachbearbeitungsmaßnahmen umfassen, wie zum Beispiel die Anwendung einer anderen Ähnlichkeitsmetrik, um die nächstgelegenen Datenpunkte auf andere Weise zu ordnen.
Vektordatenbanken versus traditionelle Datenbanken
Es stehen verschiedene Arten von Datenbanken zur Verfügung. Zu den herkömmlichen Datenbanktechnologien gehören relationale Datenbanken, die Daten in zeilenbasierten Tabellen speichern und die am häufigsten verwendete Datenbanksoftware sind, da sie sich gut für Transaktionsverarbeitungsanwendungen eignen. NoSQL-Datenbanken, die ab Mitte der 2000er Jahre aufkamen, werden ebenfalls häufig in verschiedenen Anwendungen eingesetzt. Unter dem Dach der NoSQL-Technologie gibt es vier verschiedene Produktkategorien: Schlüssel-Wert-Datenbanken, dokumentenorientierte Datenbanken, spaltenorientierte Speicher und Graphdatenbanken.
Obwohl viele relationale und NoSQL-Datenbankmanagementsysteme inzwischen Multi-Modell-Unterstützung bieten, einschließlich der Möglichkeit, in einigen Fällen Vektordaten zu speichern, wird dies durch separate Produktmodule für die einzelnen Technologien erreicht. In der folgenden Tabelle werden einige der Hauptunterschiede zwischen Vektor-, relationalen und NoSQL-Datenbanken aufgeführt.
| Vektordatenbanken | Relationale Datenbanken | NoSQL-Datenbanken | |
| Datenspeicherung | Daten werden als hochdimensionale Vektoreinbettungen gespeichert. | Daten werden in Tabellen mit Zeilen und Spalten gespeichert. | Daten werden in verschiedenen Formaten gespeichert, zum Beispiel als Dokumente, Schlüssel-Wert-Paare und Diagramme. |
| Datentypen | Optimiert für unstrukturierte Daten wie Text, Bilder, Audio und Video. | Konzipiert für Transaktionen und andere Formen strukturierter Daten. | Kann in der Regel strukturierte, halbstrukturierte und unstrukturierte Daten verarbeiten. |
| Abfragen | Verwendet Ähnlichkeitssuchen auf Grundlage von Abstands- und Näherungsmetriken zwischen Vektoren. | Verwendet SQL-Abfragen auf Grundlage exakter Übereinstimmungen und Bedingungen. | Die unterstützten Abfragesprachen variieren je nach Datenbank und Datenmodell. |
| Indizierung | Verwendet spezielle Vektor-Indizierungstechniken für eine effiziente Ähnlichkeitssuche. | Verwendet B-Baum-, Hash-, Cluster-, Nicht-Cluster- und andere Indextypen. | Verwendet je nach Datenbank und Datenmodell verschiedene Indizierungstechniken. |
| Schema | Schemaloses, flexibles Datenmodell. | Festes Schema für Datenkonsistenz. | In den meisten Fällen schemalos oder flexibles Schema. |
Wie andere Datenbanktechnologien können Vektordatenbanken sowohl in der Cloud als auch in lokalen Rechenzentren eingesetzt werden. Bei Cloud-Bereitstellungen haben Benutzerorganisationen die Wahl zwischen selbstverwalteten Datenbanksystemen oder verwalteten Diensten, die von Datenbankanbietern im Rahmen von zwei Modellen angeboten werden: serverlose Datenbanken und Database as a Service (DBaaS).
Was sind Anwendungsfälle für Vektordatenbanken?
Vektordatenbanken gelten als eine spezielle Datenbanktechnologie. Dennoch eignen sie sich für zahlreiche Anwendungen und Anwendungsfälle, darunter die folgenden:
- Generative KI. Wie bereits erwähnt, ist die Vektordatenbanktechnologie eine Schlüsselkomponente in der GenAI-Entwicklung, die häufig zur Unterstützung von LLMs und RAG-Bereitstellungen eingesetzt wird.
- Empfehlungssysteme. Vektordatenbanken werden auch häufig als Grundlage für Empfehlungsmaschinen verwendet, darunter solche, die Kunden verwandte Produkte und Inhalte vorschlagen.
- Anomalieerkennung. Verschiedene Arten von Anwendungen zur Anomalieerkennung, wie zum Beispiel Betrugserkennung, Überwachung der Netzwerksicherheit und Qualitätskontrolle in der Fertigung, werden von Vektordatenbanken unterstützt.
- Computer Vision. Die Ähnlichkeitssuchfunktion einer Vektordatenbank wird häufig zur Unterstützung der Bildabfrage, Gesichtserkennung, Objekterkennung und Bildklassifizierung eingesetzt.
- Verarbeitung natürlicher Sprache. Die Vektorsuche spielt eine zentrale Rolle in Anwendungen zur Verarbeitung natürlicher Sprache in verschiedenen Bereichen, darunter Chatbots, virtuelle Assistenten und dialogorientierte KI-Technologien.
- Bioinformatik und Biowissenschaften. Die Fähigkeit, verwandte Elemente mit einer Vektordatenbank genau zu identifizieren, ist für Anwendungen wie den Vergleich von Proteinstrukturen, den Abgleich von Gensequenzen und die Arzneimittelforschung von entscheidender Bedeutung.
Welche Vorteile haben Vektordatenbanken?
Vektordatenbanken können Organisationen, ihren Softwareentwicklern und Endanwendern auf verschiedene Weise unterstützen. Zu den Vorteilen von Vektordatenbanken gehören:
- Effizientere Ähnlichkeitssuche. Bei effektiver Nutzung ermöglicht eine Vektordatenbank das schnelle und genaue Abrufen semantisch ähnlicher Datenpunkte, um die Anwendungsleistung zu steigern.
- Alternative zur Suche mit Schlüsselwörtern. Eine Vektordatenbank kann auch dazu beitragen, die Relevanz und Genauigkeit bei Abfragen unstrukturierter Daten zu verbessern, indem sie differenziertere und kontextsensitivere Suchergebnisse ermöglicht als herkömmliche Schlüsselwortabgleiche.
- Optimiert für hochdimensionale Daten. Die Möglichkeit, Datenpunkte über Hunderte oder Tausende von Dimensionen hinweg abzubilden, ermöglicht es Benutzern, hochgranulare Suchen durchzuführen, die sich auf bestimmte Merkmale und Attribute in einem Datensatz konzentrieren.
- Integration mit generativen KI-Modellen. Eine Vektordatenbank dient als externe Wissensbasis für GenAI-Anwendungen, die dazu beitragen können, KI-Halluzinationen zu reduzieren, die zu falschen Informationen führen.
- Vereinfachte Datenindexierung. Die Unterstützung spezialisierter Indexierungstechniken wie HNSW, PQ und LSH kann Benutzern die Erstellung von Indizes erleichtern.
- Integrierte Datenverwaltungs- und Sicherheitsfunktionen. Eine Vektordatenbank bietet Datenspeicherungs- und -verwaltungsfunktionen, die in alternativen Technologien wie Vektorsuchbibliotheken oder eigenständigen Vektorindizes nicht verfügbar sind.
Welche Nachteile haben Vektordatenbanken?
Im Folgenden werden einige der häufigsten Herausforderungen aufgeführt, mit denen Organisationen bei der Bereitstellung von Vektordatenbanken konfrontiert sind:
- Kosten. Speicher- und Rechenanforderungen können zu hohen Hardwarekosten führen, insbesondere wenn GPUs – Grafikprozessoren – anstelle herkömmlicher Prozessoren für die Ausführung von KI-Anwendungen benötigt werden.
- Komplexität der Bereitstellung. Die Einrichtung und Wartung von Vektordatenbanken kann für Datenverwaltungsteams, die nicht über die richtige Erfahrung und die richtigen Fähigkeiten verfügen, eine Herausforderung darstellen.
- Anforderungen an die Skalierbarkeit. Mit zunehmendem Datenvolumen und Vektordimensionen können die für eine skalierbare Such- und Datenabrufleistung erforderlichen Systemressourcen erheblich ansteigen, was die Implementierung einer Vektordatenbank kostspieliger und komplexer macht.
- Datenintegrität und -konsistenz. Die Gewährleistung einer hohen Datenqualität und -konsistenz über Vektoreinbettungen hinweg kann kompliziert sein.
- Abfragegenauigkeit vs. Leistung. Es ist notwendig, die Abfragegeschwindigkeit mit der Genauigkeit und Präzision der Vektorsuchergebnisse in Einklang zu bringen, was schwierig sein kann.
- Integration in bestehende Systeme. Die Anpassung bereits verwendeter Anwendungen an die Arbeit mit Vektordatenbanken erfordert möglicherweise erhebliche Aktualisierungen der Dateninfrastruktur und der Anwendungslogik.
- Versionierung. Die Verwaltung verschiedener Versionen von Vektoreinbettungen im Zuge der Weiterentwicklung von KI-Modellen oder Datensätzen ist keine triviale Aufgabe.
Erfahren Sie mehr über Datenbanken
-
![]()
Context Engineering: Kontext für die KI-Agenten schaffen
-
![]()
Semantic Kernel versus LangChain für die KI-Entwicklung
Von: Marius Sandbu
-
![]()
AWS re:Invent 2025: neue Prozessoren und Datenbank-Updates
Von: Prof. Dr. Jens-Henrik Söldner
-
![]()
So bereiten Sie Daten für Retrieval-Augmented Generation vor
Von: Marius Sandbu



