
DamienArt - stock.adobe.com
RAG-Architektur: Funktionsweise und Aufbau
RAG hat sich als effektive Methode zur Integration generativer KI etabliert. Sie kombiniert verschiedene technologische Bausteine, wobei jede Implementierung Kompromisse erfordert.

Retrieval-Augmented Generation (RAG) gilt als eine der vielversprechendsten Methoden, um generative KI in Unternehmen effektiv einzusetzen. Diese Architektur kombiniert klassische Informationssuche mit großen Sprachmodellen (LLMs), um präzisere und fundiertere Antworten zu generieren. Trotz ihrer Vorteile erfordert die Implementierung eine durchdachte Strategie, die verschiedene technologische Bausteine integriert und Kompromisse zwischen Geschwindigkeit, Genauigkeit und Kosten eingeht.
Was ist eine RAG-Architektur?
RAG verbindet generative KI mit einer Wissensdatenbank, um fundierte Antworten zu liefern und die Ergebnisse in der realen Welt nutzen zu können. Auch wenn sie Halluzinationen nicht verhindert, zielt die Methode darauf ab, relevante Antworten zu erhalten, die auf unternehmensinternen Daten oder Informationen aus einer verifizierten Wissensdatenbank beruhen. Vereinfacht gesagt, handelt es sich um eine Kombination aus generativer KI und einer Unternehmenssuchmaschine.
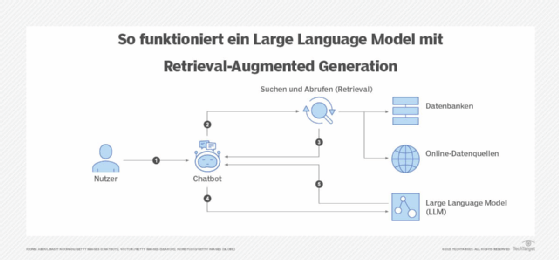
In groben Zügen ist der Prozess eines RAG-Systems einfach zu verstehen. Es beginnt damit, dass der Nutzer einen Prompt – eine Frage oder Anfrage – sendet. Dieser natürlichsprachige Prompt und die dazugehörige Anfrage werden vom Prozess mit dem Inhalt der Wissensdatenbank verglichen. Die Ergebnisse, die der Anfrage am nächsten kommen, werden nach Relevanz geordnet und dann an eine LLM gesendet, die die an den Benutzer zurückgesandte Antwort erstellt.
Unternehmen, die RAG implementiert haben, verstehen die Komplexität dieses Ansatzes. Dies beginnt bei der Integration verschiedener Elemente, die den RAG-Mechanismus antreiben. Diese Elemente sind eng mit dem Prozess verknüpft, der Daten von der Erfassung in einem Quellsystem bis zur Generierung einer Antwort durch ein Large Language Model transformiert.
Daten aufbereiten: Der Schlüssel zu effektiver RAG
Der erste Schritt besteht darin, die Dokumente zusammenzustellen, die man abfragen möchte. Die Qualität eines RAG-Systems steht und fällt mit den Eingangsdaten. Eine unstrukturierte, überladene oder fehlerhafte Datenbasis führt zu schlechten Ergebnissen. Unternehmen müssen daher gezielt relevante Dokumente auswählen und Strategien zur Aktualisierung der Daten definieren – entweder als Batch-Prozess oder in Echtzeit.
Ein LLM ist nicht de facto ein Werkzeug zur Datenaufbereitung. Es sollten Duplikate und Zwischenversionen von Dokumenten entfernt und Strategien zur Auswahl von aktuellen Artikeln oder Items angewendet werden. Diese Vorauswahl verhindert, dass das System mit potenziell unnötigen Informationen überlastet wird und vermeidet Leistungsprobleme.
Sobald die Dokumente ausgewählt sind, geht es darum, die Rohdaten (HTML-Seiten, PDF-Dokumente, Bilder, doc-Dateien) in ein verwertbares Format umzuwandeln, das heißt in Text und zugehörige Metadaten (ausgedrückt zum Beispiel in einer JSON-Datei). Diese Metadaten können sowohl die Struktur des Dokuments als auch seine Autoren, seine Herkunft, sein Erstellungsdatum und andere Informationen dokumentieren. Diese formatierten Daten werden dann in Token und anschließend in Vektoren umgewandelt.
Die wichtigsten Schritte der Datenaufbereitung im Kurzüberblick:
- Deduplizierung: Entfernen redundanter oder veralteter Dokumente.
- Formatierung: Konvertieren von HTML, PDF, DOCX und anderen Formaten in ein strukturiertes Format (zum Beispiel JSON).
- Metadaten-Erfassung: Speicherung von Quellenangaben, Erstellungsdaten und Autorinformationen.
Verlage haben beispielsweise schnell erkannt, dass es bei großen Dokumentenmengen und langen Texten wenig effizient ist, das gesamte Dokument zu vektorisieren.
Chunking und Chunking-Strategien
Um die Verarbeitung großer Textmengen effizient zu gestalten, sollte eine Chunking-Strategie eingeführt werden. Dieser Schritt unterteilt ein Dokument in kurze Abschnitte (Chunks). Dies erleichtert die Identifizierung und das Abrufen der relevantesten Informationen während des Suchprozesses.
Hier müssen zwei Überlegungen berücksichtigt werden: die Größe der Chunks und die Art und Weise, wie sie gewonnen werden.
Die Größe eines Chunks wird häufig in der Anzahl der Zeichen oder Token ausgedrückt. Eine größere Anzahl von Chunks verbessert die Genauigkeit der Ergebnisse, aber die Vervielfachung von Vektoren erhöht die Menge an Ressourcen und die Zeit, die für die Verarbeitung der Chunks benötigt wird.
Um einen Text in Chunks zu unterteilen, gibt es mehrere Methoden.
Die erste besteht darin, nach Fragmenten mit fester Größe zu zerlegen: nach Zeichen, Wörtern oder Token. Diese Methode ist einfach, was sie zu einer beliebten Wahl für die Anfangsphasen der Datenverarbeitung macht, in denen die Daten schnell durchsucht werden müssen.
Ein zweiter Ansatz ist die semantische Aufteilung. Hier erfolgt eine natürliche Aufteilung: nach Satz, Abschnitt (zum Beispiel durch einen HTML-Header definiert), Thema oder Absatz. Diese Methode ist komplexer zu implementieren, aber auch genauer. Sie hängt oft von einem rekursiven Ansatz ab, da hier logische Trennzeichen (Leerzeichen, Komma oder Punkt) verwendet werden.
Der dritte Ansatz besteht aus einer Kombination der beiden vorherigen. Beim Hybrid-Chunking wird eine erste feste Trennung mit einer semantischen Methode kombiniert, wenn es darum geht, eine sehr präzise Antwort zu erhalten.
Zusätzlich zu diesen Techniken ist es möglich, die Fragmente miteinander zu verketten, wobei zu berücksichtigen ist, dass sich ein Teil des Inhalts der Chunks überschneiden kann. Die Überlappung stellt sicher, dass es immer einen gewissen Spielraum zwischen den Segmenten gibt, was die Chancen erhöht, wichtige Informationen zu erfassen, selbst wenn sie gemäß der ursprünglichen Ausschnittstrategie aufgeteilt werden. Der Nachteil dieser Methode ist, dass sie Redundanz erzeugt.
Strategien für Chunking
- Feste Länge: Unterteilung nach Zeichen-, Wort- oder Token-Anzahl.
- Semantische Unterteilung: Zerlegung nach Sätzen, Absätzen oder thematischen Abschnitten.
- Hybridansatz: Kombination beider Methoden für höhere Präzision.
Ein gängiger Ansatz ist die Verwendung von Fragmenten mit 100–200 Wörtern und einer Überlappung von 20–25 Prozent, um Kontextverluste zu vermeiden. Diese Aufteilung wird häufig mithilfe von Python-Bibliotheken, darunter SpaCy oder NTLK, oder mit den Text-Splitters-Tools des LangChain-Frameworks vorgenommen.
Der richtige Ansatz hängt in der Regel von der von den Nutzern geforderten Genauigkeit ab. Beispielsweise scheint eine semantische Aufteilung angemessener, wenn es darum geht, eine bestimmte Information zu finden, zum Beispiel den Artikel eines Gesetzestextes.
Die Größe der Chunks muss den Möglichkeiten des Embedding-Modells entsprechen. Genau das ist der Hauptgrund für die Notwendigkeit des Chunkings. Dies ermöglicht es, unterhalb des Limits für die Token-Eingabe in das Embedding-Modell zu bleiben. Beispielsweise beträgt die maximale Länge des Eingabetexts für die Azure OpenAI-Vorlage text-embedding-ada-002 8.191 Token. Da ein Token bei den gängigen OpenAI-Vorlagen im Durchschnitt etwa vier Zeichen entspricht, entspricht diese Höchstgrenze etwa 6000 Wörtern.
Vektorisierung und Embedding-Vorlagen
Eine Embedding-Vorlage ist dafür zuständig, Chunks oder Dokumente in Vektoren umzuwandeln. Diese Vektoren werden in einer Datenbank gespeichert.
Auch hier gibt es verschiedene Arten von Embedding-Modellen: dichte, sparsame (sparse) und hybride Modelle. Dichte Modelle erzeugen in der Regel Vektoren mit fester Größe, die in x Dimensionen ausgedrückt werden. Sparse Modelle erzeugen Vektoren, deren Größe von der Länge des Eingabetextes abhängt. Das Hybridmodell kombiniert beide Ansätze, um kurze Auszüge oder Kommentare zu vektorisieren (Splade, ColBERT, IBM sparse-embedding-30M).
Die Wahl der Anzahl der Dimensionen bestimmt die Genauigkeit und die Geschwindigkeit der Ergebnisse. Ein Vektor mit vielen Dimensionen erfasst mehr Kontext und Nuancen, benötigt aber unter Umständen mehr Ressourcen, um ihn zu erstellen und abzurufen. Ein Vektor mit weniger Dimensionen ist weniger umfangreich, dafür aber schneller zu durchsuchen.
Die Wahl des Embedding-Modells hängt auch von der Vektorendatenbank, von dem großen Sprachmodell, mit dem es verknüpft wird, und von der Aufgabe ab, die es zu erfüllen gilt. Benchmarks wie das MTEB-Ranking sind dabei eine große Hilfe. Manchmal ist es möglich, ein Embedding-Modell zu verwenden, das nicht aus derselben LLM-Sammlung stammt, aber es ist notwendig, dasselbe Modell zu verwenden, um die Dokumentationsbasis und die Nutzerfragen zu vektorisieren.
Beachten Sie, dass es manchmal sinnvoll ist, die Emebbing-Vorlage zu verfeinern, wenn sie nicht genügend Wissen über die Sprache enthält, die mit einem bestimmten Fachgebiet (beispielsweise Onkologiemedizin oder Systemtechnik) verbunden ist.
Die Vektordatenbank und ihr Retriever-Algorithmus
Die Vektordatenbank speichert nicht nur Vektoren, sie enthält in der Regel einen semantischen Suchalgorithmus, der auf der Technik des Approximate Nearest Neighbor (ANN) basiert, um die Informationen, die der Frage entsprechen, zu indizieren und wiederzufinden. Die meisten Anbieter haben den Algorithmus Hierarchical Navigable Small Worlds (HNSW) implementiert. Microsoft ist ebenfalls einflussreich mit DiskANN, einem Open-Source-Algorithmus, der entwickelt wurde, um bei großen Vektormengen ein ideales Verhältnis von Leistung und Kosten zu erreichen, was allerdings auf Kosten der Genauigkeit geht. Google hat sich für die Entwicklung eines proprietären Modells entschieden, ScANN, das ebenfalls für große Datenmengen ausgelegt ist. Der Suchprozess besteht darin, die Dimensionen des Vektorgraphen auf ANN basierend zu durchsuchen, und hängt von einer Berechnung der Kosinus- oder Euklidischen Distanz ab.
Approximate Nearest Neighbor (ANN)
Dieser Algorithmus sucht nach dem Vektor in einer Datenbank, der dem Abfragevektor am nächsten liegt, basierend auf Ähnlichkeitsmaßen wie der Kosinus-Ähnlichkeit oder der euklidischen Distanz. Der ANN-Algorithmus ist effizienter als der exakte k-Nearest-Neighbor (kNN)-Algorithmus, da er schneller arbeitet, jedoch weniger genau ist.
Funktionsweise des ANN-Algorithmus
- Indexierung: Vektoren werden mithilfe von Techniken wie Hashing (zum Beispiel Locality-Sensitive Hashing, LSH), Quantisierung oder graphbasierten Methoden (zum Beispiel Hierarchical Navigable Small World, HNSW) indiziert.
- Abfrage: Der Abfragevektor wird mit den indizierten Vektoren verglichen, um die nächsten Nachbarn zu finden.
- Ähnlichkeitsmaße: Die Kosinus-Ähnlichkeit misst die Richtungsähnlichkeit zwischen Vektoren, während die euklidische Distanz den Abstand zwischen ihnen misst.
Der ANN-Algorithmus ermöglicht es, in großen Datensätzen schnell ähnliche Vektoren zu finden, was in Anwendungen wie semantischer Suche oder Empfehlungssystemen nützlich ist.
Da sich die meisten Datenbanken auf den ANN-Algorithmus stützen, wird das System mehrere Vektoren zurückgeben, die potenziell mit der Antwort übereinstimmen. Es ist möglich, die Anzahl der Ergebnisse zu begrenzen (top_k cutoff). Dies ist sogar notwendig, da die Anfrage des Nutzers und die Informationen, die die Antwort bilden, in das Kontextfenster der LLM passen sollen. Wenn die Datenbank jedoch viele Vektoren enthält, kann die Genauigkeit darunter leiden oder das gesuchte Ergebnis liegt jenseits der vorgegebenen Grenze.
Hybride Suche und Reranking
Die Kombination von klassischen Suchmodellen wie BM25 mit HNSW-Retrievern bietet ein gutes Verhältnis von Kosten und Leistung, ist jedoch auf eine begrenzte Anzahl von Ergebnissen beschränkt. Zudem unterstützen nicht alle Vektordatenbanken die sogenannte Hybridsuche, bei der BM25 und HNSW kombiniert werden.
Ein Reranking-Modell kann in solchen Fällen helfen, relevantere Inhalte für die Antwort zu identifizieren. Dabei wird zunächst die Grenze der vom Retriever zurückgegebenen Ergebnisse erhöht. Anschließend ordnet der Reranker die Textabschnitte (Chunks) basierend auf ihrer Relevanz zur Anfrage neu an. Zu den gängigen Reranking-Optionen gehören Cohere Rerank, BGE, Janus AI und Elastic Rerank. Diese Modelle können jedoch die Antwortlatenz erhöhen und erfordern gegebenenfalls ein erneutes Training, insbesondere wenn das Dokumentenvokabular sehr spezifisch ist. Dennoch wird Reranking oft als nützlich angesehen, da die Relevanz-Scores wertvolle Daten liefern, um die Leistung eines RAG-Systems zu überwachen und zu optimieren.
Unabhängig davon, ob ein Reranking verwendet wird oder nicht, müssen die ausgewählten Antworten schließlich an das LLM (Large Language Model) weitergeleitet werden. Hierbei spielen verschiedene Faktoren eine Rolle: Die Größe des Kontextfensters des LLM, seine Geschwindigkeit bei der Verarbeitung von Anfragen sowie seine Fähigkeit, faktisch korrekte Antworten zu liefern – auch ohne direkten Zugriff auf Dokumente. Anbieter wie Google DeepMind, OpenAI, Mistral AI, Meta und Anthropic haben ihre LLMs speziell für diesen Anwendungsfall trainiert und optimiert.
Die Hybridsuche und das Reranking stellen somit wichtige Bausteine dar, um die Effizienz und Genauigkeit von RAG-Systemen zu verbessern. Gleichzeitig erfordern sie eine sorgfältige Abwägung zwischen Leistung, Kosten und Latenz sowie eine Anpassung an spezifische Anforderungen des jeweiligen Unternehmenskontexts.
Bewerten und beobachten
Zusätzlich zum Reranking kann ein LLM als Bewerter (LLM-as-a-judge) eingesetzt werden, um die Ergebnisse zu evaluieren und potenzielle Fehler des antwortgenerierenden LLMs zu identifizieren. Einige APIs nutzen regelbasierte Systeme, um schädliche Inhalte zu blockieren oder den Zugriff auf vertrauliche Dokumente für bestimmte Benutzer zu beschränken.
Zur Verfeinerung der RAG-Architektur können auch Feedback-Frameworks implementiert werden. Hierbei werden Benutzer eingeladen, die Ergebnisse zu bewerten, um Stärken und Schwächen des RAG-Systems zu identifizieren.
Schließlich ist die Beobachtbarkeit (Observability) jeder Komponente entscheidend, um Probleme bezüglich Kosten, Sicherheit und Leistung zu vermeiden. Dies ermöglicht eine kontinuierliche Optimierung und Anpassung des Systems an sich ändernde Anforderungen.
Kernpunkte der Bewertung und Überwachung:
- LLM-as-a-judge zur Qualitätskontrolle
- Regelbasierte Sicherheitsmechanismen
- Benutzerfeedback zur Systemverbesserung
- Umfassende Beobachtbarkeit aller Komponenten
Diese Maßnahmen tragen dazu bei, die Zuverlässigkeit, Sicherheit und Effizienz von RAG-Systemen in Unternehmensumgebungen zu gewährleisten.





