
putilov_denis - stock.adobe.com
Die 5 besten RAG-Tools und -Frameworks
Die Landschaft der RAG-Tools und -Frameworks entwickelt sich ständig weiter, wodurch es einfacher wird, generative KI-Dienste mit Unternehmensdaten zu kombinieren.

Unternehmen möchten häufig generative KI mit ihren eigenen Daten kombinieren, um Inhalte zusammenzufassen, Informationen zu synthetisieren oder Fragen zu beantworten.
KI-Chatbots haben nicht automatisch Zugriff auf Unternehmensdaten. Daher greifen Unternehmen, die bei der Verwendung generativer KI mit ihren unstrukturierten Daten arbeiten möchten, häufig auf Retrieval-Augmented Generation (RAG) zurück. RAG ist ein KI-Framework, das es großen Sprachmodellen (Large Language Model, LLM) ermöglicht, auf externe Wissensdatenbanken zuzugreifen, wodurch sie zu einem wichtigen Bestandteil bei der Erstellung generativer KI-Dienste werden, die auf Unternehmensinhalte zugreifen.
Obwohl viele Unternehmen RAG zur Verbesserung ihrer generativen KI-Dienste einsetzen möchten, kann es schwierig sein, das beste RAG-Tool oder -Framework für die Entwicklung und Verwaltung zu finden. Das Verständnis der fünf wichtigsten Kandidaten – PostgreSQL mit pgvector, Azure KI-Suche, GraphRAG, LightRAG und txtAI – kann Unternehmen dabei unterstützen, die richtigen Komponenten zur Unterstützung von RAG-Workflows in Produktionsumgebungen auszuwählen.
Was sind die Hauptkomponenten von RAG?
RAG macht unstrukturierte Daten durchsuchbar, indem es eine Suchmaschine verwendet, die die relevantesten proprietären Inhalte abruft und diese Informationen an ein LLM weiterleitet, das die Ausgabe generiert.
Die RAG-Architektur kann je nach dem von einem Unternehmen verwendeten Framework oder den verwendeten Komponenten variieren. Zu den wichtigsten Bausteinen gehören jedoch in der Regel Einbettung und Vektorisierung, Daten-Chunking, Suche und Ähnlichkeitsabgleich sowie die Generierung von Antworten.
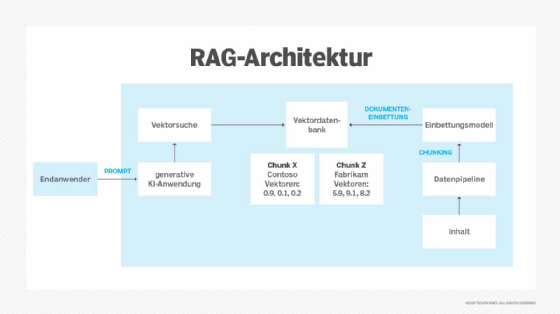
1. Einbettung und Vektorisierung
Das RAG-System verarbeitet alle unstrukturierten Daten – wie Word-Dateien, Excel-Tabellen und Textdokumente – über ein Einbettungsmodell, das Daten in Vektoreinbettungen umwandelt. Viele RAG-Frameworks und Vektordatenbanken verfügen über integrierte Funktionen für diese Vektorisierung. Diese Vektoren werden dann in einem Vektorspeicher wie Azure KI-Suche oder PostgreSQL mit pgvector gespeichert.
2. Daten-Chunking
Das RAG-System unterteilt Daten in der Regel in kleinere Segmente. Beispielsweise kann eine Wiki-Seite in Unterthemen unterteilt werden, die jeweils als eigener Vektorsatz dargestellt werden. Dies führt zu präziseren Suchergebnissen als die Einbettung des gesamten Dokuments als einzelner Vektor.
3. Suche und Ähnlichkeitsabgleich
Der Prompt wird in einen Vektor umgewandelt, wenn ein Benutzer eine Abfrage sendet. Anschließend wird eine Ähnlichkeitssuche im Vektorspeicher durchgeführt, um die relevantesten Inhalte im Zusammenhang mit dem Prompt zu finden.
4. Generierung einer Antwort
Die relevantesten Datenblöcke und die ursprüngliche Eingabe werden an das LLM weitergeleitet, um eine Antwort für den Benutzer zu generieren.
5 RAG-Tools und -Frameworks, die in Betracht gezogen werden sollten
Von Vektorspeichern bis hin zu Wissensgraphen – RAG-Tools können Unternehmen dabei unterstützen, auf die Frameworks und Prozesse zuzugreifen, die sie für den Aufbau erfolgreicher RAG-Systeme benötigen. Diese fünf Optionen bieten eine Auswahl, die Teams in Betracht ziehen sollten.
Die Tools sind in keiner bestimmten Reihenfolge aufgeführt.
1. PostgreSQL mit pgvector
pgvector ist eine Open-Source-Erweiterung für PostgreSQL, mit der Benutzer Vektoreinbettungen direkt in einer Datenbankspalte speichern und abfragen können. Dies ist besonders nützlich, wenn der gewünschte Inhalt bereits in PostgreSQL vorhanden ist, sodass Benutzer eine semantische Suche hinzufügen können, ohne eine separate Vektordatenbank einführen zu müssen.
Die Stärke von pgvector liegt in seiner Einfachheit und Zugänglichkeit. Es ist kostenlos und Open Source, und wenn ein Benutzer bereits mit PostgreSQL vertraut ist, muss er keine neuen Tools erlernen. Außerdem wird es von vielen generativen KI-Frameworks wie LlamaIndex, Semantic Kernel und LangChain unterstützt, was die Integration erleichtern kann.
2. Azure KI-Suche
Azure KI-Suche ist ein PaaS-Angebot (Platform as a Service) von Microsoft Azure, das Suchfunktionen bereitstellt, die auf Suchindizes basieren und nicht wie bei PostgreSQL mit pgvector auf relationalen Tabellen. Es ist für die Volltext- und semantische Suche konzipiert.
Der Dienst ist tief in das Azure-Ökosystem integriert und bietet native Unterstützung für die Einbettung von Modellen aus Azure OpenAI. Er kann Inhalte automatisch vektorisieren und vereinfacht so den Aufbau von RAG-Systemen. Für Teams, die bereits mit Azure arbeiten, bietet KI-Suche ein skalierbares und verwaltetes Tool zum Hinzufügen der Vektorsuche, ohne dass die Infrastruktur oder separate Komponenten verwaltet werden müssen.
3. GraphRAG
GraphRAG ist ein RAG-Framework von Microsoft, das Wissensgraphen in den Abrufprozess einbezieht. Herkömmliche RAG-Systeme rufen semantisch ähnliche Informationsblöcke ab, können jedoch verwandte Informationen übersehen, die nicht in diesen Blöcken enthalten sind.
Wissensgraphen erweitern den Suchkontext mithilfe benachbarter Knoten und Beziehungen, wodurch die Relevanz verbessert werden kann, ohne das Modell mit einem zu langen Kontext zu überfordern. Um den Unterschied zwischen herkömmlichen RAG und Wissensgraphen zu veranschaulichen, nehmen wir eine Frage wie „Welche Unternehmen haben in den letzten zwei Jahren Firmen übernommen, die im Bereich KI tätig sind?“ – „welche“ ist eine zusammengesetzte Abfrage, die für ein herkömmliches RAG-System schwer zu beantworten ist, da der Inhalt in verschiedene Datenblöcke unterteilt sein kann.
Mit einem Wissensgraphen ist es viel einfacher, die Beziehungen zwischen verschiedenen Entitäten zu verstehen und diese zusammengesetzten Abfragen zu beantworten. GraphRAG kombiniert die Geschwindigkeit herkömmlicher RAGs mit der Genauigkeit von Wissensgraphen und ist damit ein hilfreiches Framework für die Entwicklung komplexer RAG-Systeme.
4. LightRAG
LightRAG ist wie GraphRAG ein Framework, das Wissensgraphen und hybride Suchfunktionen kombiniert, wodurch es sich hervorragend zum Verstehen der Beziehungen zwischen verschiedenen Entitäten und zum Beantworten kompositorischer Fragen eignet.
LightRAG ist Open Source und unterstützt die multimodale Datenverarbeitung durch die Integration von MinerU, einem Open Source Tool für die Dokumentenanalyse. Dies ermöglicht RAG-Funktionen und die Dokumentenanalyse über verschiedene Formate wie Bilder, Office-Dokumente, PDFs und Tabellen hinweg. Es verfügt außerdem über eine separate Komponente namens VideoRAG zur Verarbeitung von Videoinhalten.
Ein weiterer Vorteil der Verwendung von LightRAG besteht darin, dass es im Vergleich zu GraphRAG eine einfachere Aktualisierung von Inhalten unterstützt, bei dem Benutzer den gesamten Graphen neu erstellen müssen, was viel Zeit in Anspruch nimmt – insbesondere, wenn es viele Inhalte gibt.
5. TxtAI
TxtAI unterscheidet sich geringfügig von den anderen oben aufgeführten RAG-Tools und -Frameworks. Während beispielsweise PostgreSQL mit pgvector und Azure KI-Suche reine Vektorspeicher sind, handelt es sich bei TxtAI eher um ein vollständiges Framework, das sowohl eine Vektordatenbank als auch ein Framework für die semantische Suche bereitstellen soll. Das Open Source Tool bietet außerdem Unterstützung für Wissensgraphen, Pipelines und die Möglichkeit, benutzerdefinierte KI-Agenten zu erstellen.
Es kann zwar eher als Alternative zu LangChain angesehen werden, aber im Gegensatz zu LangChain bietet TxtAI auch eine native Vektordatenbank.
So wählen Sie das richtige RAG-Tool
Beim Aufbau eines benutzerdefinierten generativen KI-Dienstes, der auf Unternehmensdaten zugreifen und diese nutzen kann, müssen Unternehmen zunächst ihren Anwendungsfall definieren, bevor sie sich für ein Tool oder Framework entscheiden. Die Architektur des RAG-Systems und die Anforderungen des Anwendungsfalls bestimmen, welches Tool am besten geeignet ist.
Für eine E-Commerce-Website, die einen Großteil ihrer Inhalte in einem relationalen Datenbankmanagementsystem (RDBMS) wie PostgreSQL speichert, ist beispielsweise pgvector das optimale RAG-Tool.
Ein Framework wie GraphRAG oder LightRAG, das mit Wissensgraphen arbeitet, ist die bessere Wahl für Anwendungsfälle, die ein tiefes Verständnis der Beziehungen zwischen verschiedenen Datenblöcken erfordern, um komplexere Fragen zu beantworten.
Und wenn ein Unternehmen einfach nur nach einer optimalen RAG-Leistung bei der Verwendung von Geschäftsdaten sucht, ist ein traditioneller Suchdienst wie Azure KI-Suche oft die beste Wahl.
Dies sind nur einige der verfügbaren Frameworks – Cloud-Anbieter haben viele verschiedene Such- und Vektorspeicher. Es gibt auch zahlreiche Open-Source-Alternativen, die in Betracht gezogen werden können.




