
Framestock - stock.adobe.com
Die Grundlagen der Observability von LLMs verstehen
LLM-Observability umfasst spezielles Monitoring zur Verbesserung der Leistung, Fehlerbehebung und Kostenverwaltung. Lernen Sie, die fünf Säulen der LLM-Observability zu nutzen.

Observability, also die Beobachtbarkeit, ist entscheidend für das Verständnis und die Verbesserung der Leistung in Anwendungen mit großen Sprachmodellen (Large Language Model, LLM) sowie für eine effiziente Fehlerbehebung.
KI-Implementierungen sind anfällig für Modellabweichungen und können Antworten generieren, deren Genauigkeit allmählich abnimmt. Um eine erfolgreiche Einführung zu erreichen, sind eine konsistente datengesteuerte Wartung und Feinabstimmung erforderlich.
Gleichzeitig können IT-Betriebsabläufe aufgrund von Ressourcenengpässen, ineffizienten Datenpipelines und komplexen Fehlerbehebungsverfahren vor Herausforderungen stehen. Die Verfolgung der Qualität von Modellantworten, die frühzeitige Erkennung von Halluzinationen und die Verwaltung der Token-Kosten sind wichtige operative Ziele. Ohne ein skalierbares Observability Framework für kontinuierliche Verbesserungen sind diese jedoch nicht zu erreichen.
Für Unternehmen mit umfangreichen Ressourcen kann ein maßgeschneidertes Observability Tool für große Sprachmodelle (LLM) maßgeschneiderte Bewertungen und Integrationen bieten. Für kleinere Startups oder Unternehmen ohne umfangreiche Infrastruktur können Standard-Tools für die Anfangsphase ausreichend sein. Allerdings fehlt diesen möglicherweise die für die Skalierung oder das langfristige Wachstum erforderliche Tiefe.
Die 5 Säulen der LLM-Observability
LLM-Observability bietet einen spezialisierten Ansatz, der Leistungskennzahlen, datengesteuerte interne Analysen und allgemeine Modelltransparenz umfasst, um hochfunktionale KI-Implementierungen aufrechtzuerhalten. Unternehmen setzen LLM-Observability ein, um wichtige Herausforderungen im Zusammenhang mit Debugging, Ausgabequalität, Kostenüberschreitungen und Modellleistung im Laufe der Zeit zu bewältigen.
Bei der herkömmlichen Überwachung werden Metriken auf Systemebene wie CPU-Auslastung, Speicher und Anzahl der Anfragen erfasst, damit IT-Teams den Systemzustand überwachen, Probleme proaktiv identifizieren und eine optimale Ressourcennutzung sicherstellen können.
LLM-Observability erweitert diese Funktionen um semantische Überprüfungen der Modellausgaben, die Analyse von Token-Nutzungsmustern und die Ausrichtung auf Geschäftsziele. Die fünf Säulen der LLM-Observability stellen sicher, dass die Dateneingaben und -ausgaben genau sind und verantwortungsbewusst mit Echtzeitbewertungen behandelt werden, die mit der Reife der KI-Modelle skaliert werden.
1. Bewertung
Die erste Säule basiert auf klaren Bewertungsstandards. Dazu gehören technische, semantische und benutzerbasierte Analysen sowie die Verfolgung der Kosteneffizienz und die lückenlose Rückverfolgbarkeit.
Auf technischer Seite müssen Administratoren wissen, warum ein KI-Agent eine Spirale durchlaufen hat, die Modellantworten sich verschlechtert haben oder die Kosten gestiegen sind. Die Erklärung, warum eine Ausgabe erfolgreich ist oder fehlschlägt, ist leichter zu erreichen, wenn Modelle und Bewertungen transparent sind.
Während herkömmliche IT-Logging-Frameworks IT-Verantwortlichkeit bieten, konzentrieren sich LLM Observability Frameworks auf modellspezifische Parameter wie Prompt-Qualität, Modellantworten, Eingabe-/Ausgabe-Token-Zählungen und Anforderungs-Tracing. Diese liefern wichtige Einblicke in die Funktionalität.
Beispielsweise verwenden Administratoren semantische Observability, um die Genauigkeit, Relevanz, Konsistenz und Integrität von Antworten zu bewerten, während sie das Framework nutzen, um die Qualität der Benutzererfahrung und die Effektivität der Anwendung in der Praxis zu beurteilen. IT-Teams können die Kosten durch den Einsatz statistischer Performance Baselines kontrollieren und so sicherstellen, dass die Modelle im Rahmen des Budgets bleiben und die Ziele der KI-Bereitstellung erreicht werden.
2. Traces und Spans
Die zweite Säule konzentriert sich auf die Entwicklung von Systemanfragen unter Verwendung von Traces und Spans. Traces erfassen den Weg einer Anfrage, während sie ein verteiltes System durchläuft. Ein Trace beschreibt den gesamten Verlauf einer Anfrage vom Start bis zum Abschluss und liefert die gewünschte Antwort. Spans bilden die Grundlage von Traces, wobei jeder Span eine Operationseinheit innerhalb dieses Verlaufs definiert. Datenbankabfragen, API-Aufrufe oder Funktionsausführungen können alle als Spans isoliert werden, um Ressourcenengpässe zu finden und die Geschwindigkeit einer Dienst- oder Funktionsantwort zu messen.
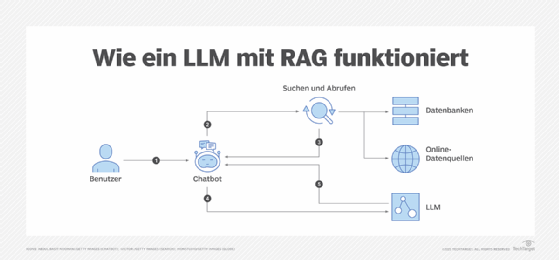
3. Retrieval-Augmented Generation (RAG)
IT-Teams stützen sich auf die dritte Säule, Retrieval-Augmented Generation (RAG), um Informationen auf der Grundlage externen Wissens zu verifizieren und die Überwachung und Bewertung der Leistung eines KI-Modells zu verbessern. LLM-Anwendungen bestehen aus mehreren Relaiskomponenten, darunter Abrufsysteme, Prompt-Vorlagen und externe APIs. RAG bietet eine durchgängige Rückverfolgbarkeit, um die Lieferpipelines zu verbessern und Datenkonformität und Data Governance zu gewährleisten.
4. Feinabstimmung
Administratoren und Ingenieure nutzen die vierte Säule, die Feinabstimmung, um eine LLM-Instanz mithilfe spezifischer Datensätze anzupassen, die die Gesamtleistung und die Aufgabenausführung verbessern. Sobald LLM-Observability eingerichtet ist, können IT-Teams die Auswirkungen der Feinabstimmung auf die Modellleistung überwachen und Bereiche identifizieren, in denen weitere Anpassungen erforderlich sind.
5. Prompt Engineering
Prompt Engineering stellt die fünfte Säule dar. Dabei werden Methoden, Techniken und bewährte Verfahren zur Entwicklung von LLM-Prompts angewendet. Ein Prompt Engineer entwirft beispielsweise das Design und die Zusammensetzung der Prompts und entwickelt dann wichtige Interaktionen mit dem LLM. Der Prozess erfordert viel Zeit für API-Aufrufe, das Testen von Funktionen, die Durchführung von Sicherheitsüberprüfungen und das klare Verständnis, wie LLMs auf bestimmte Abfragen reagieren.
Wichtige Merkmale effektiver LLM Observability Tools
Es stehen mehrere LLM Observability Tools zur Verfügung, um unerwartetes Modellverhalten zu erfassen, Einblick in den Token-Verbrauch zu gewähren und ineffiziente Prompts und unnötige Modellaufrufe zu identifizieren. Dazu gehören Open-Source-Optionen sowie proprietäre und benutzerdefinierte LLM Observability Tools auf Unternehmensebene, die gemeinsame Merkmale und Funktionen bieten.
Leistungsüberwachung
Die Leistungsüberwachung eines LLMs ist entscheidend für die Visualisierung von Metriken, die Erstellung einheitlicher Dashboards und die Einrichtung von Warnmeldungen zur Verfolgung der Gesamtfunktionalität. Administratoren und IT-Teams können sich einen umfassenden Überblick über die Modellinfrastruktur verschaffen, indem sie Systemmetriken überwachen, die Latenzen, Anfragedurchsatz, Fehlerraten und die gesamte Ressourcennutzung anzeigen. Zu den nützlichen Tools, die eine Dashboard-Steuerung der Ressourcen bieten, gehören Prometheus, Grafana und Datadog.
Fehlerbehebung
Die Schwierigkeit bei der Fehlerbehebung in LLM-Anwendungen liegt in der Komplexität der Aufgabe und der Vielzahl von Variablen, die bei der RAG-Pipeline-Analyse und den fortgeschrittenen LLM-Schlussfolgerungsketten eine Rolle spielen. Wenn Fehler auftreten, können Analysten und Ingenieure Debugging Tools in verschiedenen Bereichen einsetzen – nicht nur, um Leistungsengpässe zu identifizieren und die Schlussfolgerungsmuster des Modells zu verstehen, sondern auch, um Prompts zu optimieren, Datenschutzmaßnahmen einzurichten und Ursachenanalysen für Verlangsamungen durchzuführen. Tools wie OpenLLMetry sind speziell darauf ausgerichtet, Administratoren dabei zu unterstützen, den gesamten Lebenszyklus einer Anfrage zu überblicken und die Instrumentierung zu automatisieren, um die Überwachung zu vereinfachen.
Fehlerverfolgung
Die Fehlerverfolgung ist ein weiteres unverzichtbares Element in LLM Observability Frameworks. Entwickler nutzen die Fehlerverfolgung, um LLM-Anwendungen zu überwachen, Fehler zu beheben und zu optimieren. IT-Teams benötigen umfassende Observability-Funktionen, insbesondere in Bezug auf Prompt-Stacks, Ein- und Ausgänge, RAG-Ketten, Modellleistung und Regressionen.
Sichtbarkeit
Administratoren können die Ursache eines Problems mithilfe von Identifizierung, Protokollierung und Fehlermanagement genau lokalisieren, um Muster und Anomalien zu erkennen. Die Überwachung von Metriken zu Fehlerraten ist zwar wichtig, aber auch die Transparenz der Trace-Ausführung ist eine Voraussetzung. Es ist entscheidend, dass ein LLM Observability Framework sowohl die Fehlerverfolgung als auch die Ablaufverfolgung bewältigen kann. Langfuse, LangSmith, Arize Phoenix und Helicone sind einige Beispiele für umfassende Tools.
Bewertungsdaten und Benchmarks
LLMs können eine unendliche Anzahl von Antwortvarianten erzeugen und unbeabsichtigt Verzerrungen hervorrufen. Maßgeschneiderte und handelsübliche Observability Tools bieten Benchmarks für Verzerrungen, um die Plausibilität zu bestimmen und sachlich korrekte Antworten sicherzustellen.
Während manuelle Bewertungen in großem Maßstab ineffizient sein können, kann die Analyse durch Fachexperten subtile Indikatoren der Modellausgabe bewerten, darunter Tonfall, kontextuelle Angemessenheit und Einhaltung von Markenstandards. Observability Tools können detaillierte Bewertungsdaten liefern, um die Leistung von LLM-Modellen auf der Grundlage von Endbenutzereingaben im Vergleich zu Trainingsdaten zu bestimmen. Arize, Comet und Giskard bieten jeweils spezifische Funktionen für das Benchmarking von Verzerrungen in LLMs.
Praktische Ergebnisse mit LLM-Observability erzielen
Wenn Unternehmen die Einführung und den Einsatz von LLMs in Betracht ziehen, sollten sie die Implementierung von LLM-Observability-Pipelines auf der Grundlage klarer Geschäftsregeln, Akzeptanzkriterien und domänenspezifischer Benchmarks in Betracht ziehen. Sobald diese vorhanden sind, können Ingenieure ihre LLMs anhand vorab festgelegter Standards testen, um zu ermitteln, wie gut ein Modell im Vergleich zu früheren Benchmarks und Standarddatensätzen abschneidet.
In einigen Fällen können Administratoren die Fähigkeit einer KI-Bereitstellung, Benchmarks zu erfüllen, bewerten, indem sie ein einfacheres, fokussierteres Modell einsetzen, um die Ausgabe des primären LLM zu bewerten. Dies wird als LLM-as-a-Judge-Ansatz bezeichnet.
Letztendlich riskieren Unternehmen ohne spezielle LLM Observability Frameworks operative blinde Flecken, die oft zu Unvorhersehbarkeit des Modells, versteckten Qualitätsproblemen und einem Vertrauensverlust in die KI-Leistung führen.







