
Getty Images
Synthetische oder reale Daten für Predictive Analytics nutzen?
Synthetische Daten erlauben die Simulation seltener Ereignisse. Reale Daten hingegen bewahren die vielfältigen Muster der Wirklichkeit, die zur Modellüberprüfung benötigt werden.

Dateningenieure stehen vor einem Paradoxon: Der Aufbau effektiver KI-Modelle erfordert große Mengen an empirischen Daten, aber der Zugang zu realen Informationen wird immer mehr eingeschränkt. Verantwortlich dafür sind vor allem Bestimmungen zu Datenschutz, Sicherheit und Regularien.
Einen Ausweg bieten synthetische Daten. Synthetische Daten werden künstlich erstellt und entstammen nicht realen Ereignissen. Vereinfacht gesagt wird dabei eine künstliche Repräsentation der Originaldaten generiert, die keinerlei Rückschlüsse mehr auf Personen erlaubt.
Ein Machine-Learning-Algorithmus läuft beispielsweise über die Kundendaten, analysiert deren Aufbau und lernt durch Training die statistischen Informationen und statistischen Strukturen der Originaldaten. Mit diesem Wissen erzeugt der Algorithmus neue künstliche Daten. Diese spiegeln den gesamten Datensatz mit seinen statistischen Informationen und Strukturen wieder.
Synthetische Daten sind in datenschutzkritischen, sensiblen Branchen oder bei Vorliegen limitierter realer Datensätze unverzichtbar. Vor allem Datenwissenschaftler und KI-Ingenieure profitieren davon. Für sie sind künstlich erzeugte Daten ein Werkzeug, mit dem sich die Leistung und Zuverlässigkeit von Modellen und Datenpipelines erheblich verbessern lässt.
Allerdings birgt die Verwendung solcher Datensätze auch Fallen und Risiken. Und auch wenn die Daten nicht real sind – so stellen sich dennoch Fragen zu Ethik, Governance und Datenqualität.
Arten von synthetischen Daten
Synthetische Daten lassen sich grob in zwei Arten unterteilen:
- Vollständig synthetische Daten. Diese werden von Grund auf neu mithilfe von Algorithmen oder generativen Modellen wie Generative Adversarial Networks (GANs) oder Variational Autoencoder (VAE) erstellt. Dabei handelt es sich um spezielle künstliche neuronale Netze zur Modellierung und Generierung neuer Daten.
- Teilweise synthetische Daten. Diese werden erstellt, indem nur die sensiblen Attribute in realen Datensätzen ersetzt werden.
Generierung synthetischer Daten
Die Techniken zur Generierung synthetischer Daten haben sich erheblich weiterentwickelt. Frühe Modelle basierten auf regelbasierten Systemen und grundlegenden statistischen Methoden. Beispieldatensätze aus Datenbanken oder von Business-Intelligence-Anbietern (BI) verwenden auch heute noch häufig einfache Regeln, die Wertebereiche und Muster von Datenwerten innerhalb einer bestimmten Spalte definieren.
Heute nutzen Dateningenieure verschiedene Generierungsmethoden, die auf diesen frühen Ansätzen aufbauen. Einfachere Methoden basieren auf Zufallsstichproben aus statistischen Verteilungen, die die Eigenschaften der Originaldaten widerspiegeln. Komplexere Ansätze wie die agentenbasierte Modellierung simulieren einzelne Agenten, die sich wie Kunden verhalten und künstliche Daten im System generieren.
Die eigentliche Innovation – Generative Adversarial Networks (GAN) – stammt aber aus Deep-Learning-Ansätzen. Diese besondere Klasse von Modellen ist darauf ausgelegt, neue, realistisch wirkende Daten wie Bilder, Texte, Musik oder andere Datensätze zu erzeugen.
GANs funktionieren so, dass sie zwei neuronale Netze gegeneinander antreten lassen: Das eine Netz erzeugt synthetische Daten, das andere versucht zu erkennen, ob diese echt oder künstlich sind. Mit jeder Trainingsrunde lernt das erzeugende Netz besser, die Struktur und Verteilung der echten Daten nachzubilden. So können selbst komplexe Muster reproduziert werden – zum Beispiel Kundenabwanderung, Surfverhalten, Transaktionsfolgen oder seltene Ausreißerfälle. Durch diesen Prozess entwickelt der Generator ein erstaunliches Gespür für realistische Datensimulation.
Die zugrunde liegenden Originaldaten gelten dabei als Abbild einer realen Umgebung. Das ist entscheidend, weil ein generatives Modell nicht automatisch zwischen relevanten Informationen und zufälligem Rauschen unterscheiden kann, wenn es dafür nicht gezielt trainiert wird. Deshalb ist die Überprüfung und Qualitätssicherung der Ausgangsdaten ein zentraler Schritt bei der Erzeugung synthetischer Daten.
Ein Beispiel: Wenn man ein bereinigtes Datensample verwendet – also eines, bei dem Dubletten, unvollständige Datensätze oder Eingabefehler entfernt wurden – eignet sich dieses gut, um etwa Kundendemografien zu modellieren. Es spiegelt aber nicht mehr die unordentliche Realität wider, aus der das ursprüngliche Datenmaterial entstanden ist. Gerade diese Unvollkommenheit ist jedoch oft entscheidend, wenn man reale Verhaltensmuster möglichst genau nachbilden will.
Governance und synthetische Daten
Für die Data Governance im Rahmen von Vorschriften wie der DSGVO können vollständig synthetische Daten wertvoll sein. Sie verringern das Risiko einer Re-Identifizierung, da sie keiner realen Person entsprechen. Mit teilweise synthetischen Methoden gibt es jedoch noch eine weitere Möglichkeit, dieses Ziel zu erreichen.
Anders als vollständig synthetischen Techniken fügen teilweise synthetische Methoden wie Differential Privacy sorgfältig kalibrierte Störsignale hinzu, um einzelne Datensätze zu schützen und gleichzeitig die statistischen Eigenschaften der Datensätze zu erhalten.
Beispielsweise kann Differential Privacy ein Geburtsdatum ändern, indem eine zufällige Anzahl von Tagen innerhalb eines bestimmten Bereichs addiert oder subtrahiert wird. Statt des Originaldatums 15.11.1995 also beispielsweise 23.11.1995. Die Datenquelle ist anhand dieses Datums nicht mehr identifizierbar: Der Datensatz ist nun teilweise synthetisch, bleibt aber für die meisten Analysen und Vorhersagemodelle immer noch ausreichend genau.
Trotz aller Vorteile erfordern diese Verfahren eine konsequente Aufsicht – sie sind kein Freifahrtschein für die Umgehung von Compliance-Regeln. Auch synthetische Daten unterliegen denselben organisatorischen Kontrollen wie echte Daten: Zugriffsbeschränkungen, Nachvollziehbarkeit und Dokumentation ihrer Herkunft (Data Lineage). Wenn Business-Intelligence-Analysten solche Daten in Dashboards integrieren, muss klar erkennbar sein, welche Informationen real, welche synthetisch sind und wie sie erzeugt wurden.
Zwar reduziert das Konzept der Differential Privacy die Wahrscheinlichkeit, dass sich ein einzelner Datenpunkt auf eine reale Person zurückverfolgen lässt – doch in der Praxis werden synthetische Datensätze nach ihrer Erzeugung selten geprüft. Umso wichtiger ist ein reproduzierbarer Audit-Trail, also eine lückenlose Nachverfolgbarkeit aller Schritte der Datenerzeugung. Nur so lässt sich sicherstellen, dass Datenschutz, Transparenz und Datenqualität auch in synthetischen Umgebungen gewährleistet bleiben.
Die Vor- und Nachteile von realen und synthetischen Daten
Reale Daten spiegeln die Komplexität der Welt wider – mit all ihren Unregelmäßigkeiten, saisonalen Schwankungen und schwer vorhersagbaren Einflüssen. Obwohl Datenerhebung in der Theorie einfach klingt, ist sie in der Praxis oft aufwendig und vielschichtig.
Der Aufwand zeigt sich besonders in neuen oder experimentellen Anwendungsszenarien: Die Erhebung realer Daten ist hier teuer, zeitintensiv und unterliegt in vielen Branchen strengen gesetzlichen Auflagen. In regulierten Bereichen – zum Beispiel im Gesundheitswesen oder im Finanzsektor – kann es Wochen dauern, bis eine Datenerhebung überhaupt genehmigt wird. Datenschutz und Ethik spielen hier eine zentrale Rolle: Zustimmung der Betroffenen, sichere Speicherung und Einhaltung von Vorschriften wie der DSGVO sind unverzichtbar und fügen zusätzliche Komplexität hinzu.
Die systematische Verzerrung (Bias) ist ein weiteres Problem bei der Erhebung realer Daten. Reale Daten spiegeln oft bestehende Muster wider, die nicht mehr angemessen oder repräsentativ sind – beispielsweise gesellschaftliche oder historische Ungleichheiten. Sie können dann diese Muster unbeabsichtigt fortschreiben. So sind etwa Frauen oder Minderheiten in älteren Versicherungsdaten häufig unterrepräsentiert. Aber auch weniger brisante Beispiele zeigen das Problem: Daten, die ein Mobilfunkanbieter vor Jahren gesammelt hat, enthalten Nutzungsprofile von veralteten Geräten und Tarifen – Informationen, die heute kaum noch relevant sind. Modelle, die auf solchen Daten trainiert werden, riskieren, diese Verzerrungen zu übernehmen oder sogar zu verstärken.
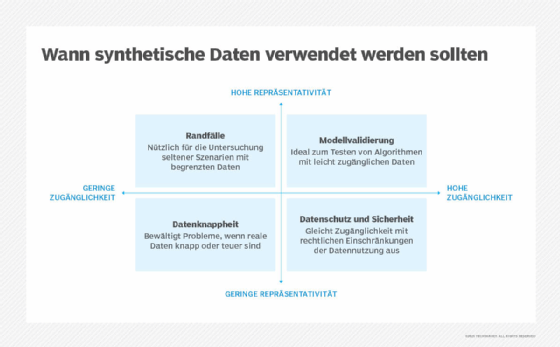
Ein anderes Problem: In einigen Fällen kann die reale Datenbasis zu homogen sein, um seltene Ereignisse oder Randfälle zuverlässig abzubilden. Ein typisches Beispiel ist ein Betrugserkennungsmodell in einem Zahlungssystem: Betrugsfälle treten vergleichsweise selten auf, so dass die vorhandenen echten Daten in der Regel nicht ausreichen, um ein leistungsfähiges Modell zu trainieren.
In solchen Situationen bietet die synthetische Datenerzeugung einen entscheidenden Vorteil. Sie ermöglicht es, den Datenaufbau gezielt zu steuern und künstlich Datensätze zu erzeugen, die seltene oder kritische Szenarien enthalten. So lassen sich Testdaten mit kontrollierten Anomalien generieren – also genau jene Fälle, die in realen Daten kaum vorkommen, für das Modelltraining aber essenziell sind.
Einschränkungen synthetischer Daten
In der Praxis sind synthetische Daten nur so gut wie die Modelle und Annahmen, die zu ihrer Generierung verwendet werden. Wenn das zugrunde liegende Verständnis der abzubildenden Phänomene unvollständig oder fehlerhaft ist, spiegeln sich diese Schwächen unmittelbar in den erzeugten Daten – und damit auch in den Systemen wider, die darauf aufbauen. Ein weiteres Risiko besteht darin, dass synthetische Daten ungeahnte Korrelationen oder subtile Muster der Realität nicht erfassen, weil sie nur das wiedergeben, was im Modell vorgesehen ist.
Diese Grenzen zeigen sich häufig beim Einsatz von KI-Modellen, die auf synthetischen Daten trainiert wurden: In kontrollierten Testumgebungen funktionieren sie oft hervorragend, stoßen aber im realen Einsatz an ihre Grenzen, sobald unvorhergesehene Einflüsse oder Datenabweichungen auftreten. Gerade im Bereich der Prognosen gilt: Echte Daten sind unschlagbar – vorausgesetzt, sie liegen in ausreichender Menge vor, sind aktuell, rechtlich unbedenklich und qualitativ hochwertig.
Anders sieht es bei hypothetischen Szenarien aus, zum Beispiel bei der Erschließung neuer Märkte oder dem Testen von Extremsituationen. Hier fehlt meist die historische Datengrundlage, die ein Modell benötigt. In solchen Fällen spielt die synthetische Datenerzeugung ihre Stärke aus: Sie erlaubt es, Modelle zunächst mit realen Daten zu trainieren und anschließend mit künstlich erzeugten Daten in Stressszenarien zu prüfen – etwa simulierten Finanzkrisen, extremen Wetterereignissen oder seltenen Krankheitsbildern.
Kritiker warnen jedoch vor einer Scheinsicherheit durch synthetische Daten. Wenn Entscheidungen mit realen Auswirkungen, zum Beispiel im Gesundheitswesen oder im Finanzbereich, auf Modellen beruhen, die auf synthetischen Daten trainiert wurden, stellt sich die Frage: Wie verlässlich und fair sind diese Entscheidungen tatsächlich?
Der Einwand ist berechtigt. Reale Daten zeichnen sich durch Authentizität aus – sie bilden die komplexen, oft unerwarteten Zusammenhänge der Welt ab, die synthetische Daten nur schwer nachbilden können. Gleichzeitig sind reale Daten jedoch häufig unvollständig, verzerrt oder mit erheblichen Datenschutz- und Regulierungsrisiken behaftet.
In diesem Spannungsfeld liegt die eigentliche Herausforderung: den richtigen Ausgleich zwischen Realismus und Sicherheit zu finden – und zu verstehen, wann synthetische Daten eine Ergänzung sind, aber kein Ersatz.
Anwendungsfälle und Branchentrends
Mehrere Branchen setzen synthetische Daten bereits gezielt und praxisnah ein – jeweils mit domänenspezifischen Vorteilen und Herausforderungen.
Im Finanzsektor werden synthetische Transaktionsdaten beispielsweise genutzt, um eine sichere Zusammenarbeit zwischen Institutionen zu ermöglichen. Banken können so modellierte Datensätze austauschen, ohne reale Kundendaten offenzulegen. Betrugserkennungsmodelle lassen sich dadurch verbessern, ohne gegen Datenschutzauflagen zu verstoßen.
Ganz einfach ist das jedoch nicht: Synthetische Daten können bekannte Betrugsmuster gut reproduzieren, tun sich aber schwer damit, neue, unvorhersehbare Verhaltensweisen zu simulieren. Dennoch sind sie nützlich, um die Empfindlichkeit von Modellen gegenüber Schwellenwerten oder gezielten Manipulationsversuchen zu testen.
Im Gesundheitswesen hat der Einsatz synthetischer Daten die Entwicklung medizinischer KI-Systeme spürbar beschleunigt. Trainingsdatensätze aus synthetischen Patientendaten ermöglichen es Forschern, Algorithmen zu entwickeln, ohne sensible Gesundheitsinformationen preiszugeben. Damit können Innovationen vorangetrieben werden, während gleichzeitig die Privatsphäre der Patienten gewahrt bleibt. So entstehen beispielsweise synthetische CT-Scans oder Laborergebnisse seltener Krankheiten, die in der pharmazeutischen Forschung und Entwicklung wertvolle Dienste leisten.
Auch bei der Entwicklung autonomer Fahrzeuge spielt die synthetische Datenerzeugung eine Schlüsselrolle. Die Simulationen von seltenen oder gefährlichen Situationen, zum Beispiel Verkehrsunfällen oder riskantem Fußgängerverhalten, sind für die Sicherheit solcher Systeme unverzichtbar, lassen sich in der Realität aber kaum oder gar nicht nachstellen. Virtuelle Szenarien mit künstlichen Daten ermöglichen es, solche Extremfälle sicher zu testen. In Kombination mit realen Fahrdaten entsteht so ein umfassendes Testfeld, das sowohl Vielfalt als auch Sicherheit gewährleistet.
Wann was verwenden?
Die folgende Tabelle fasst einige gängige Entscheidungskriterien für die Wahl zwischen realen und synthetischen Daten zusammen:
| Szenario |
Synthetische Daten |
Reale Daten |
Anmerkungen |
| Seltene Ereignisse/Grenzfälle |
Bevorzugt: schnelle Generierung Tausender Grenzfälle |
Einschränkung: es kann Jahre dauern, bis genügend Beispiele gesammelt sind |
Verwenden Sie synthetische Daten zur Ergänzung. Validieren Sie diese anhand realer Proben, sofern verfügbar. |
| Datenschutzsensible Anwendungen |
Bevorzugt: Einhaltung gesetzlicher Vorschriften, Datenminimierung |
Hohes Risiko: Offenlegung personenbezogener Daten, gesetzliche Beschränkungen |
Dokumentieren Sie den Prozess der synthetischen Generierung für Audit-Trails. |
| System-/Pipelinetests |
Bevorzugt: kontrollierte, wiederholbare Testszenarien |
Riskant: Produktionsdaten können in Testumgebungen offengelegt werden |
Synthetische Daten ermöglichen sicheres Testen ohne Zugriff auf Produktionsdaten. |
| Modelltraining (initial) |
Gut: schnelle Iteration, perfekte Kennzeichnung |
Essenziell: grundlegende Fakten, reale Verteilungen |
Beginnen Sie mit dem Verständnis realer Daten und ergänzen Sie diese mit synthetischen Daten. |
| Modellvalidierung (final) |
Unzureichend: könnte die Komplexität der realen Welt verfehlen |
Erforderlich die einzige Möglichkeit, die tatsächliche Leistung zu überprüfen |
Niemals ohne Validierung mit realen Daten bereitstellen. |
| Dashboard-Prototyping |
Bevorzugt: kein Zugriff auf Produktionsdaten erforderlich |
Zugriffsbeschränkungen: kann die Entwicklung verzögern |
Verwenden Sie synthetische Daten für das Design, wechseln Sie für die Live-Schaltung zu realen Daten. |
| Regulatory submissions |
Kontextabhängig: dokumentieren Sie Ihre Methodik gründlich |
Bevorzugt: höheres Vertrauen der Aufsichtsbehörden |
Hybride Ansätze sind für die Einhaltung der Vorschriften häufig am effektivsten. |
Integration von synthetischen und realen Daten
Eine effektive Methode, um synthetische und reale Daten zusammen zu verwenden, ist ein iterativer Prozess. Beginnen Sie mit einem reduzierten Satz an realen Daten, um synthetische Datensätze zu generieren und erste Modelle zu trainieren. Validieren Sie diese Modelle anschließend anhand realer Daten und verfeinern Sie die synthetische Generierung, basierend auf den verbesserten Ergebnissen. Auf diese Weise werden die Stärken beider Datentypen genutzt und ihre Schwächen gemildert.
Eine klare Dokumentation ist unerlässlich, um nachzuverfolgen, wo und wie synthetische Daten verwendet werden, insbesondere bei kritischen Anwendungen im Finanz- oder Gesundheitswesen. Eine zuverlässige Herkunft der Daten (Data Provenance) und Transparenz bezüglich ihres Ursprungs unterstützen ethische Standards und die Einhaltung gesetzlicher Vorschriften.
Ebenso wichtig ist die Notwendigkeit einer strengen Bewertung, um festzustellen, wie gut synthetische Daten die statistischen Eigenschaften der Quelldaten bewahren und ob sie Verzerrungen verursachen.
Fachliche Experten sollten bei der Beurteilung der Qualität synthetischer Daten eine zentrale Rolle spielen. Statistische Ähnlichkeit reicht nicht aus: Die Daten müssen für einen Fachexperten sinnvoll sein.
Letztendlich hängt die Wahl zwischen synthetischen oder realen Daten vom Szenario ab, das modelliert wird, sowie von der Entwicklungsphase des Modells oder Systems.
Die folgende Tabelle verdeutlicht, wann während der Entwicklung bestimmte Entscheidungen getroffen werden sollten.
| Phase |
Primäre Datenquelle |
Sekundäre Datenquelle |
Validierungsansatz |
| Forschung/Exploration |
reale Daten |
synthetische Daten zum Lückenfüllen |
statistischer Vergleich von Verteilungen |
| Erste Entwicklung |
synthetische Daten |
reale Daten als Referenz |
regelmäßige Validierung mit realen Daten |
| Systemtests |
synthetische Daten |
- |
kontrollierte Testfallgenerierung |
| Modelltraining |
Hybrid (reale + synthetische Daten) |
- |
Kreuzvalidierung beider Quellen |
| Validierung vor Live-Einsatz |
reale Daten (Teilmenge oder Hold-out-Datensatz ) |
- |
Leistungskennzahlen nur auf Basis realer Daten |
| Überwachung |
reale Daten |
- |
kontinuierliche Leistungsüberwachung in der realen Welt |
Synthetische Daten und Strategie
Da KI immer mehr Modelle der realen Welt erfordert, haben sich synthetische Daten von einer Datenverarbeitungstechnik zu einem strategischen Vorteil entwickelt. Das spiegelt wider, wie Teams mit Datenschutz, Zeit, Budget und regulatorischen Auflagen umgehen.
Kompromisse sind weiterhin notwendig. Synthetische Daten sind kein perfekter Ansatz, wurden jedoch aufgrund von Bedenken hinsichtlich ihrer Authentizität oft abgelehnt. Letztendlich sind synthetische Daten ein Werkzeug. Und wie bei jedem Werkzeug kommt es darauf an, es zur richtigen Zeit für die richtige Aufgabe einzusetzen.
Die Zukunft der Daten in der prädiktiven Analyse ist weder synthetisch noch real, sondern synthetisch und real - wobei beide Datenarten intelligent zusammenwirken.






