Synthetische Daten
Was sind synthetische Daten?
Synthetische Daten sind Informationen, die künstlich produziert und nicht durch reale Ereignisse generiert wurden. Sie werden algorithmisch erstellt und als Ersatz für Testdatensätze von Produktions- oder Betriebsdaten verwendet, um mathematische Modelle zu validieren und Modelle für maschinelles Lernen (Machine Learning, ML) zu trainieren.
Da es schwierig, teuer und zeitaufwendig ist, qualitativ hochwertige Daten aus der realen Welt zu sammeln, ermöglichen es synthetische Daten, schnell, einfach und digital Daten in beliebiger Menge zu erzeugen, die auf ihre speziellen Bedürfnisse zugeschnitten sind.
Warum sind synthetische Daten wichtig?
Die Verwendung synthetischer Daten findet immer mehr Anklang, da sie im Vergleich zu realen Daten mehrere Vorteile bieten. Gartner prognostiziert, dass bis 2030 synthetische Daten reale Daten in KI-Modellen zum Großteil ersetzen werden.
Die größte Anwendung für synthetische Daten ist das Training von neuronalen Netzen und Machine-Learning-Modellen, da die Entwickler dieser Modelle sorgfältig gelabelte Datensätze benötigen, die von einigen Tausend bis zu zehn Millionen Elementen reichen. Synthetische Daten können künstlich erzeugt werden, um reale Datensätze zu imitieren. So können Unternehmen ohne großen finanziellen und zeitlichen Aufwand vielfältige und große Mengen an Trainingsdaten erzeugen.
Synthetische Daten lassen sich auch dazu verwenden, die Privatsphäre der Nutzer zu schützen und die Datenschutzgesetze einzuhalten, insbesondere wenn es um sensible Gesundheits- und persönliche Daten geht. Außerdem können sie dazu dienen, Verzerrungen in Datensätzen zu verringern, indem sichergestellt wird, dass die Verbraucher Zugang zu vielfältigen Daten haben, welche die reale Welt genau wiedergeben.
Wie werden synthetische Daten erzeugt?
Der Prozess der Generierung synthetischer Daten unterscheidet sich je nach verwendeten Tools und Algorithmen und dem spezifischen Anwendungsfall.
Drei gängige Techniken für die Erstellung synthetischer Daten sind:
- Zahlen aus einer Verteilung ziehen. Die zufällige Auswahl von Zahlen aus einer Verteilung ist eine gängige Methode zur Erstellung synthetischer Daten. Auch wenn diese Methode nicht den Einblick in reale Daten bietet, kann sie eine Datenverteilung erzeugen, die den realen Daten ähnlich ist.
- Agentenbasierte Modellierung. Bei dieser Simulationstechnik werden einzigartige Agenten geschaffen, die miteinander kommunizieren. Diese Methoden sind besonders hilfreich, wenn Sie untersuchen wollen, wie verschiedene Agenten, zum Beispiel Mobiltelefone, Menschen oder Computerprogramme, in einem komplexen System miteinander interagieren. Mit vorgefertigten Kernkomponenten erleichtern Python-Pakete wie Mesa die schnelle Entwicklung agentenbasierter Modelle und deren Anzeige über einen Browser.
- Generative Modelle. Diese Algorithmen können synthetische Daten generieren, die die statistischen Eigenschaften oder Merkmale von realen Daten nachbilden. Generative Modelle verwenden einen Satz von Trainingsdaten, um die statistischen Muster und Beziehungen in den Daten zu erlernen, und nutzen dieses Wissen dann, um neue synthetische Daten zu erzeugen, die den Originaldaten ähnlich sind. Beispiele für generative Modelle sind Generative Adversarial Networks (GAN) und Variational Autoencoders (VAE).
Was sind Vor- und Nachteile synthetischer Daten?
Synthetische Daten bieten folgende Vorteile:
- Anpassbare Daten. Ein Unternehmen kann synthetische Daten an seine Bedürfnisse anpassen, indem es die Daten auf bestimmte Bedingungen zuschneidet, die mit authentischen Daten nicht erreicht werden können. Sie können auch Datensätze für Softwaretests und die Qualitätssicherung für DevOps-Teams generieren.
- Kostengünstig. Synthetische Daten sind eine kostengünstige Alternative zu realen Daten. Beispielsweise kann die Erhebung echter Unfalldaten für einen Automobilhersteller teurer sein als die Generierung von Simulationsdaten.
- Kennzeichnung der Daten. Selbst wenn synthetische Daten verfügbar sind, sind sie nicht immer gelabelt. Bei überwachten Lernaufgaben kann das manuelle Labeln einer Vielzahl von Instanzen zeitaufwendig und fehleranfällig sein. Synthetisch gelabelte Daten können erstellt werden, um den Prozess der Modellentwicklung zu beschleunigen. Außerdem wird dadurch die Genauigkeit des Labelns garantiert.
- Schnellere Produktion. Da synthetische Daten nicht aus tatsächlichen Ereignissen gewonnen werden, ist es mit der richtigen Software und Technologie möglich, einen Datensatz schneller zu erstellen. So kann in kürzerer Zeit eine große Menge an künstlichen Daten erstellt werden.
- Vollständige Annotation. Perfekte Annotationen machen die manuelle Datenerfassung überflüssig. Jedes Objekt in einer Szene kann automatisch eine Vielzahl von Annotationen erzeugen. Dies ist auch einer der Hauptgründe, warum synthetische Daten im Vergleich zu echten Daten so kostengünstig sind.
- Schutz der Daten. Synthetische Daten können zwar echten Daten ähneln, sollten aber keine Informationen enthalten, die zur Identifizierung der echten Daten verwendet werden können. Diese Eigenschaft macht synthetische Daten anonym und geeignet für die Verbreitung, was ein großer Pluspunkt für die Gesundheits- und Pharmaindustrie ist.
- Volle Kontrolle für den Benutzer. Eine Simulation synthetischer Daten ermöglicht die vollständige Kontrolle über jeden Aspekt. Die Person, die mit dem Datensatz arbeitet, kann die Häufigkeit der Ereignisse, die Verteilung der Elemente und viele andere Faktoren steuern. Machine-Learning-Anwender haben bei der Verwendung synthetischer Daten auch die vollständige Kontrolle über den Datensatz. Einige Beispiele sind die Kontrolle über den Grad der Klassentrennung, den Stichprobenumfang und den Grad des Rauschens im Datensatz.
Synthetische Daten bringen auch einige Nachteile mit sich, zum Beispiel Inkonsistenzen bei dem Versuch, die Komplexität des Originaldatensatzes zu replizieren, und die Unmöglichkeit, authentische Daten vollständig zu ersetzen, da immer noch genaue, authentische Daten erforderlich sind, um nützliche synthetische Beispiele für die Informationen zu erstellen.
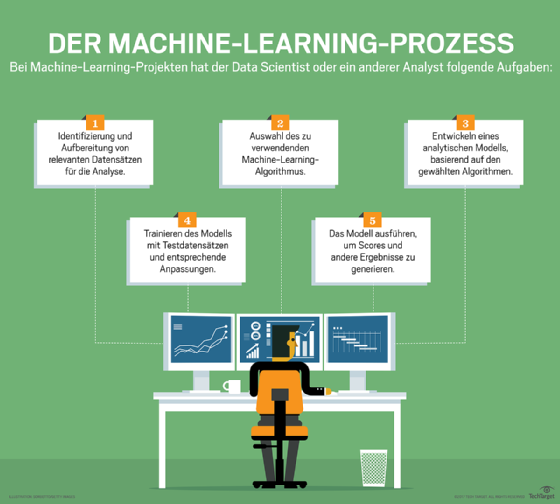
Was sind Anwendungsfälle für synthetische Daten?
Typische Anwendungsfälle für synthetische Daten sind unter anderem:
- Testen. Im Vergleich zu regelbasierten Testdaten sind synthetische Testdaten einfacher zu erstellen und bieten Flexibilität, Skalierbarkeit sowie Realismus. Für datengesteuerte Tests und Softwareentwicklung sind synthetische Daten von entscheidender Bedeutung.
- KI/ML-Modelltraining. Synthetische Daten werden zunehmend zum Trainieren von KI-Modellen verwendet, da sie häufig besser sind als reale Daten und für die Entwicklung besserer KI-Modelle unerlässlich sind. Die Leistung eines Modells wird durch synthetische Trainingsdaten verbessert, die auch Verzerrungen ausschließen und neues Wissen über den Bereich und Erklärungsmöglichkeiten liefern. Die synthetischen Daten sind nicht nur datenschutzkonform, sondern verbessern dank der Art des KI-gestützten Synthetisierungsprozesses auch die Originaldaten. In künstlichen Trainingsdaten können zum Beispiel ungewöhnliche Muster und Vorkommnisse aufgewertet werden.
- Datenschutzbestimmungen. Synthetische Daten ermöglichen es Datenwissenschaftlern, Datenschutzgesetze wie die EU-Datenschutz-Grundverordnung (EU-DSGVO) und den California Consumer Privacy Act (CCPA) einzuhalten. Sie sind auch die beste Option, wenn sensible Datensätze für Tests oder Trainings verwendet werden. Synthetische Daten ermöglichen es Unternehmen, Erkenntnisse zu gewinnen, ohne die Einhaltung des Datenschutzes zu gefährden.
- Gesundheitsdaten und vertrauliche Daten. Gesundheitsdaten und vertrauliche Daten eignen sich besonders gut für einen synthetischen Ansatz, da die Datenschutzbestimmungen in diesen Bereichen erhebliche Einschränkungen vorsehen. Durch die Verwendung synthetischer Daten können Forscher die benötigten Informationen extrahieren, ohne die Privatsphäre der Menschen zu verletzen. Da synthetische Daten nicht die Daten tatsächlicher Patienten darstellen, ist es äußerst unwahrscheinlich, dass sie zur Re-Identifizierung eines tatsächlichen Patienten oder seines persönlichen Datensatzes führen. Synthetische Daten haben auch einen großen Vorteil gegenüber Datenmaskierungstechniken, die größere Risiken für die Privatsphäre mit sich bringen.
Welche Beispiele gibt es für synthetische Daten?
Synthetische Daten werden in vielen verschiedenen Branchen für unterschiedliche Anwendungsfälle verwendet. Im Folgenden finden Sie einige Beispiele für die Verwendung synthetischer Daten:
- Mediendaten. In diesem Anwendungsfall werden Computergrafiken und Bildverarbeitungsalgorithmen verwendet, um synthetische Bilder, Audio- und Videodaten zu erzeugen. Amazon verwendet zum Beispiel synthetische Daten, um das Sprachsystem von Amazon Alexa zu trainieren.
- Textdaten. Dies kann Chatbots, maschinelle Übersetzungsalgorithmen und Stimmungsanalysen auf der Grundlage von künstlich erzeugten Textdaten umfassen. ChatGPT ist ein Beispiel für ein Tool, das Textdaten verwendet.
- Tabellarische Daten. Hierbei handelt es sich um synthetisch erzeugte Datentabellen, die für die Datenanalyse, das Modelltraining und andere Anwendungen verwendet werden.
- Unstrukturierte Daten. Unstrukturierte Daten können Bilder, Video- und Audiodaten umfassen, die meist in Bereichen wie Computer Vision, Spracherkennung und autonome Fahrzeugtechnologie eingesetzt werden. Googles Waymo zum Beispiel verwendet synthetische Daten, um seine selbstfahrenden Autos zu trainieren.
- Daten für Finanzdienstleistungen. Der Finanzsektor stützt sich stark auf synthetische Daten, insbesondere bei der Betrugserkennung, dem Risikomanagement und der Bewertung von Kreditrisiken. JPMorgan und American Express zum Beispiel verwenden synthetische Finanzdaten, um die Betrugserkennung zu verbessern.
- Fertigungsdaten. Die Fertigungsindustrie verwendet synthetische Daten für Qualitätskontrolltests und vorausschauende Wartung. Das deutsche Versicherungsunternehmen Provinzial beispielsweise testet synthetische Daten für prädiktive Analysen.
Wie unterscheiden sich synthetische Daten von echten Daten?
Finanzdienstleistungen und das Gesundheitswesen sind zwei Branchen, die von Techniken für synthetische Daten profitieren. Mit diesen Techniken lassen sich Daten mit ähnlichen Attributen wie echte sensible oder regulierte Daten erzeugen. Dies ermöglicht es Datenexperten, Daten freier zu nutzen und weiterzugeben.
Mit synthetischen Daten können Datenexperten im Gesundheitswesen beispielsweise die öffentliche Nutzung von Daten auf Datensatzebene ermöglichen, ohne die Vertraulichkeit der Patienten zu verletzen.
Im Finanzsektor können synthetische Datensätze, wie zum Beispiel Debit- und Kreditkartenzahlungen, die wie typische Transaktionsdaten aussehen und sich auch so verhalten, helfen, betrügerische Aktivitäten aufzudecken. Datenwissenschaftler können synthetische Daten verwenden, um Betrugserkennungssysteme zu testen oder zu bewerten und neue Methoden zur Betrugserkennung zu entwickeln. Synthetische Finanzdatensätze finden Sie auf Kaggle, einer Crowdsourced-Plattform, die Wettbewerbe für prädiktive Modellierung und Analytik veranstaltet.
DevOps-Teams verwenden synthetische Daten für Softwaretests und Qualitätssicherung. Sie können künstlich erzeugte Daten in einen Prozess einfügen, ohne authentische Daten aus der Produktion zu nehmen. Einige Experten empfehlen DevOps-Teams jedoch, Datenmaskierungstechniken den Techniken für synthetische Daten vorzuziehen, da Produktionsdatensätze komplexe Beziehungen enthalten, die es schwierig machen, schnell und kostengünstig eine genaue Darstellung zu erstellen.
Was verbindet synthetische Daten und maschinelles Lernen?
Synthetische Daten gewinnen im Bereich des maschinellen Lernens immer mehr an Bedeutung. Machine-Learning-Algorithmen werden mit einer immensen Menge an Daten trainiert, und die Sammlung der erforderlichen Menge an gekennzeichneten Trainingsdaten kann kostspielig sein.
Synthetisch erzeugte Daten können Unternehmen und Forschern dabei unterstützen, Datenbestände aufzubauen, die zum Trainieren und sogar zum Vortrainieren von Machine-Learning-Modellen benötigt werden, eine Technik, die als Transfer Learning bezeichnet wird.
Es gibt bereits Forschungsanstrengungen, um die Nutzung synthetischer Daten für maschinelles Lernen voranzutreiben. So haben beispielsweise Mitglieder des Data to AI Lab am Massachusetts Institute of Technology Laboratory for Information and Decision Systems die jüngsten Erfolge mit ihrem Synthetic Data Vault dokumentiert, der Machine-Learning-Modelle zur automatischen Generierung und Extraktion eigener synthetischer Daten erstellen kann.
Auch Unternehmen beginnen, mit Techniken für synthetische Daten zu experimentieren. So hat beispielsweise ein Team bei Deloitte LLC synthetische Daten verwendet, um ein genaues Modell zu erstellen, indem es 80 Prozent der Trainingsdaten künstlich generierte und reale Daten als Ausgangsdaten verwendete. Computer Vision, Bilderkennung und Robotik sind weitere Anwendungen, die von der Verwendung synthetischer Daten profitieren.
Geschichte synthetischer Daten
Synthetische Daten gehen auf die Einführung der Computertechnik in den 1970er Jahren zurück. Die meisten anfänglichen Systeme und Algorithmen waren auf Daten angewiesen, um zu funktionieren. Begrenzte Verarbeitungskapazitäten, Probleme bei der Erfassung großer Datenmengen und Bedenken hinsichtlich des Datenschutzes führten jedoch zur Schaffung synthetischer Daten.
Im Zuge des ImageNet-Wettbewerbs von 2012 – gemeinhin als Urknall der KI bezeichnet – gelang es einer Gruppe von Forschern unter der Leitung von Geoff Hinton, ein künstliches neuronales Netzwerk zu trainieren, das einen Wettbewerb zur Bildklassifizierung mit einem verblüffend großen Vorsprung gewann. Die Forscher begannen ernsthaft nach künstlichen Daten zu suchen, nachdem sich herausgestellt hatte, dass neuronale Netze Gegenstände schneller erkennen können als Menschen.
Erfahren Sie mehr über Datenverwaltung
-
![]()
Wie Unternehmen dem Risiko KI-Slop begegnen können
Von: Sean Kerner
-
![]()
Synthetische oder reale Daten für Predictive Analytics nutzen?
Von: Donald Farmer
-
![]()
Ein Model Drift eines KI-Modells erkennen und korrigieren
Von: Stephen Bigelow
-
![]()
Wie man ein virtuelles Netzwerklabor für KI-Workloads aufbaut
Von: Verlaine Muhungu



