
Cloud Disaster Recovery (Cloud DR)
Was ist Cloud Disaster Recovery (Cloud DR)?
Cloud Disaster Recovery (Cloud DR) ist eine Kombination von Strategien und Diensten zur Sicherung von Daten, Anwendungen und anderen Ressourcen in einer Public Cloud oder bei einem speziellen Dienstanbieter. Im Falle einer Katastrophe können die betroffenen Daten, Anwendungen und anderen Ressourcen im lokalen Rechenzentrum - oder bei einem Cloud-Anbieter - wiederhergestellt werden, um den normalen Betrieb des Unternehmens wieder aufzunehmen.
Das Ziel von Cloud DR ist praktisch identisch mit dem von herkömmlichem Disaster Recovery (DR): Schutz wertvoller Unternehmensressourcen und Gewährleistung, dass auf geschützte Ressourcen zugegriffen werden kann und diese wiederhergestellt werden können, um den normalen Geschäftsbetrieb fortzusetzen.
Die Bedeutung von Cloud DR
DR ist ein zentrales Element jeder Business Continuity (BC)-Strategie. Sie umfasst die Replikation von Daten und Anwendungen von der primären Infrastruktur eines Unternehmens auf eine Backup-Infrastruktur, die sich in der Regel an einem entfernten geografischen Standort befindet.
Vor dem Aufkommen von Cloud-Konnektivität und Self-Service-Technologien waren die traditionellen DR-Optionen auf lokale DR und Implementierungen an einem sekundären Standort beschränkt. Lokale DR schützte nicht immer vor Katastrophen wie Bränden, Überschwemmungen und Erdbeben. Ein zweiter Standort (Offsite-DR) bot einen weitaus besseren Schutz vor physischen Katastrophen, aber die Implementierung und Wartung eines zweiten Rechenzentrums verursachten erhebliche Kosten.
Mit dem Aufkommen von Cloud-Technologien konnten Public-Cloud- und Managed-Service-Anbieter eine dedizierte Einrichtung installieren, um eine breite Palette an effektiven Backup- und DR-Diensten und -Funktionen anzubieten.
Die folgenden Gründe verdeutlichen die Bedeutung von Cloud-Speicher und Disaster Recovery:
- Cloud-DR gewährleistet die Geschäftskontinuität im Falle von Naturkatastrophen und Cyberangriffen, die den Geschäftsbetrieb stören und zu Datenverlusten führen können.
- Mit einer Cloud-Disaster-Recovery-Strategie können wichtige Daten und Anwendungen auf einem Cloud-basierten Server gesichert werden. Dies ermöglicht eine schnelle Datenwiederherstellung für Unternehmen nach einem Ereignis, wodurch Ausfallzeiten reduziert und die Auswirkungen des Ausfalls minimiert werden.
Cloud-basierte DR bietet im Vergleich zu herkömmlichen DR-Methoden mehr Flexibilität, geringere Komplexität, mehr Kosteneffizienz und höhere Skalierbarkeit. Unternehmen erhalten kontinuierlichen Zugang zu hoch automatisierten, hoch skalierbaren, selbstgesteuerten Offsite-DR-Services, ohne dass die Kosten für ein zweites Rechenzentrum anfallen und ohne dass sie DR-Tools auswählen, installieren und warten müssen.
So wählen Sie einen Cloud-DR-Anbieter
Ein Unternehmen sollte bei der Auswahl eines Cloud-DR-Anbieters die folgenden fünf Faktoren berücksichtigen:
- Entfernung. Ein Unternehmen muss die physische Entfernung und die Latenzzeit des Cloud-DR-Anbieters berücksichtigen. Eine zu nahe gelegene DR erhöht das Risiko einer gemeinsamen physischen Katastrophe, aber eine zu weit entfernte DR erhöht die Latenz und die Netzwerküberlastung und erschwert den Zugriff auf DR-Inhalte. Der Standort kann besonders heikel sein, wenn die DR-Inhalte von zahlreichen globalen Geschäftsstandorten aus zugänglich sein müssen.
- Verlässlichkeit. Achten Sie auf die Zuverlässigkeit des Cloud-DR-Anbieters. Auch in einer Cloud gibt es Ausfallzeiten, und ein Ausfall des Dienstes während der Wiederherstellung kann für das Unternehmen ebenso katastrophal sein.
- Skalierbarkeit. Achten Sie auf die Skalierbarkeit des Cloud-DR-Angebots. Es muss in der Lage sein, ausgewählte Daten, Anwendungen und andere Ressourcen zu schützen. Außerdem muss es in der Lage sein, bei Bedarf zusätzliche Ressourcen aufzunehmen und eine angemessene Leistung zu erbringen, wenn andere globale Kunden die Dienste nutzen.
- Sicherheit und Compliance. Es ist wichtig, die Sicherheitsanforderungen der DR-Inhalte zu verstehen und sicherzustellen, dass der Anbieter Authentifizierung, Virtuelle Private Netzwerke (VPN), Verschlüsselung und andere Tools zum Schutz der wertvollen Ressourcen des Unternehmens anbieten kann. Prüfen Sie die Compliance-Anforderungen, um sicherzustellen, dass der Anbieter für die Einhaltung von Compliance-Standards zertifiziert ist, die sich auf das Unternehmen beziehen, zum Beispiel DSGVO, ISO 27001, SOC 2 und SOC 3 und Payment Card Industry Data Security Standard (PCI DSS).
- Architektur. Überlegen Sie, wie die DR-Plattform aufgebaut sein muss. Es gibt drei grundlegende Ansätze für das DR, darunter die kalte (cold), warme (warm) und heiße (hot) Disaster Recovery. Diese Begriffe beziehen sich grob auf die Einfachheit, mit der ein System wiederhergestellt werden kann.
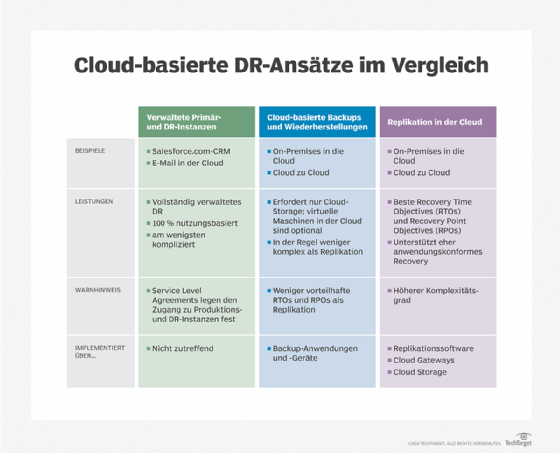
Ansätze für Cloud-DR
Im Folgenden werden die drei Hauptansätze für das Disaster Recovery in der Cloud beschrieben:
- Bei einer kalten Wiederherstellung (Cold Disaster Recovery) werden in der Regel Daten oder Images virtueller Maschinen (VM) gespeichert. Diese Ressourcen sind in der Regel nicht nutzbar, ohne dass zusätzliche Arbeiten wie das Herunterladen der gespeicherten Daten oder das Laden des Images in eine VM erforderlich sind. Cold DR ist in der Regel der einfachste Ansatz (oft nur Datenspeicherung) und der kostengünstigste Ansatz, aber es dauert am längsten, um Daten wiederherzustellen, so dass das Unternehmen im Falle einer Katastrophe die längste Ausfallzeit hat.
- Bei einem Warm DR handelt es sich in der Regel um einen Standby-Ansatz, bei dem doppelte Daten und Anwendungen bei einem Cloud-DR-Anbieter platziert und mit den Daten und Anwendungen im primären Rechenzentrum auf dem neuesten Stand gehalten werden. Die duplizierten Ressourcen führen jedoch keine Verarbeitung durch. Im Katastrophenfall kann ein warmes DR online gebracht werden, um den Betrieb vom DR-Anbieter wieder aufzunehmen. Oft genügt es, eine VM zu starten und IP-Adressen und Datenverkehr an die DR-Ressourcen umzuleiten. Die Wiederherstellung kann recht kurz sein, führt aber dennoch zu einer gewissen Ausfallzeit für die geschützten Workloads.
- Bei Hot DR handelt es sich in der Regel um eine parallele Live-Bereitstellung von Daten und Arbeitslasten, die gemeinsam im Tandembetrieb laufen. Das bedeutet, dass sowohl das primäre Rechenzentrum als auch der DR-Standort dieselben Workloads und Daten verwenden, die synchron laufen – beide Standorte teilen sich einen Teil des gesamten Anwendungsverkehrs. Wenn ein Standort von einer Katastrophe heimgesucht wird, kann der verbleibende Standort die Arbeit ohne Unterbrechung fortsetzen. Im Idealfall bemerken die Benutzer nichts von der Unterbrechung. Bei Hot DR gibt es keine Ausfallzeiten, aber es kann der teuerste und komplizierteste Ansatz sein.
Es ist möglich, verschiedene Ansätze zu kombinieren, so dass Workloads mit höherer Priorität einen Hot-Ansatz verwenden können, während Workloads oder Datensätze mit niedrigerer Priorität einen Warm- oder sogar Cold-Ansatz verwenden. Für Unternehmen ist es jedoch wichtig, den besten Ansatz für jede Arbeitslast oder Ressource zu bestimmen und einen Cloud-DR-Anbieter zu finden, der die gewünschten Ansätze angemessen unterstützen kann.
Vorteile von Cloud DR
Cloud-DR und -Backups bieten im Vergleich zu herkömmlichen DR-Strategien mehrere Vorteile:
Pay-as-you-go-Optionen. Unternehmen, die DR-Einrichtungen im Eigenbau bereitstellen, müssen mit erheblichen Kapitalkosten rechnen, während die Beauftragung von Anbietern von Offsite-DR-Diensten mit gemanagten Colocation-Services die Unternehmen oft an langfristige Serviceverträge bindet. Ein großer Vorteil von Cloud-Diensten ist das Pay-as-you-go-Modell, das es Firmen ermöglicht, eine wiederkehrende monatliche Gebühr nur für die genutzten Ressourcen und Dienste zu zahlen. Wenn Ressourcen hinzugefügt oder entfernt werden, ändern sich die Zahlungen entsprechend.
Das Cloud-Modell für die Bereitstellung von Diensten verwandelt die anfänglichen Kapitalkosten (Capex) in wiederkehrende Betriebskosten (Opex). Allerdings bieten Cloud-Anbieter häufig Rabatte für langfristige Ressourcenverpflichtungen an, was für größere Unternehmen mit statischem DR-Bedarf attraktiver sein kann.
Flexibilität und Skalierbarkeit. Herkömmliche DR-Ansätze, die in der Regel in lokalen oder entfernten Rechenzentren implementiert werden, schränken oft die Flexibilität und Skalierbarkeit ein. Das Unternehmen muss die für die Notfallwiederherstellung benötigten Server, Speicher, Netzwerkgeräte und Software-Tools kaufen und dann die für die Abwicklung des DR-Vorgangs erforderliche Infrastruktur entwerfen, testen und warten. Das ist wesentlich mehr, als wenn die DR in einem zweiten Rechenzentrum erfolgt. Dies stellt in der Regel einen großen Kapitalaufwand und wiederkehrende Kosten für das Unternehmen dar.
Cloud-DR-Optionen wie Public-Cloud-Dienste und Disaster Recovery as a Service (DRaaS) können enorme Mengen an Ressourcen auf Abruf bereitstellen, so dass Unternehmen so viele Ressourcen wie nötig einsetzen können - in der Regel über ein Self-Service-Portal - und diese Ressourcen dann anpassen können, wenn sich die geschäftlichen Anforderungen ändern, zum Beispiel wenn neue Workloads hinzugefügt oder alte Workloads und Daten außer Betrieb genommen werden.
Hohe Zuverlässigkeit und geografische Redundanz. Ein wesentliches Merkmal eines Cloud-Anbieters ist eine globale Präsenz, die sicherstellt, dass mehrere Rechenzentren Benutzer in den wichtigsten geopolitischen Regionen der Welt unterstützen. Cloud-Anbieter nutzen dies, um die Zuverlässigkeit ihrer Dienste zu verbessern und Redundanz zu gewährleisten. Unternehmen können die Vorteile der geografischen Redundanz (Geo-Redundanz) nutzen, um DR-Ressourcen in einer anderen Region oder sogar in mehreren Regionen zu platzieren und so die Verfügbarkeit zu maximieren. Das ideale Szenario für eine standortunabhängige Notfallwiederherstellung ist eine natürliche Eigenschaft der Cloud.
Einfaches Testen und schnelle Wiederherstellung. Cloud-Workloads arbeiten routinemäßig mit VMs, so dass es einfach ist, VM-Image-Dateien auf firmeninterne Testserver zu kopieren, um die Workload-Verfügbarkeit zu validieren, ohne die Produktions-Workloads zu beeinträchtigen. Darüber hinaus können Unternehmen Optionen mit hoher Bandbreite und schnellem Festplatten-I/O wählen, um die Datenübertragungsgeschwindigkeiten zu optimieren und so die Anforderungen an die Recovery Time Objective (RTO) zu erfüllen. Datenübertragungen von Cloud-Anbietern sind jedoch mit Kosten verbunden, so dass bei den Tests diese Kosten für die Datenbewegung - den Datenaustritt (Repatriation/Egress) aus der Cloud - berücksichtigt werden sollten.
Nicht an den physischen Standort gebunden. Mit einem Cloud-DR-Service können Unternehmen ihre Backup-Einrichtung an einem beliebigen Ort auf der Welt implementieren, der weit vom physischen Standort des Unternehmens entfernt ist. Dies bietet zusätzlichen Schutz vor der Möglichkeit, dass eine Katastrophe alle Server und Geräte im physischen Gebäude gefährden könnte.
Nachteile von Cloud DR
Im Folgenden werden einige Nachteile von Cloud-DR aufgeführt:
- Komplexität. Die Einrichtung und Wartung eines Cloud-Disaster-Recovery kann schwierig sein und erfordert spezielle Fachkenntnisse.
- Internet-Verbindung. Cloud-DR erfordert einen ständigen Internetzugang, was an Orten mit schlechter Internetverbindung schwierig sein kann.
- Migrationskosten. Die Übertragung großer Datenmengen in die Cloud kann teuer sein.
- Bedenken hinsichtlich Sicherheit und Datenschutz. Bei Cloud-DR besteht immer die Gefahr, dass Benutzerdaten in die Hände Unbefugter gelangen, da Cloud-Anbieter Zugang zu den Kundendaten haben. Dies kann manchmal vermieden werden, indem man sich für Zero-Knowledge-Anbieter entscheidet, die ein hohes Maß an Vertraulichkeit wahren.
- Bindung an den Anbieter. Sobald die Daten zu einem Cloud-basierten DR-Dienst migriert sind, kann es für Unternehmen schwierig sein, eine Anbieterbindung zu vermeiden oder zu einem anderen Anbieter zu wechseln.
- Abhängigkeit von Drittanbietern. Wie bei jedem Drittanbieter besteht das Risiko der Abhängigkeit von dessen Service und des Kontrollverlusts über den Disaster-Recovery-Prozess.
Cloud-DR vs. traditionelle DR
Cloud-basierte DR-Dienste und DRaaS-Angebote können Kostenvorteile, Flexibilität und Skalierbarkeit, geografische Redundanz und schnelle Wiederherstellung bieten. Aber Cloud-DR ist möglicherweise nicht für alle Unternehmen oder Umstände geeignet.
Im Folgenden sind einige Situationen aufgeführt, in denen traditionellere DR-Ansätze vorteilhaft oder sogar unerlässlich für das Unternehmen sein können:
- Compliance-Anforderungen. Cloud-Dienste werden zunehmend für die Nutzung in Unternehmen akzeptiert, in denen eine etablierte behördliche Aufsicht erforderlich ist, wie zum Beispiel DSGVO, ISO, HIPAA und PCI DSS. Einige Unternehmen könnten jedoch immer noch mit Verboten konfrontiert werden, wenn sie bestimmte sensible Daten außerhalb eines unmittelbaren Rechenzentrums speichern - oder in einer Ressource oder Infrastruktur, die nicht unter der direkten Kontrolle des Unternehmens steht, wie die Public Cloud, die eine Infrastruktur eines Drittanbieters ist. In diesen Fällen könnte das Unternehmen gezwungen sein, eine lokale oder unternehmenseigene Offsite-DR zu implementieren, um Sicherheits- und Compliance-Anforderungen zu erfüllen.
- Begrenzte Konnektivität. Cloud-Ressourcen und -Dienste hängen von der WAN-Konnektivität wie dem Internet ab. In DR-Anwendungsfällen ist die Konnektivität besonders wichtig, da eine zuverlässige Verbindung mit hoher Bandbreite für schnelle Uploads, Synchronisierung und schnelle Wiederherstellung unerlässlich ist. Obwohl zuverlässige Konnektivität mit hoher Bandbreite in den Städten und den meisten Vorstädten weltweit üblich ist, ist sie kaum universell. Abgelegene Installationen wie Edge-Computing-Standorte existieren oft - zumindest teilweise - wegen der begrenzten Konnektivität, so dass es durchaus sinnvoll sein kann, Datensicherungen, Workload-Snapshots und andere DR-Techniken an lokalen Standorten zu implementieren, an denen die Konnektivität instabil ist. Andernfalls riskiert das Unternehmen Datenverluste und problematische RTOs.
- Optimale Wiederherstellung. Clouds bieten enorme Vorteile, aber die Benutzer sind auf die Infrastruktur, die Architektur und die Tools beschränkt, die der Cloud-Anbieter offeriert. Cloud-DR wird durch den Anbieter und die Service-Level-Vereinbarung eingeschränkt. In manchen Fällen sind die vom Cloud-DR-Anbieter angebotenen RPO- und RTO-Ziele (Recovery Point Objective) für die DR-Bedürfnisse des Unternehmens möglicherweise nicht ausreichend oder der Service-Level wird nicht garantiert. Wenn ein Unternehmen die DR-Plattform im eigenen Haus hat, kann es eine benutzerdefinierte DR-Infrastruktur implementieren und verwalten, die die DR-Leistungsanforderungen am besten garantiert.
- Bestehende Investitionen nutzen. DR-Anforderungen gibt es schon viel länger als Cloud-Services, und ältere DR-Installationen - insbesondere in größeren Unternehmen oder in Unternehmen, in denen sich die Kosten noch amortisieren - lassen sich möglicherweise nicht so leicht durch neuere Cloud-DR-Angebote ersetzen. Das heißt, ein Unternehmen, das bereits das Gebäude, die Server, den Speicher und andere Ressourcen besitzt, ist möglicherweise noch nicht bereit, diese Investitionen aufzugeben. In diesen Fällen kann das Unternehmen die Cloud DR langsamer und vorsichtiger einführen, indem es systematisch Arbeitslasten zum Cloud-DR-Anbieter hinzufügt, um die Technologie routinemäßig zu aktualisieren, anstatt weiteres Kapital zu investieren.
Die Wahl zwischen traditionellem DR und Cloud-DR schließt sich nicht gegenseitig aus. Unternehmen stellen möglicherweise fest, dass herkömmliche DR für einige Arbeitslasten am besten geeignet ist, während Cloud DR für andere Arbeitslasten sehr gut funktionieren kann. Beide Alternativen können miteinander kombiniert werden, um den besten DR-Schutz für die einzelnen Arbeitslasten des Unternehmens zu bieten.
Cloud Disaster Recovery und Business Continuity
Die Begriffe Business Continuity und Disaster Recovery - zusammen BC/DR bezeichnet - beschreiben eine Sammlung von Verfahren und Methoden, die zur Unterstützung der Wiederherstellung eines Unternehmens nach einer Katastrophe und der Fortsetzung oder Wiederaufnahme der regulären Geschäftsaktivitäten eingesetzt werden können.
Geschäftskontinuität
BC bezieht sich im Wesentlichen auf die Pläne und Technologien, die eingesetzt werden, um sicherzustellen, dass der Geschäftsbetrieb nach einem Zwischenfall, der den Geschäftsbetrieb stören könnte, mit minimalen Verzögerungen und Schwierigkeiten wieder aufgenommen werden kann.
Nach dieser Definition ist BC ein weites Themenfeld, das eine Vielzahl von Faktoren umfasst, darunter Sicherheit, Unternehmensführung und Compliance, Risikobewertung und -management, Änderungsmanagement sowie Katastrophenvorsorge und Disaster Recovery. So können BC-Maßnahmen beispielsweise ein breites Spektrum von Katastrophen wie Epidemien, Erdbeben, Überschwemmungen, Brände, Serviceausfälle, physische oder Cyberangriffe, Diebstahl, Sabotage und andere potenzielle Vorfälle berücksichtigen und für diese planen.
Die BC-Planung beginnt in der Regel mit der Risikoerkennung und -bewertung: Für welche Risiken plant das Unternehmen, und wie wahrscheinlich sind diese Risiken? Sobald ein Risiko bekannt ist, können die Unternehmensleiter einen Plan entwerfen, um das Risiko anzugehen und zu mindern. Der Plan wird budgetiert, beschafft und umgesetzt. Nach der Umsetzung kann der Plan getestet, gewartet und bei Bedarf angepasst werden.
Disaster Recovery
Das Disaster Recovery, zu der auch das Cloud-basierte DR gehört, ist Teil eines umfassenderen BC-Konzepts. Sie spielt in der Regel eine zentrale Rolle in vielen Bereichen der BC-Planung, zum Beispiel bei Überschwemmungen, Erdbeben und Cyberangriffen. Wenn das Unternehmen beispielsweise in einem bekannten Erdbebengebiet tätig ist, stellt das Risiko von Erdbebenschäden ein potenzielles Risiko dar, das analysiert werden muss, um einen Plan zur Schadensbegrenzung zu erstellen. Ein Teil des Plans zur Risikominderung könnte darin bestehen, eine Cloud-DR in Form eines zweiten heißen Standorts in einer erdbebenfreien Region einzuführen.
Der BC-Plan würde sich also auf die Redundanz des Cloud-DR-Dienstes stützen, um den Betrieb nahtlos fortzusetzen, wenn das primäre Rechenzentrum nicht mehr verfügbar ist, und so den Geschäftsbetrieb aufrechtzuerhalten. In diesem Beispiel wäre das DR nur ein kleiner Teil des Business-Continuity-Plans, wobei die zusätzliche Planung die entsprechenden Änderungen der Arbeitsabläufe und Arbeitsverantwortlichkeiten zur Aufrechterhaltung des normalen Betriebs wie die Annahme von Bestellungen, den Versand von Produkten und die Bearbeitung von Rechnungen sowie die Arbeit zur Wiederherstellung der betroffenen Ressourcen detailliert beschreibt.
Erstellung eines Cloud-basierten DR-Plans
Die Erstellung eines Cloud-DR-Plans ist praktisch identisch mit herkömmlichen lokalen oder standortfernen Disaster-Recovery-Plänen. Der Hauptunterschied zwischen Cloud-DR und traditionelleren DR-Ansätzen besteht in der Verwendung von Cloud-Technologien und DRaaS zur Unterstützung einer geeigneten Implementierung. Anstatt beispielsweise einen wichtigen Datensatz auf einer anderen Festplatte in einem anderen lokalen Server zu sichern, würde die Cloud-basierte DR den Datensatz in einer Cloud-Ressource wie einem Amazon-S3-Bucket sichern. Ein weiteres Beispiel: Anstatt einen wichtigen Server als warme VM in einer Colocation-Einrichtung zu betreiben, könnte die warme VM in Microsoft Azure oder über eine beliebige Anzahl verschiedener DRaaS-Anbieter betrieben werden. Cloud-DR ändert also nichts an der grundlegenden Notwendigkeit oder den Schritten zur Implementierung von DR, sondern bietet vielmehr eine neue Reihe von praktischen Tools und Plattformen für DR-Ziele.
Es gibt drei grundlegende Komponenten eines Cloud-basierten DR-Plans: Analyse, Implementierung und Test.
Analyse. Jeder Notfallplan beginnt mit einer detaillierten Risikobewertung und -analyse, die im Wesentlichen die aktuelle IT-Infrastruktur und die Arbeitsabläufe untersucht und dann die potenziellen Katastrophen berücksichtigt, denen ein Unternehmen wahrscheinlich ausgesetzt ist. Ziel ist es, potenzielle Schwachstellen und Katastrophen zu ermitteln - von Einbruchsversuchen und Diebstahl bis hin zu Erdbeben und Überschwemmungen - und dann zu bewerten, ob die IT-Infrastruktur diesen Herausforderungen gewachsen ist.
Eine Analyse kann Unternehmen dabei helfen, die kritischsten Geschäftsfunktionen und IT-Elemente zu ermitteln und die potenziellen finanziellen Auswirkungen eines Katastrophenereignisses vorherzusagen. Die Analyse kann auch dabei helfen, RPOs und RTOs für Infrastruktur und Arbeitslasten zu bestimmen. Auf der Grundlage dieser Festlegungen kann ein Unternehmen fundiertere Entscheidungen darüber treffen, welche Workloads geschützt werden sollen, wie diese Workloads geschützt werden sollen und wo mehr Investitionen erforderlich sind, um diese Ziele zu erreichen.
Implementierung. Auf die Analyse folgt in der Regel eine sorgfältige Implementierung, bei der die Schritte für Prävention, Bereitschaft, Reaktion und Wiederherstellung detailliert beschrieben werden. Unter Prävention versteht man die Bemühungen, mögliche Bedrohungen zu reduzieren und Schwachstellen zu beseitigen. Dazu gehören beispielsweise Mitarbeiterschulungen zum Thema Social Engineering und regelmäßige Aktualisierungen des Betriebssystems, um die Sicherheit und Stabilität zu gewährleisten. Bei der Vorbereitung geht es darum, die notwendige Reaktion zu skizzieren, wer was im Katastrophenfall tut. Dies ist im Wesentlichen eine Frage der Dokumentation. Die Reaktionsdokumentation beschreibt die Technologien und Strategien, die im Katastrophenfall eingesetzt werden sollen. Diese Vorbereitung wird mit der Implementierung der entsprechenden Technologien abgestimmt, zum Beispiel der Wiederherstellung eines in der Cloud gesicherten Datensatzes oder einer Server-VM. Die Wiederherstellung beschreibt die Erfolgsbedingungen für die Reaktion und die Schritte, die zur Minderung möglicher Schäden für das Unternehmen beitragen.
Ziel ist es, festzulegen, wie im Falle einer bestimmten Katastrophe vorgegangen werden soll, und der Plan wird mit der Implementierung von Technologien und Diensten abgestimmt, die für die Bewältigung der spezifischen Umstände entwickelt wurden. In diesem Fall umfasst der Plan auch Cloud-basierte Technologien und Dienste.
Testen. Jeder Notfallplan muss regelmäßig getestet und aktualisiert werden, um sicherzustellen, dass die IT-Mitarbeiter in der Lage sind, die entsprechenden Maßnahmen und Wiederherstellung erfolgreich und rechtzeitig zu implementieren, und dass die Wiederherstellung innerhalb eines für das Unternehmen akzeptablen Zeitrahmens erfolgt. Durch das Testen können Lücken oder Unstimmigkeiten in der Implementierung aufgedeckt werden, so dass Unternehmen den Notfallplan korrigieren und aktualisieren können, bevor eine echte Katastrophe eintritt.
Cloud-Disaster-Recovery-Anbieter
Im Kern ist die Cloud-DR eine Form der Offsite-DR. Eine Offsite-Strategie ermöglicht es Unternehmen, sich gegen Vorfälle innerhalb der lokalen Infrastruktur abzusichern und dann entweder die Ressourcen in der lokalen Infrastruktur wiederherzustellen oder die Ressourcen direkt beim DR-Anbieter weiterlaufen zu lassen. Infolgedessen sind zahlreiche Anbieter am Markt, die Offsite-DR-Funktionen anbieten.
Der logischste Weg für Cloud-DR führt über die großen Cloud Service Provider. AWS bietet zum Beispiel den CloudEndure Disaster Recovery Service, Microsoft Azure bietet Azure Site Recovery und Google Cloud Platform bietet Cloud Storage und Persistent Disk Optionen zum Schutz wertvoller Daten. DR-Infrastrukturen für große Unternehmensumgebungen können bei allen drei großen Cloud-Anbietern eingerichtet werden.
Neben den Public Clouds bietet eine Reihe von DR-Anbietern auch DRaaS-Produkte an, die im Wesentlichen Zugang zu dedizierten Clouds für DR-Aufgaben bieten.
Zu den DRaaS-Anbietern und ihren Produkten gehören die folgenden:
- Bluelock
- Expedient
- IBM Cloud Disaster Recovery
- Iland
- Recovery Point Systems
- Sungard Availability Services
- TierPoint
- VMware Site Recovery Manager
Darüber hinaus haben jetzt auch traditionellere Backup-Anbieter DRaaS-Angebote:
- Acronis
- Arcserve Unified Data Protection
- Carbonite
- Databarracks
- Datto
- Unitrends
- Zerto
Angesichts der Vielzahl von DRaaS-Angeboten ist es für Unternehmen wichtig, jedes potenzielle Angebot auf Faktoren wie Zuverlässigkeit, wiederkehrende Kosten, Benutzerfreundlichkeit und Anbieter-Support zu prüfen. Jede DR-Plattform muss regelmäßig aktualisiert und getestet werden, um sicherzustellen, dass DR verfügbar ist und wie erwartet funktioniert.







