Edge Computing

Edge Computing ist eine verteilte IT-Architektur, bei der Kundendaten an der Peripherie des Netzes verarbeitet werden, so nah wie möglich an der Ursprungsquelle.
Daten sind das Lebenselixier moderner Unternehmen. Sie bieten wertvolle Einblicke in das Geschäft und unterstützen die Echtzeitkontrolle über wichtige Geschäftsprozesse und -abläufe. Die Unternehmen von heute werden von einem Meer von Daten überflutet, und riesige Datenmengen können routinemäßig von Sensoren und IoT-Geräten erfasst werden, die in Echtzeit an entfernten Standorten und in unwirtlichen Betriebsumgebungen fast überall auf der Welt arbeiten.
Aber diese virtuelle Datenflut verändert auch die Art und Weise, wie Unternehmen mit der Datenverarbeitung umgehen. Das herkömmliche Rechenparadigma, das auf einem zentralisierten Rechenzentrum und dem alltäglichen Internetaufbaut, ist nicht gut geeignet, um endlos wachsende Ströme von realen Daten zu bewegen. Bandbreitenbeschränkungen, Latenzprobleme und unvorhersehbare Netzwerkunterbrechungen können solche Bemühungen beeinträchtigen. Unternehmen reagieren auf diese Datenherausforderungen mit dem Einsatz von Edge-Computing-Architekturen.
Vereinfacht ausgedrückt, verlagert Edge Computing einen Teil der Speicher- und Rechenressourcen aus dem zentralen Rechenzentrum heraus und näher an die Datenquelle selbst. Anstatt Rohdaten zur Verarbeitung und Analyse an ein zentrales Rechenzentrum zu übermitteln, wird diese Arbeit stattdessen dort durchgeführt, wo die Daten tatsächlich erzeugt werden - sei es in einem Einzelhandelsgeschäft, einer Fabrikhalle, einem weitläufigen Versorgungsunternehmen oder in einer intelligenten Stadt (Smart City). Nur das Ergebnis dieser Datenverarbeitung am Rande des Netzwerks, wie zum Beispiel Geschäftseinblicke in Echtzeit, Vorhersagen zur Gerätewartung oder andere umsetzbare Antworten, wird zur Überprüfung und für andere menschliche Interaktionen an das Hauptdatenzentrum zurückgeschickt.
Somit verändert Edge Computing die IT- und Unternehmensinformatik. Werfen Sie einen umfassenden Blick darauf, was Edge Computing ist, wie es funktioniert, welchen Einfluss die Cloud hat, welche Anwendungsfälle es gibt, welche Kompromisse möglich sind und was bei der Implementierung zu beachten ist.
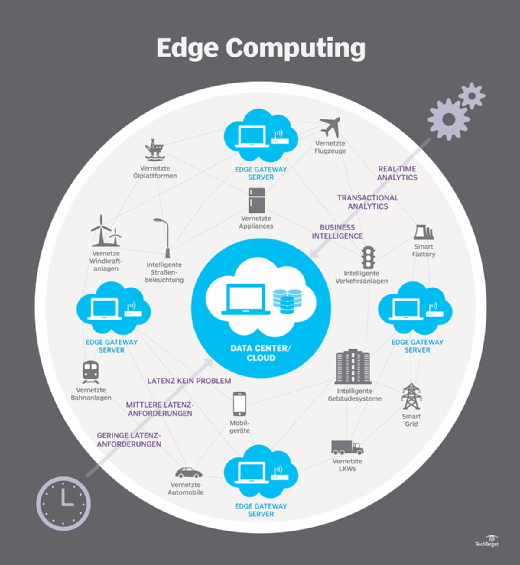
Wie funktioniert Edge Computing?
Edge Computing ist vor allem eine Frage des Standorts. Beim herkömmlichen Unternehmens-Computing werden die Daten an einem Client-Endpunkt, beispielsweise dem Computer eines Benutzers, erzeugt. Diese Daten werden über ein WAN, zum Beispiel das Internet, durch das Unternehmens-LAN übertragen, wo die Daten gespeichert und von einer Unternehmensanwendung verarbeitet werden. Die Ergebnisse dieser Arbeit werden dann zurück an den Client-Endpunkt übermittelt. Dies ist nach wie vor ein bewährter Ansatz des Client-Server-Computing für die meisten typischen Geschäftsanwendungen.
Doch die Zahl der mit dem Internet verbundenen Geräte und die von diesen Geräten erzeugten und von Unternehmen genutzten Datenmengen wachsen viel zu schnell, als dass herkömmliche Rechenzentrumsinfrastrukturen sie bewältigen könnten. Gartner prognostiziert, dass bis 2025 75 Prozent der von Unternehmen generierten Daten außerhalb zentraler Rechenzentren erzeugt werden. Die Aussicht, so viele Daten in Situationen zu verschieben, die oft zeit- oder störungsanfällig sind, stellt eine unglaubliche Belastung für das globale Internet dar, das selbst oft überlastet ist und Unterbrechungen erleidet.
Daher haben IT-Architekten den Schwerpunkt vom zentralen Rechenzentrum auf den logischen Rand (Edge) der Infrastruktur verlagert, indem sie Speicher- und Rechenressourcen aus dem Rechenzentrum dorthin verlagert haben, wo die Daten erzeugt werden. Das Prinzip ist simpel: Wenn man die Daten nicht näher zum Rechenzentrum bringen kann, muss man das Rechenzentrum näher zu den Daten bringen. Das Konzept des Edge Computing ist nicht neu und hat seine Wurzeln in der jahrzehntealten Idee des Remote Computing - wie zum Beispiel Remote Offices und Zweigstellen -, bei der es zuverlässiger und effizienter war, Rechenressourcen am gewünschten Ort zu platzieren, anstatt sich auf einen einzigen zentralen Standort zu verlassen.
Beim Edge Computing werden Storage und Server dort platziert, wo sich die Daten befinden, wobei oft nicht viel mehr als ein Teil des Racks im Remote-LAN benötigt wird, um die Daten lokal zu erfassen und zu verarbeiten. In vielen Fällen werden die Datenverarbeitungsgeräte in abgeschirmten oder speziellen Gehäusen untergebracht, um sie vor extremen Temperaturen, Feuchtigkeit und anderen Umweltbedingungen zu schützen. Die Verarbeitung umfasst häufig die Normalisierung und Analyse des Datenstroms, um Geschäftsinformationen zu ermitteln, und nur die Ergebnisse der Analyse werden an das Hauptrechenzentrum zurückgesendet.
Das Konzept der Business Intelligence kann sehr unterschiedlich sein. Einige Beispiele sind Einzelhandelsumgebungen, in denen die Videoüberwachung des Ausstellungsraums mit aktuellen Verkaufsdaten kombiniert werden kann, um die wünschenswerteste Produktkonfiguration oder Kundennachfrage zu ermitteln. Andere Beispiele umfassen prädiktive Analysen, die die Wartung und Reparatur von Geräten anleiten können, bevor es zu tatsächlichen Defekten oder Ausfällen kommt. Wiederum andere Beispiele sind häufig auf Versorgungsunternehmen ausgerichtet, wie bei der Wasseraufbereitung oder der Stromerzeugung, um sicherzustellen, dass die Anlagen ordnungsgemäß funktionieren und die Qualität der Leistung erhalten bleibt.
Edge- vs. Cloud- vs. Fog-Computing
Edge Computing ist eng mit den Konzepten des Cloud Computing und des Fog Computing verbunden. Obwohl es einige Überschneidungen zwischen diesen Konzepten gibt, sind sie nicht dasselbe und sollten im Allgemeinen nicht austauschbar verwendet werden. Es ist hilfreich, die Konzepte zu vergleichen und ihre Unterschiede zu verstehen.
Einer der einfachsten Wege, die Unterschiede zwischen Edge-, Cloud- und Fog-Computing zu verstehen, besteht darin, ihre Gemeinsamkeiten hervorzuheben: Alle drei Konzepte beziehen sich auf verteiltes Computing und konzentrieren sich auf die physische Bereitstellung von Rechen- und Speicherressourcen im Verhältnis zu den erzeugten Daten. Der Unterschied besteht darin, wo sich diese Ressourcen befinden.
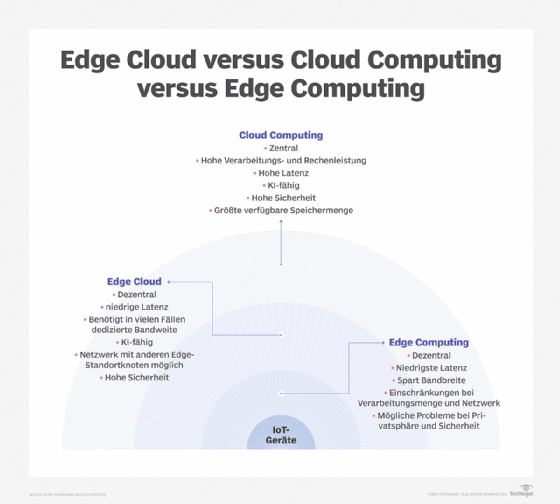
Edge. Edge Computing ist die Bereitstellung von Rechen- und Speicherressourcen an dem Ort, an dem die Daten produziert werden. Im Idealfall befinden sich die Rechen- und Speicherressourcen am selben Punkt wie die Datenquelle am Netzwerkrand. So könnte beispielsweise ein kleines Gehäuse mit mehreren Servern und etwas Speicherplatz auf einer Windturbine installiert werden, um Daten zu sammeln und zu verarbeiten, die von Sensoren in der Turbine selbst erzeugt werden. Ein anderes Beispiel ist ein Bahnhof, in dem eine bescheidene Menge an Rechen- und Speicherkapazität installiert werden könnte, um die unzähligen Sensordaten von Gleisen und Schienenverkehr zu erfassen und zu verarbeiten. Die Ergebnisse einer solchen Verarbeitung können dann an ein anderes Rechenzentrum zurückgesendet werden, wo sie von Menschen überprüft, archiviert und mit anderen Datenergebnissen für umfassendere Analysen zusammengeführt werden.
Cloud. Cloud Computing ist ein riesiger, hoch skalierbarer Einsatz von Rechen- und Speicherressourcen an einem von mehreren verteilten globalen Standorten (Regionen). Cloud-Anbieter bieten auch eine Reihe von vorgefertigten Diensten für den IoT-Betrieb an, was die Cloud zu einer bevorzugten zentralisierten Plattform für IoT-Bereitstellungen macht. Doch auch wenn Cloud Computing mehr als genug Ressourcen und Dienste für komplexe Analysen bietet, kann die nächstgelegene regionale Cloud-Einrichtung immer noch Hunderte von Kilometern von dem Punkt entfernt sein, an dem die Daten gesammelt werden, und die Verbindungen sind auf die gleiche launische Internetkonnektivität angewiesen, die auch traditionelle Rechenzentren unterstützt. In der Praxis ist das Cloud Computing eine Alternative - oder manchmal auch eine Ergänzung - zu herkömmlichen Rechenzentren. Die Cloud kann zentralisierte Datenverarbeitung viel näher an eine Datenquelle bringen, aber nicht an den Netzwerkrand.
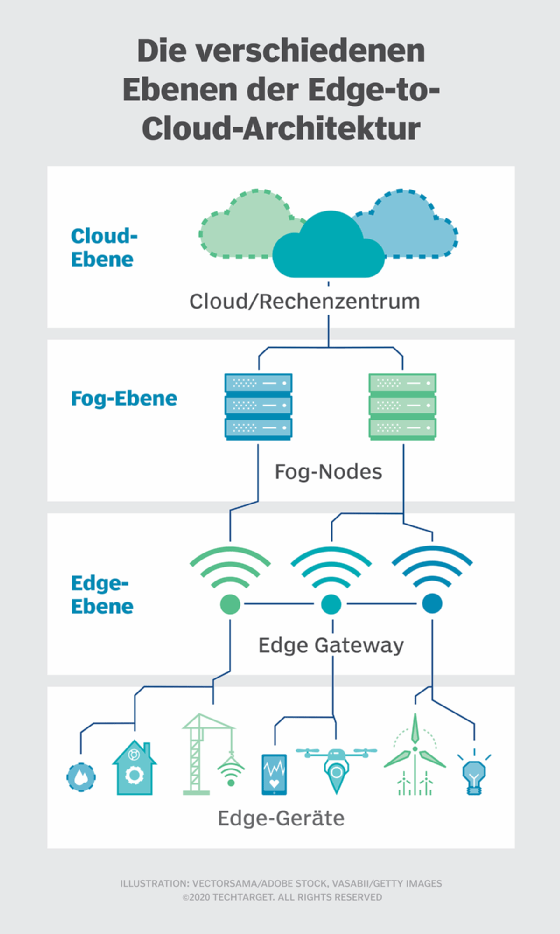
Fog. Aber die Wahl der Rechen- und Speicherbereitstellung ist nicht auf die Cloud oder den Netzwerkrand beschränkt. Ein Cloud-Rechenzentrum könnte zu weit entfernt sein, aber der Edge-Einsatz könnte einfach zu ressourcenbegrenzt oder physisch verstreut sein, um ein striktes Edge-Computing sinnvoll zu machen. In diesem Fall kann das Konzept des Fog Computing helfen. Fog Computing geht in der Regel einen Schritt zurück und stellt Rechen- und Speicherressourcen „innerhalb“ der Daten, aber nicht unbedingt „an“ den Daten bereit.
Fog-Computing-Umgebungen können verwirrende Mengen an Sensor- oder IoT-Daten erzeugen, die über ausgedehnte physische Bereiche generiert werden, die einfach zu groß sind, um ein Edge zu definieren. Beispiele hierfür sind intelligente Gebäude (Smart Buildings), intelligente Städte (Smart Cities) oder sogar intelligente Versorgungsnetze (Smart Grid). Stellen Sie sich eine intelligente Stadt vor, in der Daten zur Verfolgung, Analyse und Optimierung des öffentlichen Nahverkehrssystems, der städtischen Versorgungsbetriebe und der städtischen Dienstleistungen sowie zur Steuerung der langfristigen Stadtplanung verwendet werden können. Ein einziger Edge-Einsatz reicht nicht aus, um eine solche Last zu bewältigen. Daher kann Fog Computing eine Reihe von Fog-Node-Einsätzen innerhalb der Umgebung betreiben, um Daten zu sammeln, zu verarbeiten und zu analysieren.
Es ist wichtig zu betonen, dass Fog Computing und Edge Computing eine fast identische Definition und Architektur haben und die Begriffe manchmal sogar unter Technologieexperten austauschbar verwendet werden.
Warum ist Edge Computing wichtig?
Rechenaufgaben erfordern geeignete Architekturen, und die Architektur, die für eine Art von Rechenaufgabe geeignet ist, passt nicht unbedingt für alle Arten von Rechenaufgaben. Edge Computing hat sich als praktikable und wichtige Architektur herauskristallisiert, die verteiltes Computing unterstützt, um Rechen- und Speicherressourcen näher an der Datenquelle - idealerweise am selben physischen Standort - bereitzustellen. Generell sind Modelle für verteiltes Computing nicht neu, und die Konzepte von Remote Offices, Zweigstellen, Colocation von Rechenzentren und Cloud Computing haben eine lange und bewährte Erfolgsgeschichte.
Die Dezentralisierung kann jedoch eine Herausforderung darstellen, da sie ein hohes Maß an Überwachung und Kontrolle erfordert, das bei der Abkehr von einem herkömmlichen zentralisierten Computermodell leicht übersehen wird. Edge Computing hat an Bedeutung gewonnen, weil es eine effektive Lösung für die aufkommenden Netzwerkprobleme bietet, die mit der Übertragung enormer Datenmengen verbunden sind, die die heutigen Unternehmen produzieren und verbrauchen. Es ist nicht nur ein Problem der Menge. Es ist auch eine Frage der Zeit: Anwendungen sind auf Verarbeitungen und Antworten angewiesen, die zunehmend zeitkritisch sind.
Denken Sie nur an das Aufkommen von selbstfahrenden Autos. Sie werden auf intelligente Verkehrssteuerungssignale angewiesen sein. Autos und Verkehrssteuerungen müssen Daten in Echtzeit erzeugen, analysieren und austauschen. Multipliziert man diese Anforderung mit einer großen Anzahl autonomer Fahrzeuge, wird das Ausmaß der potenziellen Probleme deutlich. Dies erfordert ein schnelles und reaktionsschnelles Netzwerk. Edge und Fog Computing befasst sich mit drei wesentlichen Netzwerkbeschränkungen: Bandbreite, Latenz und Überlastung (Congestion) oder Zuverlässigkeit.
- Die Bandbreite ist die Datenmenge, die ein Netz in einem bestimmten Zeitraum übertragen kann, normalerweise ausgedrückt in Bits pro Sekunde. Alle Netze haben eine begrenzte Bandbreite, wobei die Grenzen bei der drahtlosen Kommunikation noch enger gefasst sind. Das bedeutet, dass die Datenmenge - oder die Anzahl der Geräte -, die Daten über das Netzwerk übertragen können, begrenzt ist. Obwohl es möglich ist, die Netzwerkbandbreite zu erhöhen, um mehr Geräte und Daten unterzubringen, können die Kosten erheblich sein, es gibt immer noch (höhere) endliche Grenzen und andere Probleme werden dadurch nicht gelöst.
- Die Latenzzeit ist die Zeit, die benötigt wird, um Daten zwischen zwei Punkten in einem Netz zu übertragen. Obwohl die Kommunikation im Idealfall mit Lichtgeschwindigkeit erfolgt, können große physische Entfernungen in Verbindung mit Netzwerküberlastungen oder -ausfällen die Datenübertragung im Netzwerk verzögern. Dadurch verzögern sich Analyse- und Entscheidungsfindungsprozesse, und die Fähigkeit eines Systems, in Echtzeit zu reagieren, wird eingeschränkt. Im Beispiel des autonomen Fahrzeugs kostete dies sogar Menschenleben.
- Überlastung (Congestion). Das Internet ist im Grunde ein globales „Netz der Netze“. Obwohl es sich so entwickelt hat, dass es einen guten allgemeinen Datenaustausch für die meisten alltäglichen Datenverarbeitungsaufgaben bietet - wie zum Beispiel den Austausch von Dateien oder grundlegendes Streaming-, kann die Datenmenge, die mit Dutzenden von Milliarden von Geräten verbunden ist, das Internet überfordern, was zu einer starken Überlastung führt und zeitaufwändige Datenübertragungen erzwingt. In anderen Fällen können Netzausfälle die Überlastung noch verschlimmern und sogar die Kommunikation mit einigen Internetnutzern ganz unterbrechen - was das Internet der Dinge bei Ausfällen unbrauchbar macht.
Durch die Bereitstellung von Servern und Speicherplatz dort, wo die Daten generiert werden, kann Edge Computing viele Geräte über ein viel kleineres und effizienteres LAN betreiben, in dem ausreichend Bandbreite ausschließlich von lokalen datenerzeugenden Geräten genutzt wird, so dass Latenzzeiten und Überlastungen praktisch nicht vorkommen. Lokaler Speicher sammelt und schützt die Rohdaten, während lokale Server wesentliche Edge-Analysen durchführen können - oder zumindest die Daten vorverarbeiten und reduzieren -, um Entscheidungen in Echtzeit zu treffen, bevor die Ergebnisse oder nur die wesentlichen Daten an die Cloud oder das zentrale Rechenzentrum gesendet werden.
Anwendungsfälle und Beispiele für Edge Computing
Im Prinzip werden Edge-Computing-Techniken verwendet, um Daten direkt am oder in der Nähe des Netzwerkrands zu sammeln, zu filtern, zu verarbeiten und zu analysieren. Dabei handelt es sich um ein leistungsfähiges Mittel zur Nutzung von Daten, die nicht zuerst an einen zentralen Standort verschoben werden können - in der Regel, weil die schiere Menge der Daten eine solche Verschiebung kostspielig oder technologisch unpraktisch macht oder weil sie anderweitig gegen Compliance-Verpflichtungen wie die Datenhoheit verstoßen könnte. Diese Definition hat unzählige Beispiele und Anwendungsfälle aus der Praxis hervorgebracht:
- Fertigung (Manufacturing). Ein Industrieunternehmen setzt Edge Computing zur Überwachung der Fertigung ein und ermöglicht so Echtzeitanalysen und maschinelles Lernen am Rande der Fertigung, um Produktionsfehler zu finden und die Qualität der Produktherstellung zu verbessern. Edge Computing unterstützt das Hinzufügen von Umgebungssensoren in der gesamten Produktionsanlage, die einen Einblick in die Montage und Lagerung der einzelnen Produktkomponenten geben - und wie lange die Komponenten auf Lager bleiben. Der Hersteller kann nun schnellere und präzisere Geschäftsentscheidungen in Bezug auf die Fabrikanlage und den Fertigungsbetrieb treffen.
- Nehmen wir ein Unternehmen, das Pflanzen in Innenräumen ohne Sonnenlicht, Erde oder Pestizide anbaut. Das Verfahren verkürzt die Wachstumszeiten um mehr als 60 Prozent. Mithilfe von Sensoren kann das Unternehmen den Wasserverbrauch und die Nährstoffdichte verfolgen und die optimale Ernte bestimmen. Es werden Daten gesammelt und analysiert, um die Auswirkungen von Umweltfaktoren zu ermitteln und die Algorithmen für den Pflanzenanbau kontinuierlich zu verbessern und sicherzustellen, dass die Pflanzen in bester Verfassung geerntet werden.
- Edge Computing kann zur Optimierung der Netzwerkleistung beitragen, indem es die Leistung für Benutzer im gesamten Internet misst und dann Analysen einsetzt, um den zuverlässigsten Netzwerkpfad mit niedrigen Latenzzeiten für den Datenverkehr jedes Benutzers zu ermitteln. Mit Edge Computing wird der Datenverkehr über das Netzwerk „gelenkt“, um eine optimale Leistung für den zeitkritischen Datenverkehr zu erzielen.
- Sicherheit am Arbeitsplatz. Edge Computing kann Daten von Vor-Ort-Kameras, Sicherheitsgeräten der Mitarbeiter und verschiedenen anderen Sensoren kombinieren und analysieren, um Unternehmen dabei zu helfen, die Bedingungen am Arbeitsplatz zu überwachen oder sicherzustellen, dass die Mitarbeiter die festgelegten Sicherheitsprotokolle befolgen - insbesondere, wenn der Arbeitsplatz abgelegen oder ungewöhnlich gefährlich ist, wie zum Beispiel auf Baustellen oder Ölplattformen.
- Verbesserte Gesundheitsversorgung. Im Gesundheitswesen ist die Menge an Patientendaten, die von Geräten, Sensoren und anderen medizinischen Geräten erfasst werden, dramatisch gestiegen. Diese enorme Datenmenge erfordert Edge Computing, um durch Automatisierung und maschinelles Lernen auf die Daten zuzugreifen, „normale“ Daten zu ignorieren und problematische Daten zu identifizieren, damit Ärzte sofort Maßnahmen ergreifen können, um Patienten in Echtzeit vor gesundheitlichen Zwischenfällen zu schützen.
- Autonome Fahrzeuge benötigen und produzieren täglich zwischen 5 TB und 20 TB, wobei sie Informationen über Standort, Geschwindigkeit, Fahrzeugzustand, Straßenbedingungen, Verkehrsbedingungen und andere Fahrzeuge sammeln. Und diese Daten müssen in Echtzeit gesammelt und analysiert werden, während das Fahrzeug in Bewegung ist. Dies erfordert eine umfangreiche Datenverarbeitung an Bord - jedes autonome Fahrzeug wird zu einem „Edge“. Darüber hinaus können die Daten Behörden und Unternehmen dabei helfen, Fahrzeugflotten auf der Grundlage der tatsächlichen Bedingungen vor Ort zu verwalten.
- Einzelhandelsunternehmen können ebenfalls enorme Datenmengen aus der Überwachung, der Bestandsverfolgung, den Verkaufsdaten und anderen Geschäftsdetails in Echtzeit erzeugen. Edge Computing kann dabei helfen, diese vielfältigen Daten zu analysieren und Geschäftschancen zu erkennen, wie zum Beispiel eine wirksame Endverpackung oder Kampagne, Umsatzprognosen und die Optimierung von Lieferantenbestellungen. Da Einzelhandelsgeschäfte in lokalen Umgebungen sehr unterschiedlich sein können, kann Edge Computing eine effektive Lösung für die lokale Verarbeitung in jeder Filiale sein.
Was sind die Vorteile von Edge Computing?
Edge Computing ist eine Lösung für wichtige infrastrukturelle Herausforderungen, wie beispielsweise Bandbreitenbeschränkungen, übermäßige Latenzzeiten und Netzwerküberlastungen, aber es gibt mehrere potenzielle zusätzliche Vorteile des Edge Computing, die diesen Ansatz auch in anderen Situationen interessant machen können.
Autonomie. Edge Computing ist dort nützlich, wo die Konnektivität unzuverlässig oder die Bandbreite aufgrund der Umgebungsmerkmale des Standorts eingeschränkt ist. Beispiele hierfür sind Ölplattformen, Schiffe auf See, abgelegene Bauernhöfe oder andere abgelegene Orte wie der Regenwälder oder Wüsten. Edge Computing erledigt die Rechenarbeit vor Ort - manchmal auf dem Edge-Gerät selbst - wie zum Beispiel Wasserqualitätssensoren an Wasseraufbereitungsanlagen in abgelegenen Dörfern, und kann Daten speichern, die nur dann an eine zentrale Stelle übertragen werden, wenn eine Verbindung verfügbar ist. Durch die Verarbeitung der Daten vor Ort kann die zu übertragende Datenmenge erheblich reduziert werden, so dass weitaus weniger Bandbreite oder Verbindungszeit benötigt wird, als es sonst der Fall wäre.
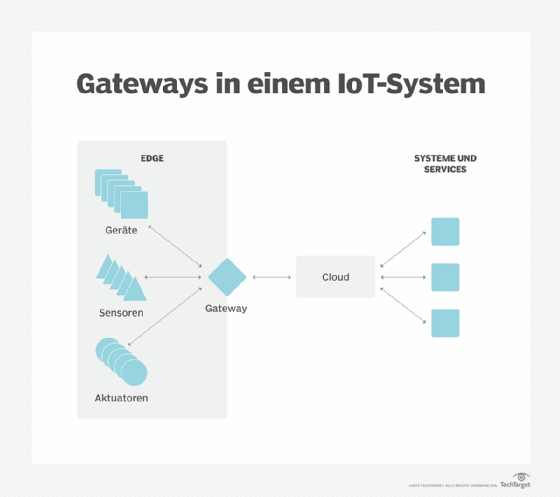
Datenhoheit (Data Sovereignty). Die Übertragung großer Datenmengen ist nicht nur ein technisches Problem. Die Reise der Daten über nationale und regionale Grenzen hinweg kann zusätzliche Probleme in Bezug auf Datensicherheit, Datenschutz und andere rechtliche Fragen aufwerfen. Edge Computing kann eingesetzt werden, um Daten nahe an ihrer Quelle und innerhalb der Grenzen der geltenden Gesetze zur Datensouveränität zu halten, wie beispielsweise der DSGVO der Europäischen Union, die festlegt, wie Daten gespeichert, verarbeitet und offengelegt werden sollten. Auf diese Weise können Rohdaten lokal verarbeitet werden, wobei alle sensiblen Daten unkenntlich gemacht oder gesichert werden, bevor sie an die Cloud oder das primäre Datenzentrum gesendet werden, das sich in anderen Ländern befinden kann.
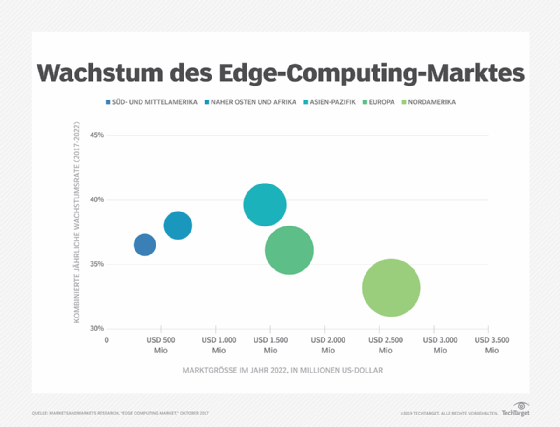
Edge Security. Schließlich bietet das Edge-Computing eine weitere Möglichkeit, die Datensicherheit zu implementieren und zu gewährleisten. Obwohl Cloud-Anbieter über IoT-Dienste verfügen und auf komplexe Analysen spezialisiert sind, machen sich Unternehmen nach wie vor Sorgen über die Sicherheit der Daten, sobald sie den Edge-Bereich verlassen und zurück in die Cloud oder das Rechenzentrum gelangen. Durch die Implementierung von Computing am Edge können alle Daten, die das Netzwerk zurück zur Cloud oder zum Rechenzentrum durchlaufen, durch Verschlüsselung gesichert werden, und die Edge-Implementierung selbst kann gegen Hacker und andere bösartige Aktivitäten gehärtet werden - selbst wenn die Sicherheit auf IoT-Geräten begrenzt bleibt.
Herausforderungen des Edge-Computing
Obwohl Edge Computing das Potenzial hat, in einer Vielzahl von Anwendungsfällen überzeugende Vorteile zu bieten, ist die Technologie bei weitem nicht ohne Einschränkungen. Abgesehen von den traditionellen Problemen der Netzwerkbeschränkungen gibt es mehrere wichtige Überlegungen, die die Einführung von Edge Computing beeinflussen können:
- Begrenzte Möglichkeiten. Ein Teil der Faszination, die Cloud Computing auf Edge oder Fog Computing ausübt, ist die Vielfalt und der Umfang der Ressourcen und Dienste. Der Einsatz einer Infrastruktur am Edge kann effektiv sein, aber der Umfang und der Zweck des Edge-Einsatzes müssen klar definiert sein - selbst ein umfangreicher Edge-Computing-Einsatz dient einem bestimmten Zweck in einem vorher festgelegten Umfang unter Verwendung begrenzter Ressourcen und weniger Dienste.

- Konnektivität. Edge Computing überwindet typische Netzwerkbeschränkungen, aber selbst die unproblematischste Edge-Implementierung erfordert ein Mindestmaß an Konnektivität. Es ist von entscheidender Bedeutung, eine Edge-Implementierung zu entwerfen, die schlechte oder unregelmäßige Konnektivität ausgleicht und berücksichtigt, was am Edge passiert, wenn die Konnektivität verloren geht. Autonomie, künstliche Intelligenz und eine zuverlässige Ausfallplanung bei Konnektivitätsproblemen sind für ein erfolgreiches Edge-Computing unerlässlich.
- IoT-Geräte sind notorisch unsicher, daher ist es von entscheidender Bedeutung, eine Edge-Computing-Bereitstellung zu entwerfen, bei der eine ordnungsgemäße Geräteverwaltung, wie zum Beispiel die Durchsetzung von Konfigurationsrichtlinien, sowie die Sicherheit der Rechen- und Speicherressourcen - einschließlich Faktoren wie Software-Patches und -Updates - im Vordergrund steht, mit besonderem Augenmerk auf die Verschlüsselung der Daten im Ruhezustand und während der Übertragung. IoT-Dienste von großen Cloud-Anbietern umfassen eine sichere Kommunikation, was jedoch nicht automatisch der Fall ist, wenn eine Edge-Site von Grund auf neu aufgebaut wird.
- Lebenszyklen von Daten. Das ewige Problem der heutigen Datenflut ist, dass so viele Daten unnötig sind. Nehmen Sie ein medizinisches Überwachungsgerät - nur die Problemdaten sind wichtig, und es macht wenig Sinn, tagelang normale Patientendaten zu speichern. Bei den meisten Daten, die für Echtzeitanalysen benötigt werden, handelt es sich um kurzfristige Daten, die nicht langfristig aufbewahrt werden. Ein Unternehmen muss entscheiden, welche Daten es aufbewahrt und welche es nach der Durchführung von Analysen verwirft. Und die Daten, die aufbewahrt werden, müssen in Übereinstimmung mit den Unternehmens- und Regulierungsrichtlinien geschützt werden.
Implementierung von Edge Computing
Edge Computing ist eine unkomplizierte Idee, die auf dem Papier einfach aussieht, aber die Entwicklung einer kohärenten Strategie und die Implementierung einer soliden Edge-Implementierung kann eine Herausforderung darstellen.
Das erste wichtige Element jeder erfolgreichen Technologieimplementierung ist die Entwicklung einer sinnvollen geschäftlichen und technischen Edge-Strategie. Bei einer solchen Strategie geht es nicht um die Auswahl von Anbietern oder Geräten. Vielmehr geht es bei einer Edge-Strategie darum, den Bedarf an Edge Computing zu ermitteln. Um das „Warum“ zu verstehen, ist ein klares Verständnis der technischen und geschäftlichen Probleme erforderlich, die das Unternehmen zu lösen versucht, zum Beispiel die Überwindung von Netzwerkbeschränkungen und die Wahrung der Datenhoheit.

Solche Strategien könnten mit einer Diskussion darüber beginnen, was Edge bedeutet, wo es für das Unternehmen existiert und welchen Nutzen es für das Unternehmen haben soll. Edge-Strategien sollten auch mit bestehenden Geschäftsplänen und Technologie-Roadmaps in Einklang gebracht werden. Wenn das Unternehmen zum Beispiel die Anzahl der zentralen Rechenzentren reduzieren möchte, können Edge- und andere verteilte Rechentechnologien gut miteinander harmonieren.
Je näher das Projekt der Implementierung kommt, desto sorgfältiger müssen die Hardware- und Softwareoptionen bewertet werden. Es gibt viele Anbieter im Bereich des Edge-Computing, darunter Adlink Technology, Cisco, Amazon, Dell EMC und HPE. Jedes Produktangebot muss auf Kosten, Leistung, Funktionen, Interoperabilität und Support geprüft werden. Aus der Software-Perspektive sollten die Tools umfassende Sichtbarkeit und Kontrolle über die Remote-Edge-Umgebung bieten.
Der tatsächliche Einsatz einer Edge-Computing-Initiative kann in Umfang und Größe sehr unterschiedlich sein und reicht von einigen lokalen Rechenanlagen in einem robusten Gehäuse auf dem Dach eines Versorgungsunternehmens bis hin zu einem riesigen Array von Sensoren, die eine Netzwerkverbindung mit hoher Bandbreite und niedriger Latenz mit der Public Cloud verbinden. Keine zwei Edge-Implementierungen sind gleich. Genau diese Unterschiede machen die Edge-Strategie und -Planung so entscheidend für den Erfolg eines Edge-Projekts.
Ein Edge-Einsatz erfordert eine umfassende Überwachung. Denken Sie daran, dass es schwierig - oder sogar unmöglich - sein kann, IT-Mitarbeiter an den physischen Edge-Standort zu bringen. Überwachungs-Tools müssen einen klaren Überblick über die Remote-Bereitstellung bieten, eine einfache Bereitstellung und Konfiguration ermöglichen, umfassende Warnmeldungen und Berichte liefern und die Sicherheit der Installation und ihrer Daten gewährleisten. Die Edge-Überwachung umfasst oft eine Reihe von Metriken und KPIs, wie zum Beispiel die Verfügbarkeit oder Betriebszeit des Standorts, die Netzwerkleistung, die Speicherkapazität und -nutzung sowie die Rechenressourcen.
Und keine Edge-Implementierung wäre vollständig ohne eine sorgfältige Betrachtung der Edge-Wartung:
- Physische und logische Sicherheitsvorkehrungen sind unerlässlich und sollten Tools umfassen, die den Schwerpunkt auf Schwachstellenmanagement und Intrusion Detection and Prevention legen. Die Sicherheit muss sich auch auf Sensor- und IoT-Geräte erstrecken, da jedes Gerät ein Netzwerkelement ist, auf das zugegriffen oder das gehackt werden kann - was eine verwirrende Anzahl möglicher Angriffsflächen darstellt.
- Konnektivität. Konnektivität ist ein weiteres Thema, und es müssen Vorkehrungen für den Zugriff auf Steuerung und Berichterstattung getroffen werden, auch wenn die Konnektivität für die eigentlichen Daten nicht verfügbar ist. Einige Edge-Implementierungen verwenden eine sekundäre Verbindung für Backup-Konnektivität und Kontrolle.
- Die abgelegenen und oft unwirtlichen Standorte von Edge-Implementierungen machen eine Fernbereitstellung und -verwaltung unerlässlich. IT-Manager müssen in der Lage sein, zu sehen, was am Edge passiert, und die Bereitstellung bei Bedarf steuern.
- Physische Wartung. Die Anforderungen an die physische Wartung dürfen nicht außer Acht gelassen werden. IoT-Geräte haben oft eine begrenzte Lebensdauer und müssen regelmäßig ausgetauscht werden. Geräte fallen aus und müssen schließlich gewartet und ersetzt werden. Die praktische Standortlogistik muss bei der Wartung berücksichtigt werden.
Edge Computing, IoT und 5G-Möglichkeiten
Edge Computing entwickelt sich ständig weiter und nutzt neue Technologien und Praktiken, um Fähigkeiten und Leistung zu verbessern. Der vielleicht bemerkenswerteste Trend ist die Edge-Verfügbarkeit, und es wird erwartet, dass Edge-Dienste bis 2028 weltweit verfügbar sein werden. Während Edge Computing heute oft situationsabhängig ist, wird erwartet, dass die Technologie allgegenwärtiger wird und die Art und Weise, wie das Internet genutzt wird, verändert, was zu mehr Abstraktion und potenziellen Anwendungsfällen für Edge-Technologie führt.
Dies zeigt sich in der zunehmenden Verbreitung von Rechen-, Speicher- und Netzwerkgeräten, die speziell für Edge Computing entwickelt wurden. Mehr herstellerübergreifende Partnerschaften werden eine bessere Interoperabilität und Flexibilität der Produkte am Rande des Netzwerks ermöglichen. Ein Beispiel hierfür ist die Partnerschaft zwischen AWSund Verizon, die eine bessere Konnektivität am Netzwerkrand ermöglicht.
Drahtlose Kommunikationstechnologien wie 5G und Wi-Fi 6 werden sich in den kommenden Jahren auch auf die Edge-Bereitstellung und -Nutzung auswirken. Sie ermöglichen Virtualisierungs- und Automatisierungsfunktionen, die bisher noch nicht erforscht wurden, wie zum Beispiel eine bessere Fahrzeugautonomie und die Verlagerung von Arbeitslasten an das Edge, und machen drahtlose Netzwerke flexibler und kostengünstiger.
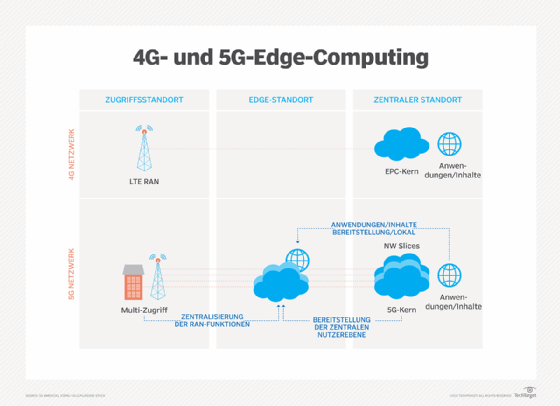
Edge Computing wurde mit dem Aufkommen von IoT und der plötzlichen Datenflut, die solche Geräte produzieren, bekannt. Da die IoT-Technologien jedoch noch in den Kinderschuhen stecken, wird sich die Entwicklung der IoT-Geräte auch auf die zukünftige Entwicklung des Edge Computing auswirken. Ein Beispiel für solche zukünftigen Alternativen ist die Entwicklung von mikro-modularen Datenzentren (MMDCs). Das MMDC ist im Grunde ein Rechenzentrum in einer Box, das ein komplettes Rechenzentrum in einem kleinen mobilen System unterbringt, das näher an den Daten - etwa in einer Stadt oder Region - eingesetzt werden kann, um die Datenverarbeitung näher an die Daten heranzubringen, ohne ein Edge an die Daten selbst zu legen.






